 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Prompt Tuning for Large Language Model Services
Paper and Code
May 10, 2023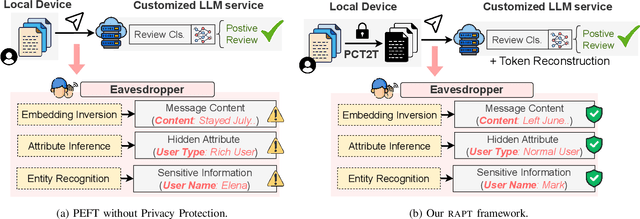
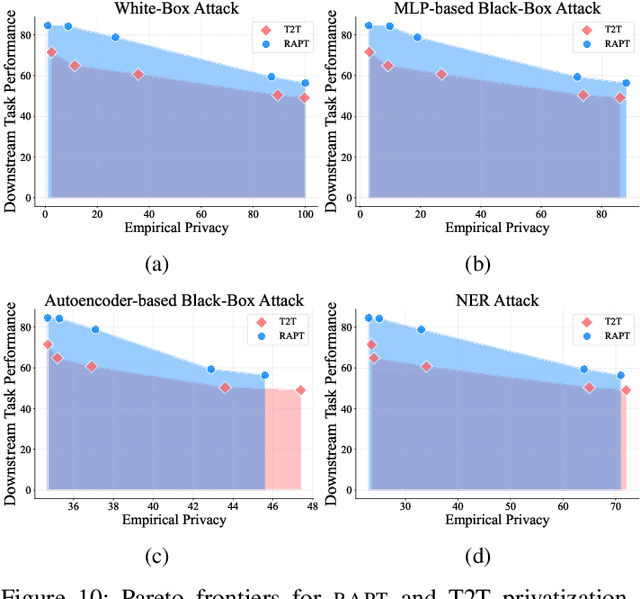
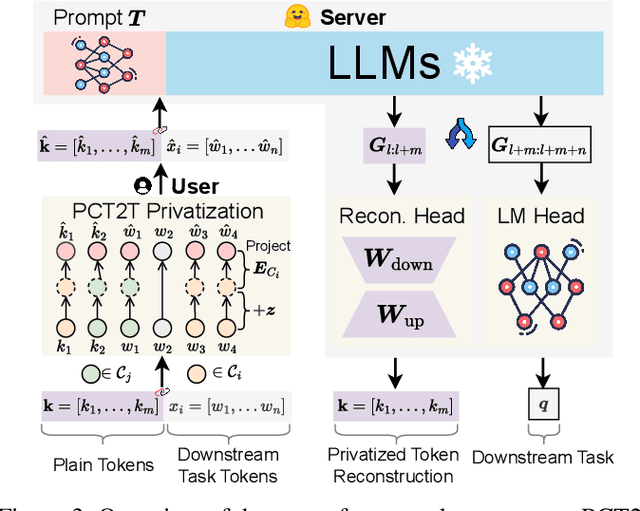
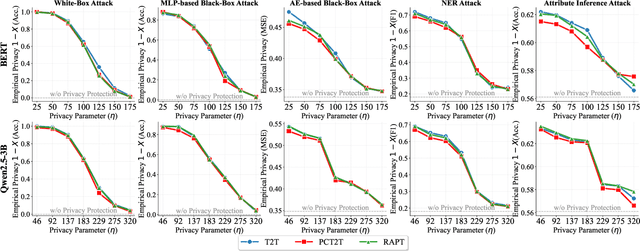
Prompt tuning provides an efficient way for users to customize Large Language Models (LLMs) with their private data in the emerging LLM service scenario. However, the sensitive nature of private data brings the need for privacy preservation in LLM service customization. Based on prompt tuning, we propose Privacy-Preserving Prompt Tuning (RAPT), a framework that provides privacy guarantees for LLM services. \textsc{rapt} adopts a local privacy setting, allowing users to privatize their data locally with local differential privacy. As prompt tuning performs poorly when directly trained on privatized data, we introduce a novel privatized token reconstruction task that is trained jointly with the downstream task, allowing LLMs to learn better task-dependent representations. Despite the simplicity of our framework, experiments show that RAPT achieves competitive performance across tasks while providing privacy guarantees against adversaries.