 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBench: Towards Better Evaluation of Question Answering Over Knowledge Graphs
Paper and Code
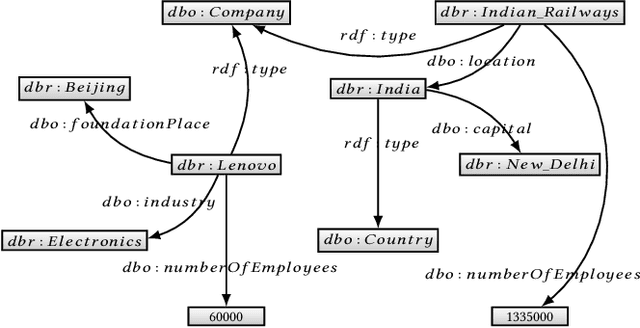
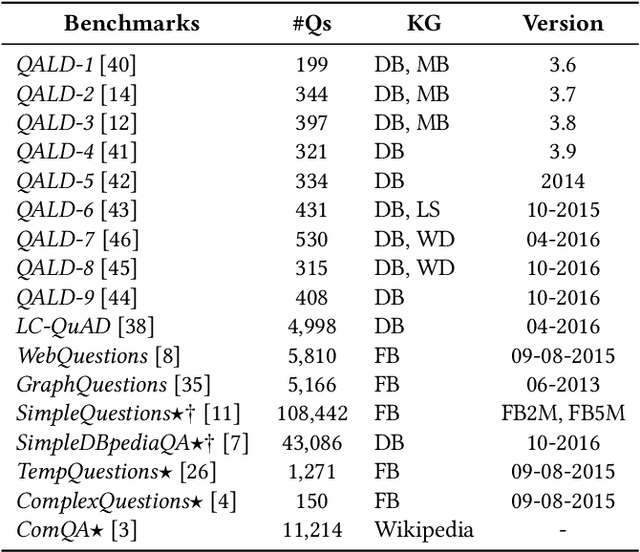
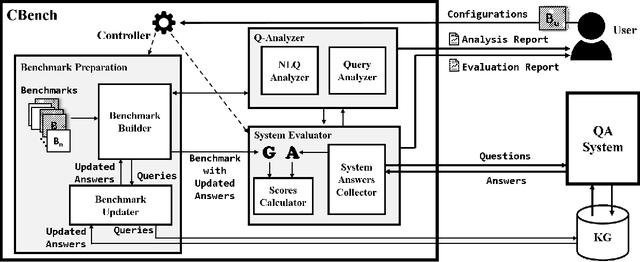
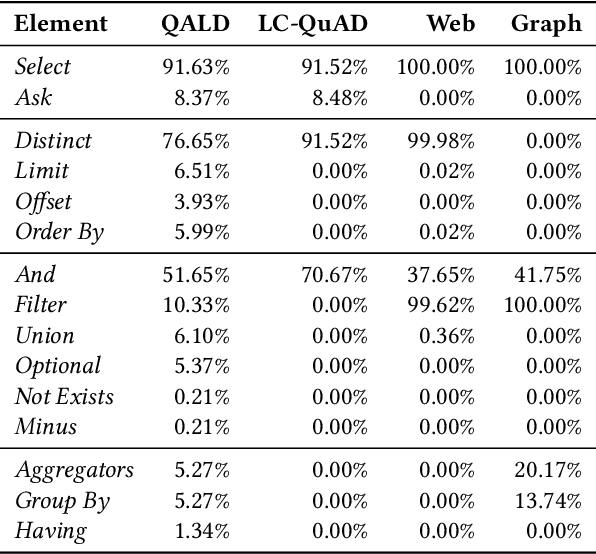
Recently, there has been an increase in the number of knowledge graphs that can be only queried by experts. However, describing questions using structured queries is not straightforward for non-expert users who need to have sufficient knowledge about both the vocabulary and the structure of the queried knowledge graph, as well as the syntax of the structured query language used to describe the user's information needs. The most popular approach introduced to overcome the aforementioned challenges is to use natural language to query these knowledge graphs. Although several question answering benchmarks can be used to evaluate question-answering systems over a number of popular knowledge graphs, choosing a benchmark to accurately assess the quality of a question answering system is a challenging task. In this paper, we introduce CBench, an extensible, and more informative benchmarking suite for analyzing benchmarks and evaluating question answering systems. CBench can be used to analyze existing benchmarks with respect to several fine-grained linguistic, syntactic, and structural properties of the questions and queries in the benchmark. We show that existing benchmarks vary significantly with respect to these properties deeming choosing a small subset of them unreliable in evaluating QA systems. Until further research improves the quality and comprehensiveness of benchmarks, CBench can be used to facilitate this evaluation using a set of popular benchmarks that can be augmented with other user-provided benchmarks. CBench not only evaluates a question answering system based on popular single-number metrics but also gives a detailed analysis of the linguistic, syntactic, and structural properties of answered and unanswered questions to better help the developers of question answering systems to better understand where their system excels and where it struggles.