 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Regularized Adversarial Learning for Multi-Domain Text Classification
Jan 30, 2022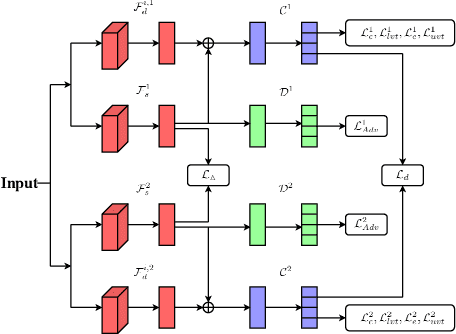

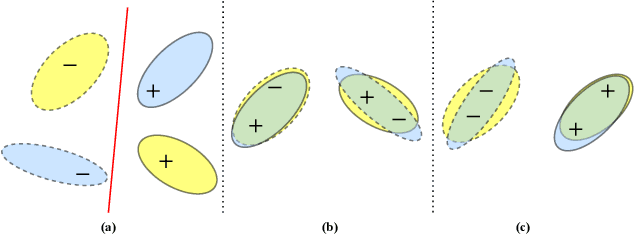
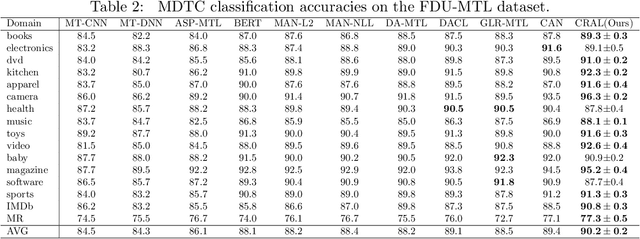
Multi-domain text classification (MDTC) aims to leverage all available resources from multiple domains to learn a predictive model that can generalize well on these domains. Recently, many MDTC methods adopt adversarial learning, shared-private paradigm, and entropy minimization to yield state-of-the-art results. However, these approaches face three issues: (1) Minimizing domain divergence can not fully guarantee the success of domain alignment; (2) Aligning marginal feature distributions can not fully guarantee the discriminability of the learned features; (3) Standard entropy minimization may make the predictions on unlabeled data over-confident, deteriorating the discriminability of the learned features. In order to address the above issues, we propose a co-regularized adversarial learning (CRAL) mechanism for MDTC. This approach constructs two diverse shared latent spaces, performs domain alignment in each of them, and punishes the disagreements of these two alignments with respect to the predictions on unlabeled data. Moreover, virtual adversarial training (VAT) with entropy minimization is incorporated to impose consistency regularization to the CRAL method. Experiments show that our model outperforms state-of-the-art methods on two MDTC benchmarks.
Maximum Batch Frobenius Norm for Multi-Domain Text Classification
Jan 29, 2022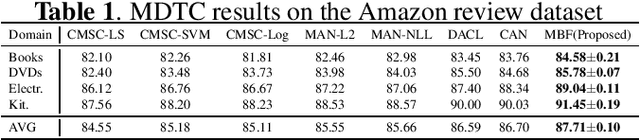
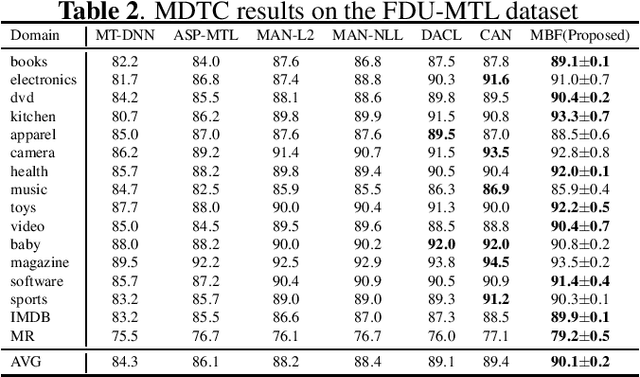
Multi-domain text classification (MDTC) has obtained remarkable achievements due to the advent of deep learning. Recently, many endeavors are devoted to applying adversarial learning to extract domain-invariant features to yield state-of-the-art results. However, these methods still face one challenge: transforming original features to be domain-invariant distorts the distributions of the original features, degrading the discriminability of the learned features. To address this issue, we first investigate the structure of the batch classification output matrix and theoretically justify that the discriminability of the learned features has a positive correlation with the Frobenius norm of the batch output matrix. Based on this finding, we propose a maximum batch Frobenius norm (MBF) method to boost the feature discriminability for MDTC. Experiments on two MDTC benchmarks show that our MBF approach can effectively advance the performance of the state-of-the-art.
