 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Agent Memory a Database? Rethinking Data Foundations for Long-Term AI Agent Memory
May 25, 2026Long-running AI agents need persistent memory. Memory supports learning across sessions, reduces repeated context injection, and enables auditing of past decisions. Current agent memory systems and database paradigms treat memory as storage. They localize correctness at records, embeddings, or edges. Each supplies only some of the capabilities that long-term memory requires. The result is four recurring failure modes: unregulated growth, missing semantic revision, capacity-driven forgetting, and read-only retrieval. In our vision, long-term agent memory is a new data-management workload. Its correctness is a property of the state trajectory, not of individual records. We formalize this as Governed Evolving Memory (GEM). GEM replaces record-level database operations with four state-level operators: ingestion, revision, forgetting, and retrieval. Six correctness conditions govern how the state evolves. Three structural observations establish that no record-level system can satisfy these conditions, regardless of the storage model. We realize the abstraction in MemState, a prototype on a property-graph backend. MemState validates feasibility and exposes the gap to a native engine. We outline three research directions that define memory-centric data management as a workload.
Leveraging LLM-GNN Integration for Open-World Question Answering over Knowledge Graphs
Apr 15, 2026Open-world Question Answering (OW-QA) over knowledge graphs (KGs) aims to answer questions over incomplete or evolving KGs. Traditional KGQA assumes a closed world where answers must exist in the KG, limiting real-world applicability. In contrast, open-world QA requires inferring missing knowledge based on graph structure and context. Large language models (LLMs) excel at language understanding but lack structured reasoning. Graph neural networks (GNNs) model graph topology but struggle with semantic interpretation. Existing systems integrate LLMs with GNNs or graph retrievers. Some support open-world QA but rely on structural embeddings without semantic grounding. Most assume observed paths or complete graphs, making them unreliable under missing links or multi-hop reasoning. We present GLOW, a hybrid system that combines a pre-trained GNN and an LLM for open-world KGQA. The GNN predicts top-k candidate answers from the graph structure. These, along with relevant KG facts, are serialized into a structured prompt (e.g., triples and candidates) to guide the LLM's reasoning. This enables joint reasoning over symbolic and semantic signals, without relying on retrieval or fine-tuning. To evaluate generalization, we introduce GLOW-BENCH, a 1,000-question benchmark over incomplete KGs across diverse domains. GLOW outperforms existing LLM-GNN systems on standard benchmarks and GLOW-BENCH, achieving up to 53.3% and an average 38% improvement. GitHub code and data are available.
An LLM-Guided Query-Aware Inference System for GNN Models on Large Knowledge Graphs
Mar 04, 2026Efficient inference for graph neural networks (GNNs) on large knowledge graphs (KGs) is essential for many real-world applications. GNN inference queries are computationally expensive and vary in complexity, as each involves a different number of target nodes linked to subgraphs of diverse densities and structures. Existing acceleration methods, such as pruning, quantization, and knowledge distillation, instantiate smaller models but do not adapt them to the structure or semantics of individual queries. They also store models as monolithic files that must be fully loaded, and miss the opportunity to retrieve only the neighboring nodes and corresponding model components that are semantically relevant to the target nodes. These limitations lead to excessive data loading and redundant computation on large KGs. This paper presents KG-WISE, a task-driven inference paradigm for large KGs. KG-WISE decomposes trained GNN models into fine-grained components that can be partially loaded based on the structure of the queried subgraph. It employs large language models (LLMs) to generate reusable query templates that extract semantically relevant subgraphs for each task, enabling query-aware and compact model instantiation. We evaluate KG-WISE on six large KGs with up to 42 million nodes and 166 million edges. KG-WISE achieves up to 28x faster inference and 98% lower memory usage than state-of-the-art systems while maintaining or improving accuracy across both commercial and open-weight LLMs.
Understanding Multi-Agent LLM Frameworks: A Unified Benchmark and Experimental Analysis
Feb 03, 2026Multi-agent LLM frameworks are widely used to accelerate the development of agent systems powered by large language models (LLMs). These frameworks impose distinct architectural structures that govern how agents interact, store information, and coordinate tasks. However, their impact on system performance remains poorly understood. This gap is critical, as architectural choices alone can induce order-of-magnitude differences in latency and throughput, as well as substantial variation in accuracy and scalability. Addressing this challenge requires (i) jointly evaluating multiple capabilities, such as orchestration overhead, memory behavior, planning, specialization, and coordination, and (ii) conducting these evaluations under controlled, framework-level conditions to isolate architectural effects. Existing benchmarks focus on individual capabilities and lack standardized framework-level evaluation. We address these limitations by (i) introducing an architectural taxonomy for systematically comparing multi-agent LLM frameworks along fundamental dimensions, and (ii) developing MAFBench, a unified evaluation suite that integrates existing benchmarks under a standardized execution pipeline. Using MAFBench, we conduct a controlled empirical study across several widely used frameworks. Our results show that framework-level design choices alone can increase latency by over 100x, reduce planning accuracy by up to 30%, and lower coordination success from above 90% to below 30%. Finally, we translate our findings into concrete architectural design principles and framework selection guidance, and outline promising future research directions.
