 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Entropy in Graph Convolutional Neural Networks
Jun 08, 2024Graph Convolutional Networks (GCN) are Graph Neural Networks where the convolutions are applied over a graph. In contrast to Convolutional Neural Networks, GCN's are designed to perform inference on graphs, where the number of nodes can vary, and the nodes are unordered. In this study, we address two important challenges related to GCNs: i) oversmoothing; and ii) the utilization of node relational properties (i.e., heterophily and homophily). Oversmoothing is the degradation of the discriminative capacity of nodes as a result of repeated aggregations. Heterophily is the tendency for nodes of different classes to connect, whereas homophily is the tendency of similar nodes to connect. We propose a new strategy for addressing these challenges in GCNs based on Transfer Entropy (TE), which measures of the amount of directed transfer of information between two time varying nodes. Our findings indicate that using node heterophily and degree information as a node selection mechanism, along with feature-based TE calculations, enhances accuracy across various GCN models. Our model can be easily modified to improve classification accuracy of a GCN model. As a trade off, this performance boost comes with a significant computational overhead when the TE is computed for many graph nodes.
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Apr 03, 2024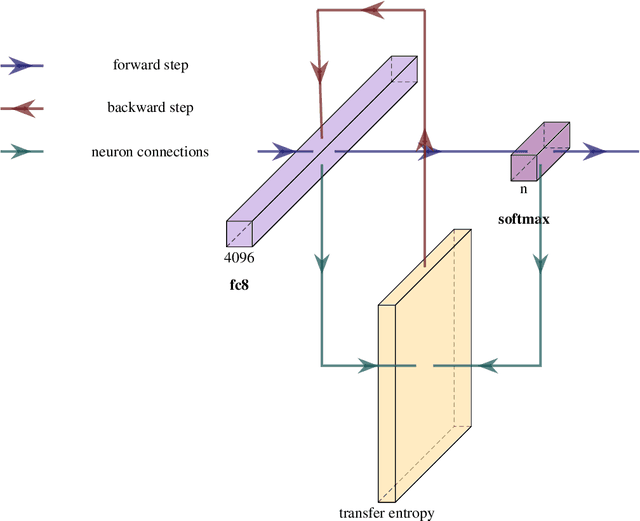
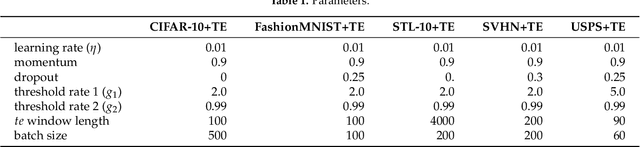
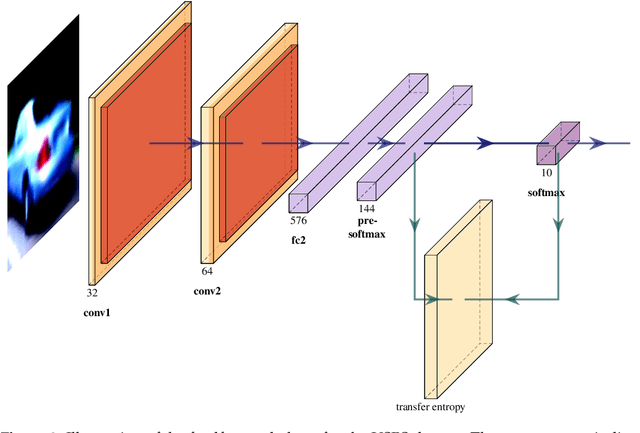

Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
Visual Knowledge Discovery with Artificial Intelligence: Challenges and Future Directions
May 04, 2022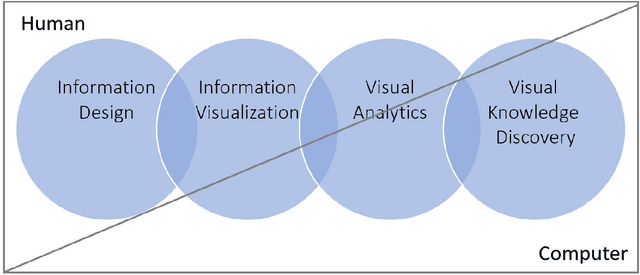
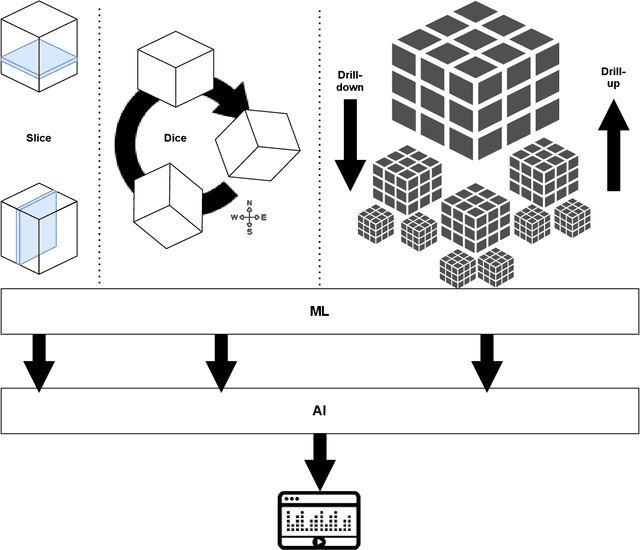
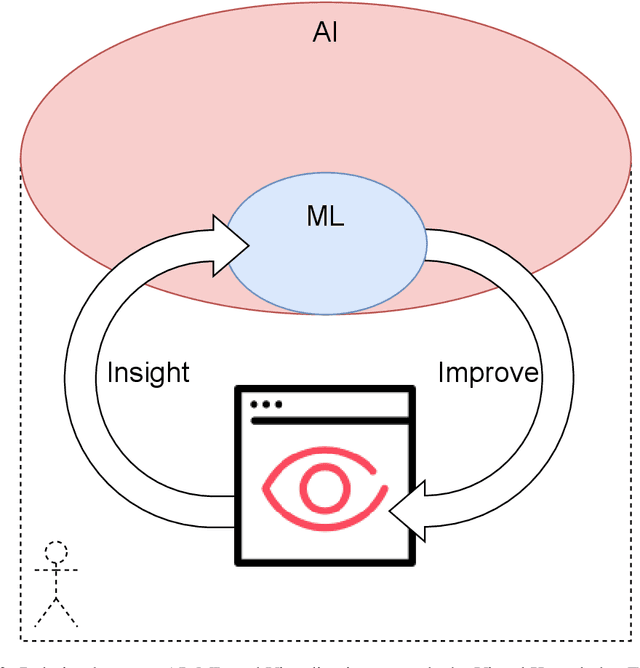