Towards Category and Domain Alignment: Category-Invariant Feature Enhancement for Adversarial Domain Adaptation
Aug 14, 2021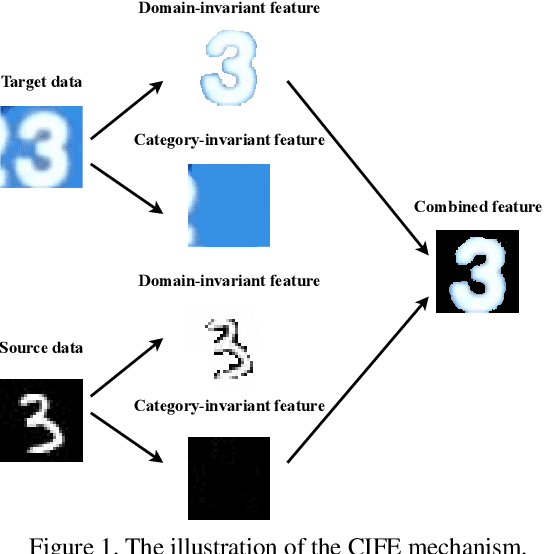
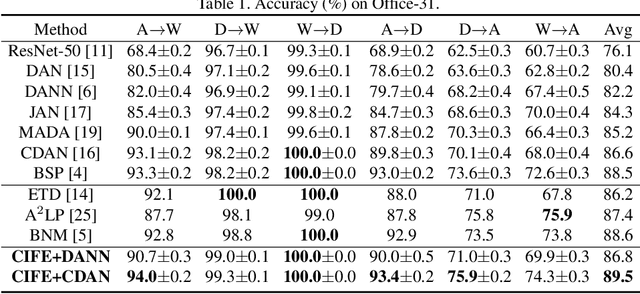
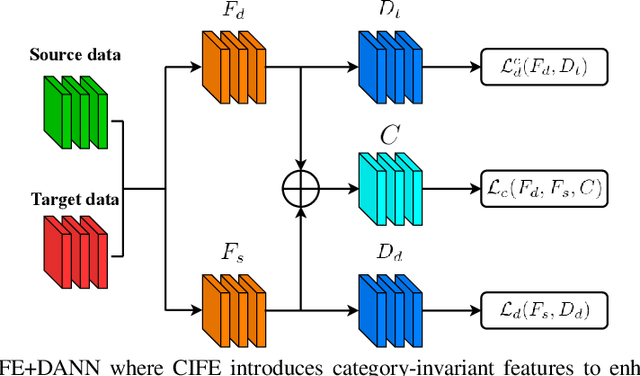
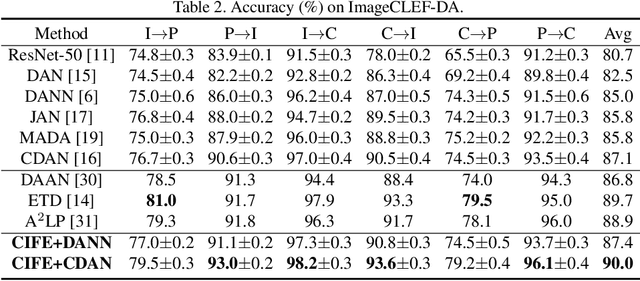
Adversarial domain adaptation has made impressive advances in transferring knowledge from the source domain to the target domain by aligning feature distributions of both domains. These methods focus on minimizing domain divergence and regard the adaptability, which is measured as the expected error of the ideal joint hypothesis on these two domains, as a small constant. However, these approaches still face two issues: (1) Adversarial domain alignment distorts the original feature distributions, deteriorating the adaptability; (2) Transforming feature representations to be domain-invariant needs to sacrifice domain-specific variations, resulting in weaker discriminability. In order to alleviate these issues, we propose category-invariant feature enhancement (CIFE), a general mechanism that enhances the adversarial domain adaptation through optimizing the adaptability. Specifically, the CIFE approach introduces category-invariant features to boost the discriminability of domain-invariant features with preserving the transferability. Experiments show that the CIFE could improve upon representative adversarial domain adaptation methods to yield state-of-the-art results on five benchmarks.