Task-Oriented GNNs Training on Large Knowledge Graphs for Accurate and Efficient Modeling
Mar 09, 2024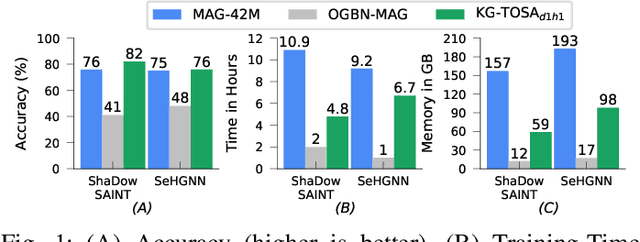
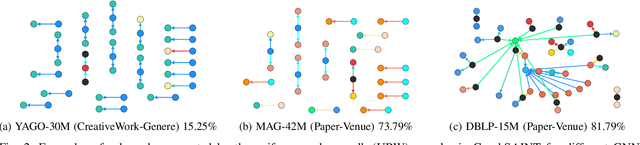
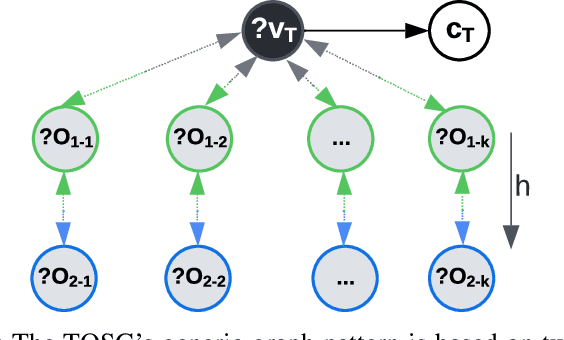
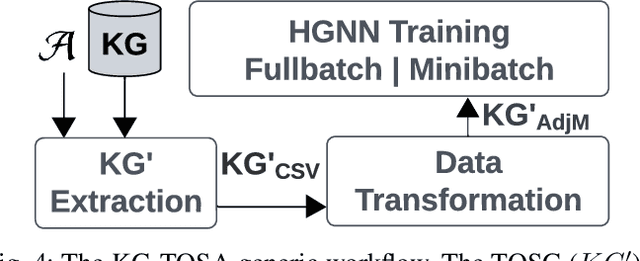
A Knowledge Graph (KG) is a heterogeneous graph encompassing a diverse range of node and edge types. Heterogeneous Graph Neural Networks (HGNNs) are popular for training machine learning tasks like node classification and link prediction on KGs. However, HGNN methods exhibit excessive complexity influenced by the KG's size, density, and the number of node and edge types. AI practitioners handcraft a subgraph of a KG G relevant to a specific task. We refer to this subgraph as a task-oriented subgraph (TOSG), which contains a subset of task-related node and edge types in G. Training the task using TOSG instead of G alleviates the excessive computation required for a large KG. Crafting the TOSG demands a deep understanding of the KG's structure and the task's objectives. Hence, it is challenging and time-consuming. This paper proposes KG-TOSA, an approach to automate the TOSG extraction for task-oriented HGNN training on a large KG. In KG-TOSA, we define a generic graph pattern that captures the KG's local and global structure relevant to a specific task. We explore different techniques to extract subgraphs matching our graph pattern: namely (i) two techniques sampling around targeted nodes using biased random walk or influence scores, and (ii) a SPARQL-based extraction method leveraging RDF engines' built-in indices. Hence, it achieves negligible preprocessing overhead compared to the sampling techniques. We develop a benchmark of real KGs of large sizes and various tasks for node classification and link prediction. Our experiments show that KG-TOSA helps state-of-the-art HGNN methods reduce training time and memory usage by up to 70% while improving the model performance, e.g., accuracy and inference time.
