 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable AutoML Approach Based on Graph Neural Networks
Paper and Code
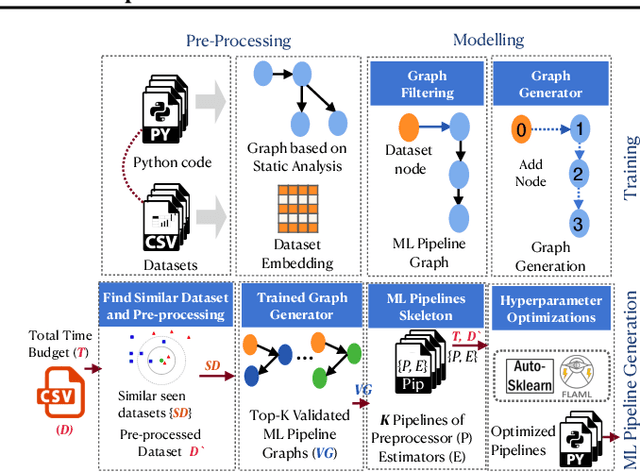
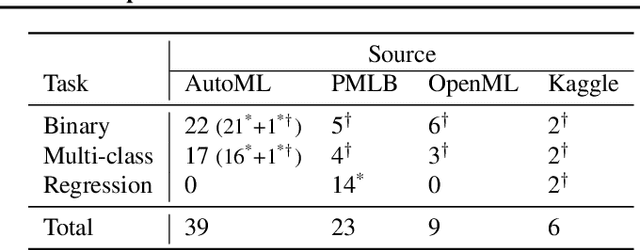

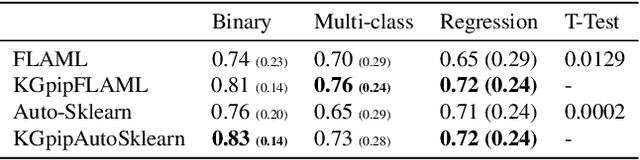
AutoML systems build machine learning models automatically by performing a search over valid data transformations and learners, along with hyper-parameter optimization for each learner. We present a system called KGpip for the selection of transformations and learners, which (1) builds a database of datasets and corresponding historically used pipelines using effective static analysis instead of the typical use of actual runtime information, (2) uses dataset embeddings to find similar datasets in the database based on its content instead of metadata-based features, (3) models AutoML pipeline creation as a graph generation problem, to succinctly characterize the diverse pipelines seen for a single dataset. KGpip is designed as a sub-component for AutoML systems. We demonstrate this ability via integrating KGpip with two AutoML systems and show that it does significantly enhance the performance of existing state-of-the-art systems.