CBench: Towards Better Evaluation of Question Answering Over Knowledge Graphs
Apr 05, 2021
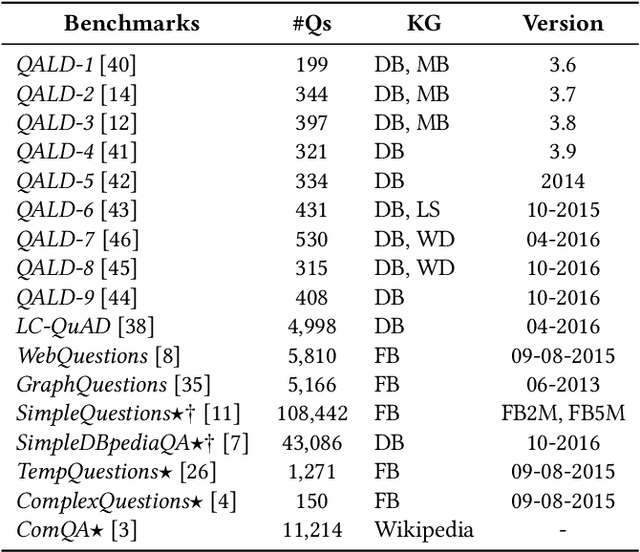
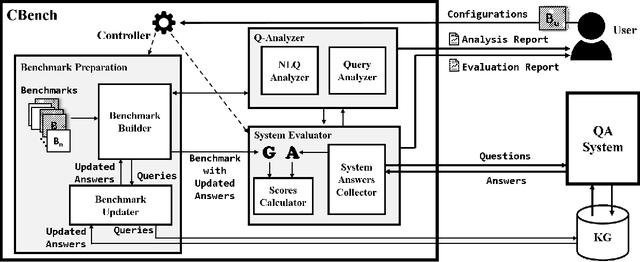
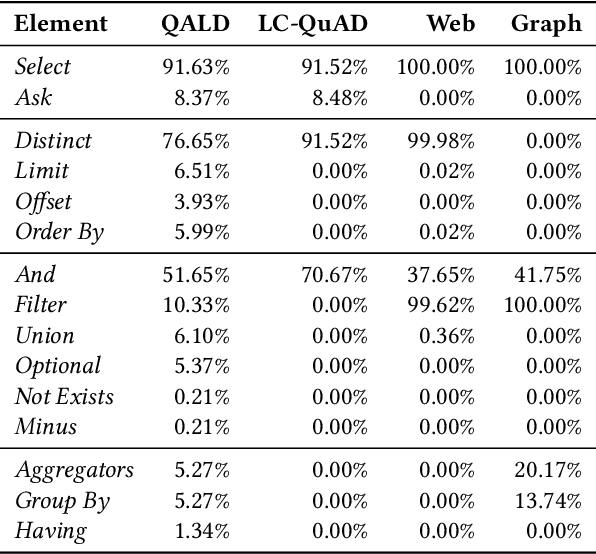
Recently, there has been an increase in the number of knowledge graphs that can be only queried by experts. However, describing questions using structured queries is not straightforward for non-expert users who need to have sufficient knowledge about both the vocabulary and the structure of the queried knowledge graph, as well as the syntax of the structured query language used to describe the user's information needs. The most popular approach introduced to overcome the aforementioned challenges is to use natural language to query these knowledge graphs. Although several question answering benchmarks can be used to evaluate question-answering systems over a number of popular knowledge graphs, choosing a benchmark to accurately assess the quality of a question answering system is a challenging task. In this paper, we introduce CBench, an extensible, and more informative benchmarking suite for analyzing benchmarks and evaluating question answering systems. CBench can be used to analyze existing benchmarks with respect to several fine-grained linguistic, syntactic, and structural properties of the questions and queries in the benchmark. We show that existing benchmarks vary significantly with respect to these properties deeming choosing a small subset of them unreliable in evaluating QA systems. Until further research improves the quality and comprehensiveness of benchmarks, CBench can be used to facilitate this evaluation using a set of popular benchmarks that can be augmented with other user-provided benchmarks. CBench not only evaluates a question answering system based on popular single-number metrics but also gives a detailed analysis of the linguistic, syntactic, and structural properties of answered and unanswered questions to better help the developers of question answering systems to better understand where their system excels and where it struggles.