Linked Data Science Powered by Knowledge Graphs
Mar 09, 2023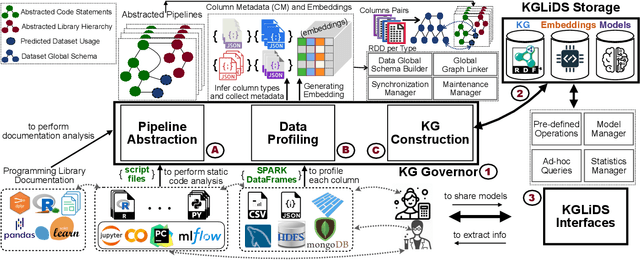
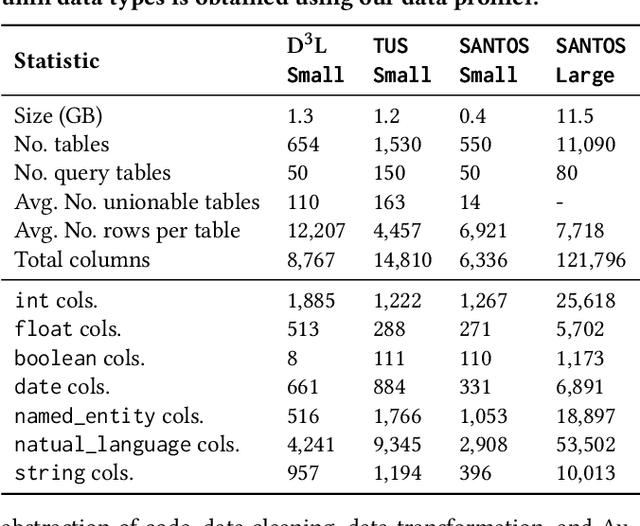
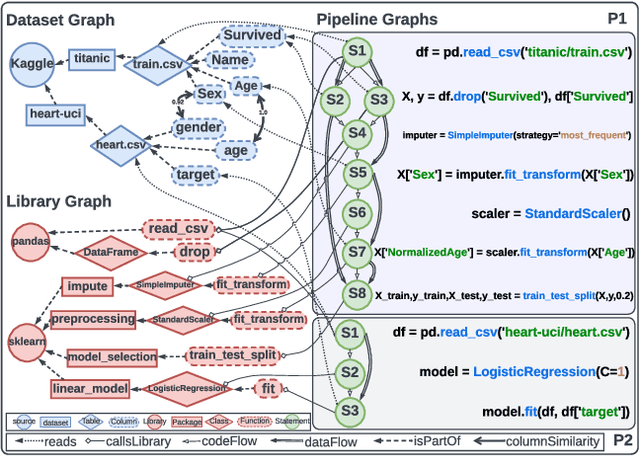
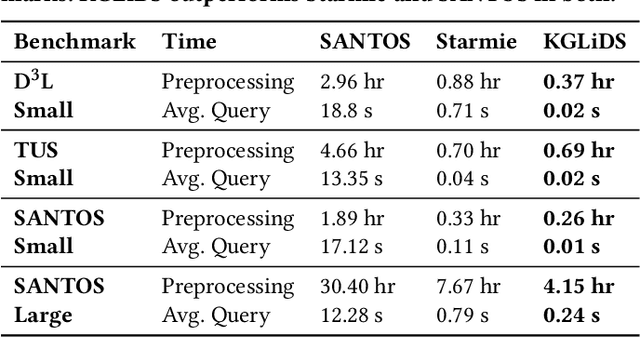
In recent years, we have witnessed a growing interest in data science not only from academia but particularly from companies investing in data science platforms to analyze large amounts of data. In this process, a myriad of data science artifacts, such as datasets and pipeline scripts, are created. Yet, there has so far been no systematic attempt to holistically exploit the collected knowledge and experiences that are implicitly contained in the specification of these pipelines, e.g., compatible datasets, cleansing steps, ML algorithms, parameters, etc. Instead, data scientists still spend a considerable amount of their time trying to recover relevant information and experiences from colleagues, trial and error, lengthy exploration, etc. In this paper, we, therefore, propose a scalable system (KGLiDS) that employs machine learning to extract the semantics of data science pipelines and captures them in a knowledge graph, which can then be exploited to assist data scientists in various ways. This abstraction is the key to enabling Linked Data Science since it allows us to share the essence of pipelines between platforms, companies, and institutions without revealing critical internal information and instead focusing on the semantics of what is being processed and how. Our comprehensive evaluation uses thousands of datasets and more than thirteen thousand pipeline scripts extracted from data discovery benchmarks and the Kaggle portal and shows that KGLiDS significantly outperforms state-of-the-art systems on related tasks, such as dataset recommendation and pipeline classification.
