 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Sensitive Visualization of Deep Learning Natural Language Processing Models
May 25, 2021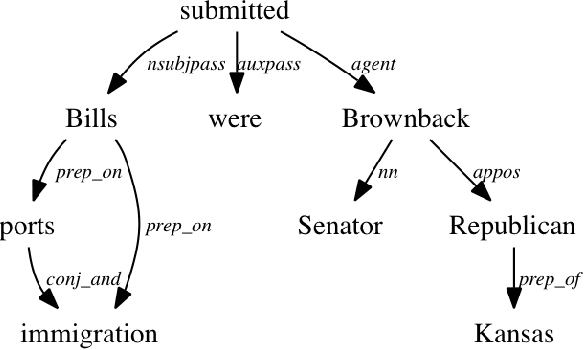
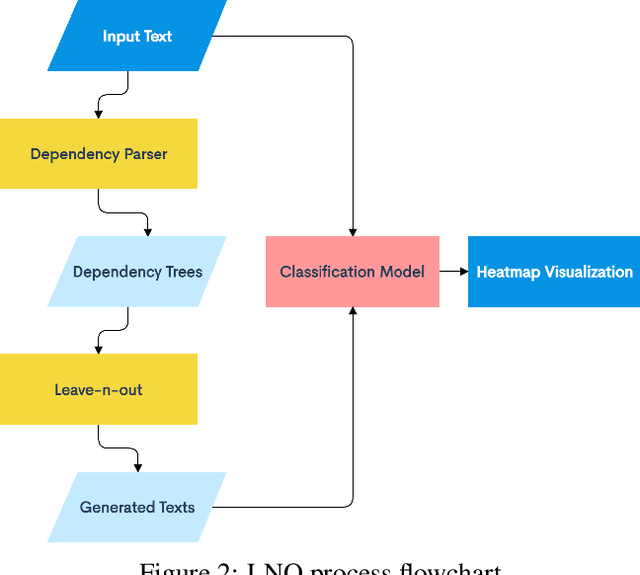
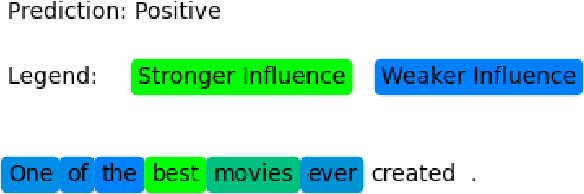

The introduction of Transformer neural networks has changed the landscape of Natural Language Processing (NLP) during the last years. So far, none of the visualization systems has yet managed to examine all the facets of the Transformers. This gave us the motivation of the current work. We propose a new NLP Transformer context-sensitive visualization method that leverages existing NLP tools to find the most significant groups of tokens (words) that have the greatest effect on the output, thus preserving some context from the original text. First, we use a sentence-level dependency parser to highlight promising word groups. The dependency parser creates a tree of relationships between the words in the sentence. Next, we systematically remove adjacent and non-adjacent tuples of \emph{n} tokens from the input text, producing several new texts with those tokens missing. The resulting texts are then passed to a pre-trained BERT model. The classification output is compared with that of the full text, and the difference in the activation strength is recorded. The modified texts that produce the largest difference in the target classification output neuron are selected, and the combination of removed words are then considered to be the most influential on the model's output. Finally, the most influential word combinations are visualized in a heatmap.