Conditional Adversarial Networks for Multi-Domain Text Classification
Feb 19, 2021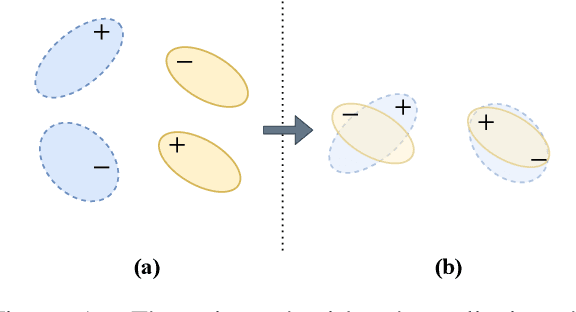

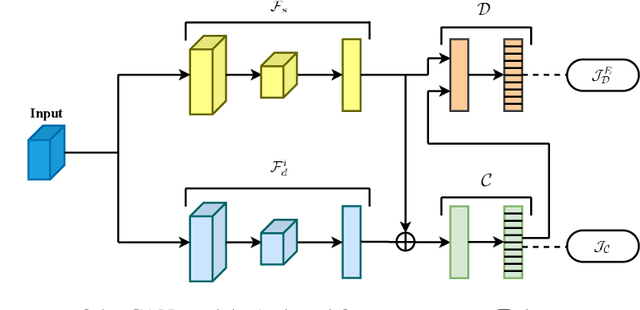
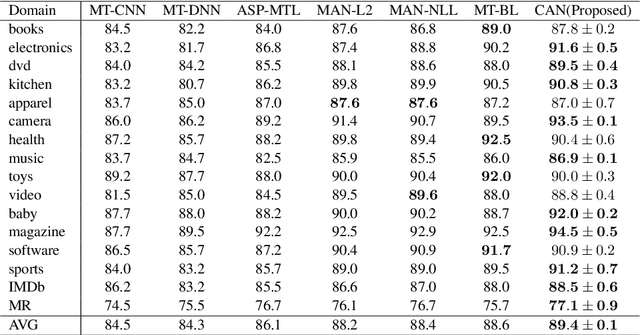
In this paper, we propose conditional adversarial networks (CANs), a framework that explores the relationship between the shared features and the label predictions to impose more discriminability to the shared features, for multi-domain text classification (MDTC). The proposed CAN introduces a conditional domain discriminator to model the domain variance in both shared feature representations and class-aware information simultaneously and adopts entropy conditioning to guarantee the transferability of the shared features. We provide theoretical analysis for the CAN framework, showing that CAN's objective is equivalent to minimizing the total divergence among multiple joint distributions of shared features and label predictions. Therefore, CAN is a theoretically sound adversarial network that discriminates over multiple distributions. Evaluation results on two MDTC benchmarks show that CAN outperforms prior methods. Further experiments demonstrate that CAN has a good ability to generalize learned knowledge to unseen domains.
Mixup Regularized Adversarial Networks for Multi-Domain Text Classification
Jan 31, 2021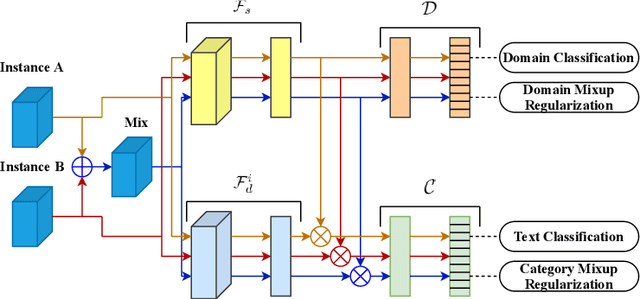
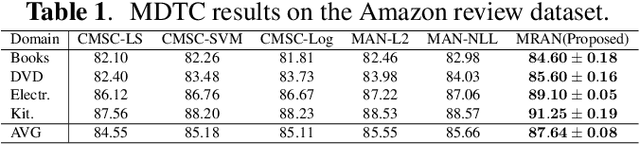
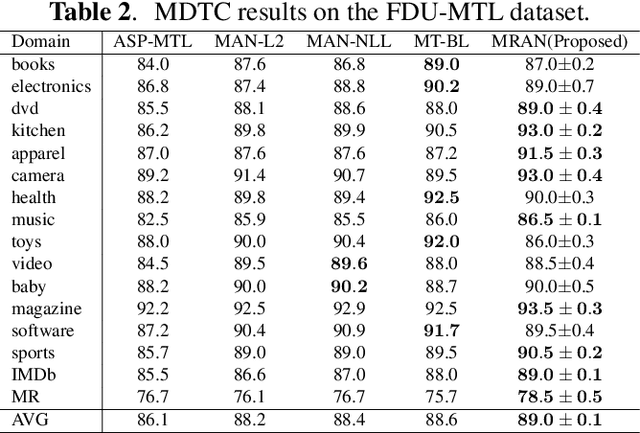
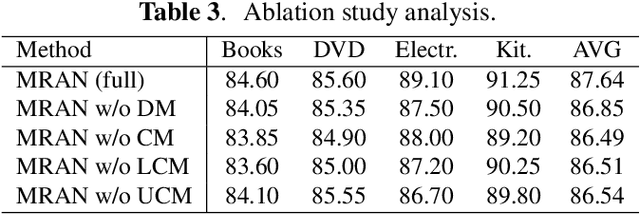
Using the shared-private paradigm and adversarial training has significantly improved the performances of multi-domain text classification (MDTC) models. However, there are two issues for the existing methods. First, instances from the multiple domains are not sufficient for domain-invariant feature extraction. Second, aligning on the marginal distributions may lead to fatal