This volume is devoted to the emerging field of Integrated Visual Knowledge Discovery that combines advances in Artificial Intelligence/Machine Learning (AI/ML) and Visualization/Visual Analytics. Chapters included are extended versions of the selected AI and Visual Analytics papers and related symposia at the recent International Information Visualization Conferences (IV2019 and IV2020). AI/ML face a long-standing challenge of explaining models to humans. Models explanation is fundamentally human activity, not only an algorithmic one. In this chapter we aim to present challenges and future directions within the field of Visual Analytics, Visual Knowledge Discovery and AI/ML, and to discuss the role of visualization in visual AI/ML. In addition, we describe progress in emerging Full 2D ML, natural language processing, and AI/ML in multidimensional data aided by visual means.
Context-Sensitive Visualization of Deep Learning Natural Language Processing Models
May 25, 2021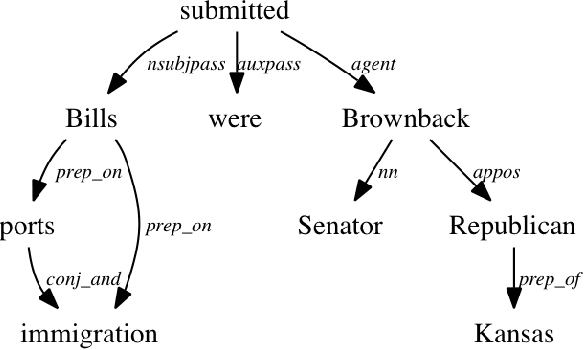
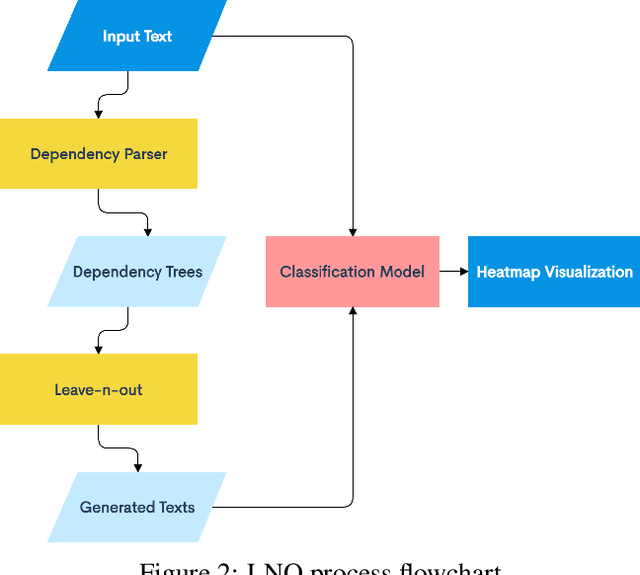
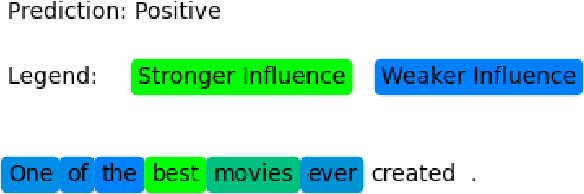

The introduction of Transformer neural networks has changed the landscape of Natural Language Processing (NLP) during the last years. So far, none of the visualization systems has yet managed to examine all the facets of the Transformers. This gave us the motivation of the current work. We propose a new NLP Transformer context-sensitive visualization method that leverages existing NLP tools to find the most significant groups of tokens (words) that have the greatest effect on the output, thus preserving some context from the original text. First, we use a sentence-level dependency parser to highlight promising word groups. The dependency parser creates a tree of relationships between the words in the sentence. Next, we systematically remove adjacent and non-adjacent tuples of \emph{n} tokens from the input text, producing several new texts with those tokens missing. The resulting texts are then passed to a pre-trained BERT model. The classification output is compared with that of the full text, and the difference in the activation strength is recorded. The modified texts that produce the largest difference in the target classification output neuron are selected, and the combination of removed words are then considered to be the most influential on the model's output. Finally, the most influential word combinations are visualized in a heatmap.
