 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multi-Agent LLM Frameworks: A Unified Benchmark and Experimental Analysis
Feb 03, 2026Multi-agent LLM frameworks are widely used to accelerate the development of agent systems powered by large language models (LLMs). These frameworks impose distinct architectural structures that govern how agents interact, store information, and coordinate tasks. However, their impact on system performance remains poorly understood. This gap is critical, as architectural choices alone can induce order-of-magnitude differences in latency and throughput, as well as substantial variation in accuracy and scalability. Addressing this challenge requires (i) jointly evaluating multiple capabilities, such as orchestration overhead, memory behavior, planning, specialization, and coordination, and (ii) conducting these evaluations under controlled, framework-level conditions to isolate architectural effects. Existing benchmarks focus on individual capabilities and lack standardized framework-level evaluation. We address these limitations by (i) introducing an architectural taxonomy for systematically comparing multi-agent LLM frameworks along fundamental dimensions, and (ii) developing MAFBench, a unified evaluation suite that integrates existing benchmarks under a standardized execution pipeline. Using MAFBench, we conduct a controlled empirical study across several widely used frameworks. Our results show that framework-level design choices alone can increase latency by over 100x, reduce planning accuracy by up to 30%, and lower coordination success from above 90% to below 30%. Finally, we translate our findings into concrete architectural design principles and framework selection guidance, and outline promising future research directions.
CBench: Towards Better Evaluation of Question Answering Over Knowledge Graphs
Apr 05, 2021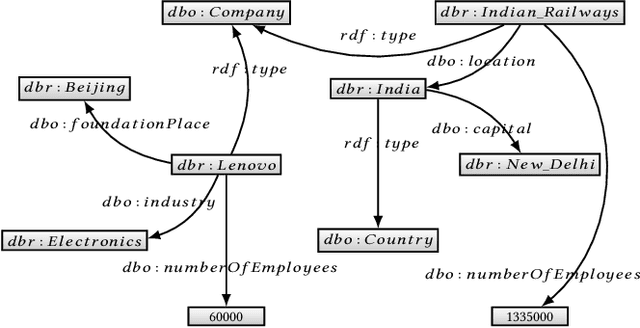
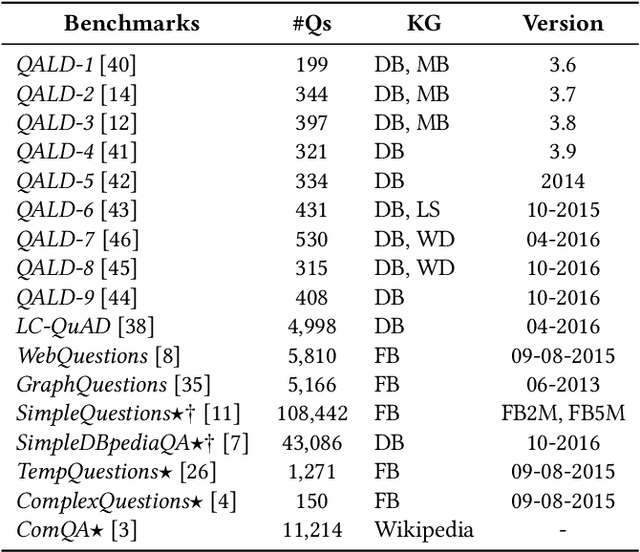
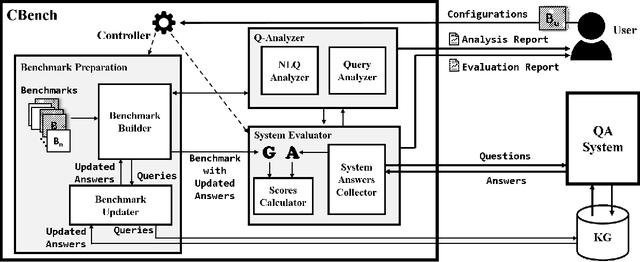
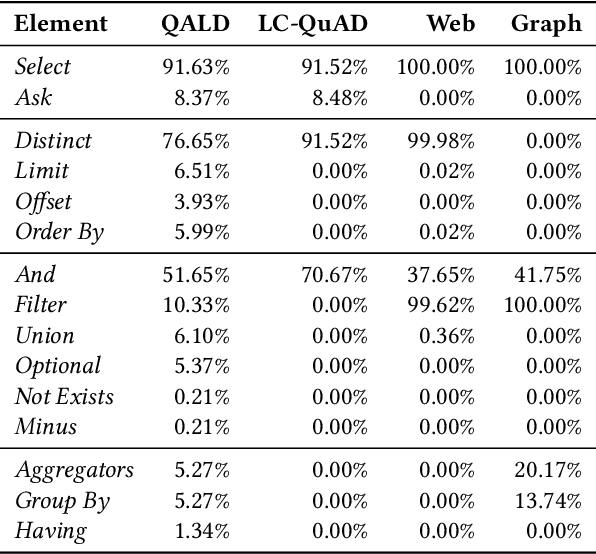
Recently, there has been an increase in the number of knowledge graphs that can be only queried by experts. However, describing questions using structured queries is not straightforward for non-expert users who need to have sufficient knowledge about both the vocabulary and the structure of the queried knowledge graph, as well as the syntax of the structured query language used to describe the user's information needs. The most popular approach introduced to overcome the aforementioned challenges is to use natural language to query these knowledge graphs. Although several question answering benchmarks can be used to evaluate question-answering systems over a number of popular knowledge graphs, choosing a benchmark to accurately assess the quality of a question answering system is a challenging task. In this paper, we introduce CBench, an extensible, and more informative benchmarking suite for analyzing benchmarks and evaluating question answering systems. CBench can be used to analyze existing benchmarks with respect to several fine-grained linguistic, syntactic, and structural properties of the questions and queries in the benchmark. We show that existing benchmarks vary significantly with respect to these properties deeming choosing a small subset of them unreliable in evaluating QA systems. Until further research improves the quality and comprehensiveness of benchmarks, CBench can be used to facilitate this evaluation using a set of popular benchmarks that can be augmented with other user-provided benchmarks. CBench not only evaluates a question answering system based on popular single-number metrics but also gives a detailed analysis of the linguistic, syntactic, and structural properties of answered and unanswered questions to better help the developers of question answering systems to better understand where their system excels and where it struggles.