mismatching. In this paper, we propose a mixup regularized adversarial network (MRAN) to address these two issues. More specifically, the domain and category mixup regularizations are introduced to enrich the intrinsic features in the shared latent space and enforce consistent predictions in-between training instances such that the learned features can be more domain-invariant and discriminative. We conduct experiments on two benchmarks: The Amazon review dataset and the FDU-MTL dataset. Our approach on these two datasets yields average accuracies of 87.64\% and 89.0\% respectively, outperforming all relevant baselines.
Dual Mixup Regularized Learning for Adversarial Domain Adaptation
Jul 16, 2020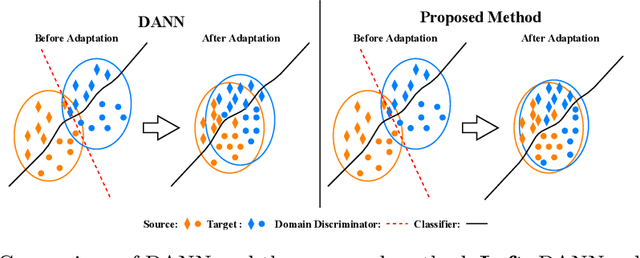
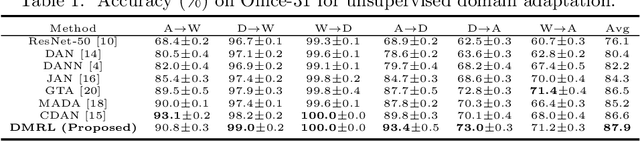
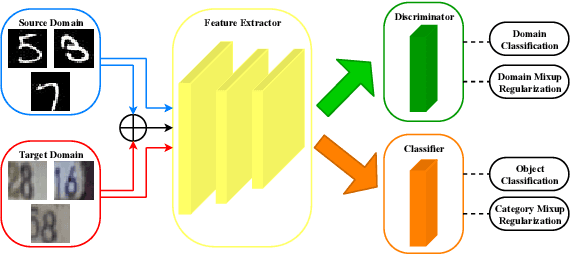
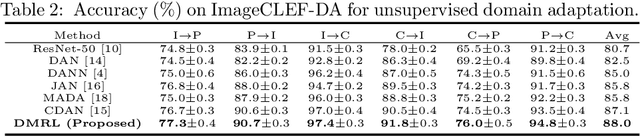
Recent advances on unsupervised domain adaptation (UDA) rely on adversarial learning to disentangle the explanatory and transferable features for domain adaptation. However, there are two issues with the existing methods. First, the discriminability of the latent space cannot be fully guaranteed without considering the class-aware information in the target domain. Second, samples from the source and target domains alone are not sufficient for domain-invariant feature extracting in the latent space. In order to alleviate the above issues, we propose a dual mixup regularized learning (DMRL) method for UDA, which not only guides the classifier in enhancing consistent predictions in-between samples, but also enriches the intrinsic structures of the latent space. The DMRL jointly conducts category and domain mixup regularizations on pixel level to improve the effectiveness of models. A series of empirical studies on four domain adaptation benchmarks demonstrate that our approach can achieve the state-of-the-art.