Towards a GML-Enabled Knowledge Graph Platform
Mar 03, 2023



This vision paper proposes KGNet, an on-demand graph machine learning (GML) as a service on top of RDF engines to support GML-enabled SPARQL queries. KGNet automates the training of GML models on a KG by identifying a task-specific subgraph. This helps reduce the task-irrelevant KG structure and properties for better scalability and accuracy. While training a GML model on KG, KGNet collects metadata of trained models in the form of an RDF graph called KGMeta, which is interlinked with the relevant subgraphs in KG. Finally, all trained models are accessible via a SPARQL-like query. We call it a GML-enabled query and refer to it as SPARQLML. KGNet supports SPARQLML on top of existing RDF engines as an interface for querying and inferencing over KGs using GML models. The development of KGNet poses research opportunities in several areas, including meta-sampling for identifying task-specific subgraphs, GML pipeline automation with computational constraints, such as limited time and memory budget, and SPARQLML query optimization. KGNet supports different GML tasks, such as node classification, link prediction, and semantic entity matching. We evaluated KGNet using two real KGs of different application domains. Compared to training on the entire KG, KGNet significantly reduced training time and memory usage while maintaining comparable or improved accuracy. The KGNet source-code is available for further study
* 9 pages, 15 figures, accepted at ICDE 2023
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023



Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.
ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots
Feb 08, 2023


Conversational AI and Question-Answering systems (QASs) for knowledge graphs (KGs) are both emerging research areas: they empower users with natural language interfaces for extracting information easily and effectively. Conversational AI simulates conversations with humans; however, it is limited by the data captured in the training datasets. In contrast, QASs retrieve the most recent information from a KG by understanding and translating the natural language question into a formal query supported by the database engine. In this paper, we present a comprehensive study of the characteristics of the existing alternatives towards combining both worlds into novel KG chatbots. Our framework compares two representative conversational models, ChatGPT and Galactica, against KGQAN, the current state-of-the-art QAS. We conduct a thorough evaluation using four real KGs across various application domains to identify the current limitations of each category of systems. Based on our findings, we propose open research opportunities to empower QASs with chatbot capabilities for KGs. All benchmarks and all raw results are available1 for further analysis.
Serenity: Library Based Python Code Analysis for Code Completion and Automated Machine Learning
Jan 05, 2023
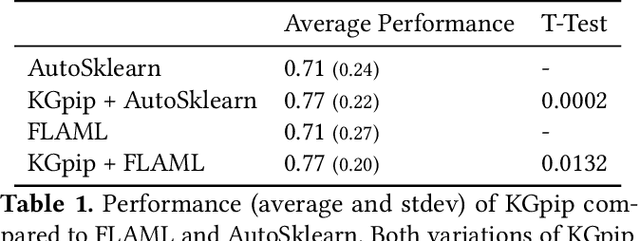

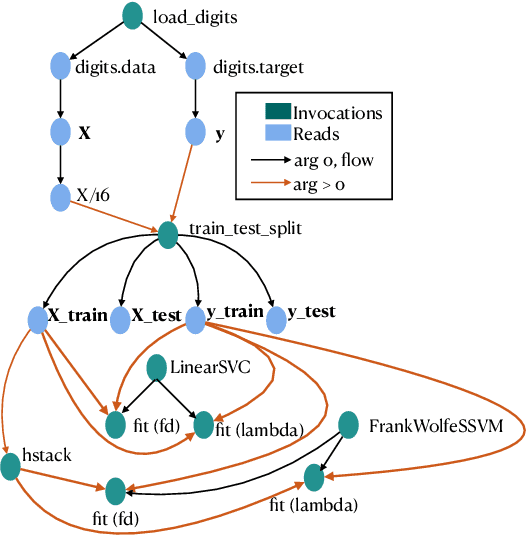
Dynamically typed languages such as Python have become very popular. Among other strengths, Python's dynamic nature and its straightforward linking to native code have made it the de-facto language for many research areas such as Artificial Intelligence. This flexibility, however, makes static analysis very hard. While creating a sound, or a soundy, analysis for Python remains an open problem, we present in this work Serenity, a framework for static analysis of Python that turns out to be sufficient for some tasks. The Serenity framework exploits two basic mechanisms: (a) reliance on dynamic dispatch at the core of language translation, and (b) extreme abstraction of libraries, to generate an abstraction of the code. We demonstrate the efficiency and usefulness of Serenity's analysis in two applications: code completion and automated machine learning. In these two applications, we demonstrate that such analysis has a strong signal, and can be leveraged to establish state-of-the-art performance, comparable to neural models and dynamic analysis respectively.