Learning in Feedforward Neural Networks Accelerated by Transfer Entropy
Apr 29, 2021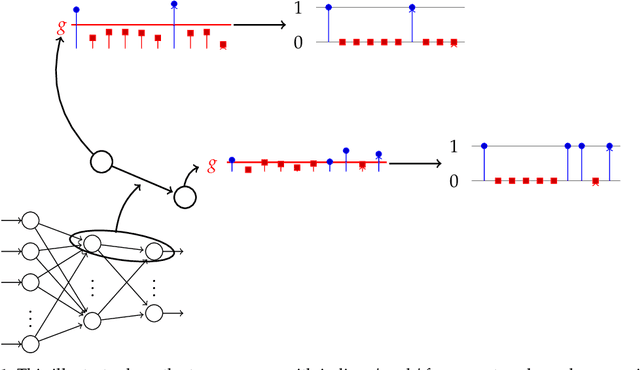
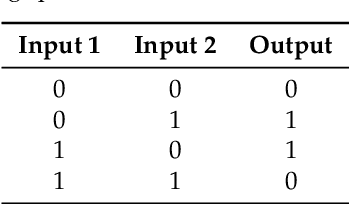
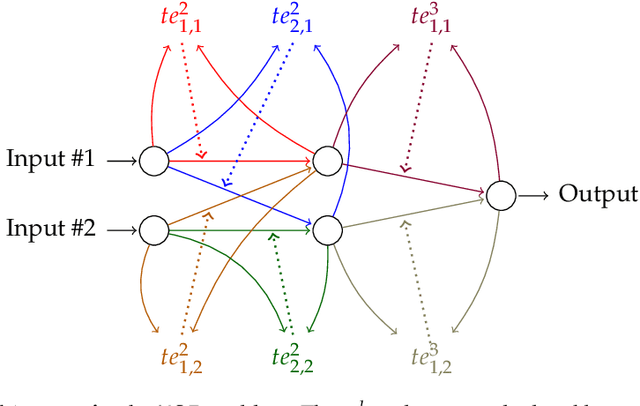
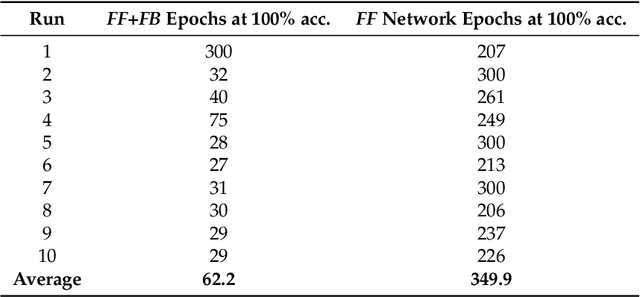
Current neural networks architectures are many times harder to train because of the increasing size and complexity of the used datasets. Our objective is to design more efficient training algorithms utilizing causal relationships inferred from neural networks. The transfer entropy (TE) was initially introduced as an information transfer measure used to quantify the statistical coherence between events (time series). Later, it was related to causality, even if they are not the same. There are only few papers reporting applications of causality or TE in neural networks. Our contribution is an information-theoretical method for analyzing information transfer between the nodes of feedforward neural networks. The information transfer is measured by the TE of feedback neural connections. Intuitively, TE measures the relevance of a connection in the network and the feedback amplifies this connection. We introduce a backpropagation type training algorithm that uses TE feedback connections to improve its performance.