 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixup Regularized Adversarial Networks for Multi-Domain Text Classification
Paper and Code
Jan 31, 2021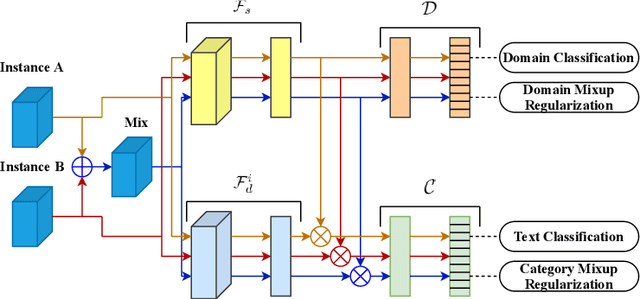
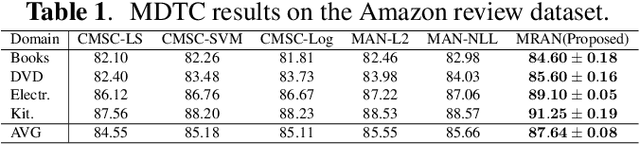
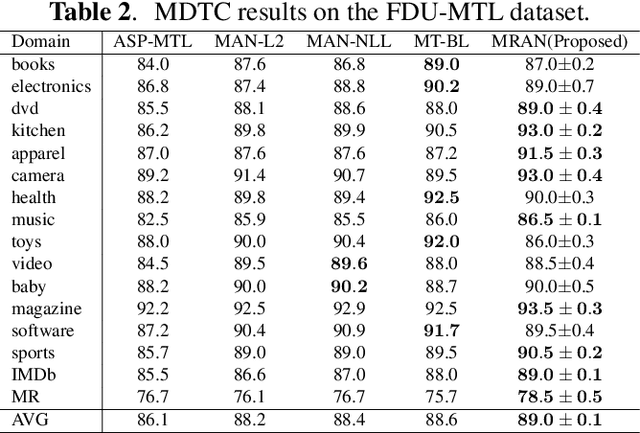
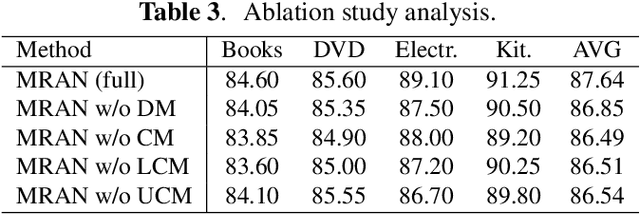
Using the shared-private paradigm and adversarial training has significantly improved the performances of multi-domain text classification (MDTC) models. However, there are two issues for the existing methods. First, instances from the multiple domains are not sufficient for domain-invariant feature extraction. Second, aligning on the marginal distributions may lead to fatal mismatching. In this paper, we propose a mixup regularized adversarial network (MRAN) to address these two issues. More specifically, the domain and category mixup regularizations are introduced to enrich the intrinsic features in the shared latent space and enforce consistent predictions in-between training instances such that the learned features can be more domain-invariant and discriminative. We conduct experiments on two benchmarks: The Amazon review dataset and the FDU-MTL dataset. Our approach on these two datasets yields average accuracies of 87.64\% and 89.0\% respectively, outperforming all relevant baselines.