 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis
May 27, 2025As Large Language Models (LLMs) evolve in understanding and generating code, accurately evaluating their reliability in analyzing source code vulnerabilities becomes increasingly vital. While studies have examined LLM capabilities in tasks like vulnerability detection and repair, they often overlook the importance of both structure and semantic reasoning crucial for trustworthy vulnerability analysis. To address this gap, we introduce SV-TrustEval-C, a benchmark designed to evaluate LLMs' abilities for vulnerability analysis of code written in the C programming language through two key dimensions: structure reasoning - assessing how models identify relationships between code elements under varying data and control flow complexities; and semantic reasoning - examining their logical consistency in scenarios where code is structurally and semantically perturbed. Our results show that current LLMs are far from satisfactory in understanding complex code relationships and that their vulnerability analyses rely more on pattern matching than on robust logical reasoning. These findings underscore the effectiveness of the SV-TrustEval-C benchmark and highlight critical areas for enhancing the reasoning capabilities and trustworthiness of LLMs in real-world vulnerability analysis tasks. Our initial benchmark dataset is publicly available.
Generalized Attacks on Face Verification Systems
Sep 12, 2023



Face verification (FV) using deep neural network models has made tremendous progress in recent years, surpassing human accuracy and seeing deployment in various applications such as border control and smartphone unlocking. However, FV systems are vulnerable to Adversarial Attacks, which manipulate input images to deceive these systems in ways usually unnoticeable to humans. This paper provides an in-depth study of attacks on FV systems. We introduce the DodgePersonation Attack that formulates the creation of face images that impersonate a set of given identities while avoiding being identified as any of the identities in a separate, disjoint set. A taxonomy is proposed to provide a unified view of different types of Adversarial Attacks against FV systems, including Dodging Attacks, Impersonation Attacks, and Master Face Attacks. Finally, we propose the ''One Face to Rule Them All'' Attack which implements the DodgePersonation Attack with state-of-the-art performance on a well-known scenario (Master Face Attack) and which can also be used for the new scenarios introduced in this paper. While the state-of-the-art Master Face Attack can produce a set of 9 images to cover 43.82% of the identities in their test database, with 9 images our attack can cover 57.27% to 58.5% of these identifies while giving the attacker the choice of the identity to use to create the impersonation. Moreover, the 9 generated attack images appear identical to a casual observer.
Measuring Improvement of F$_1$-Scores in Detection of Self-Admitted Technical Debt
Mar 16, 2023
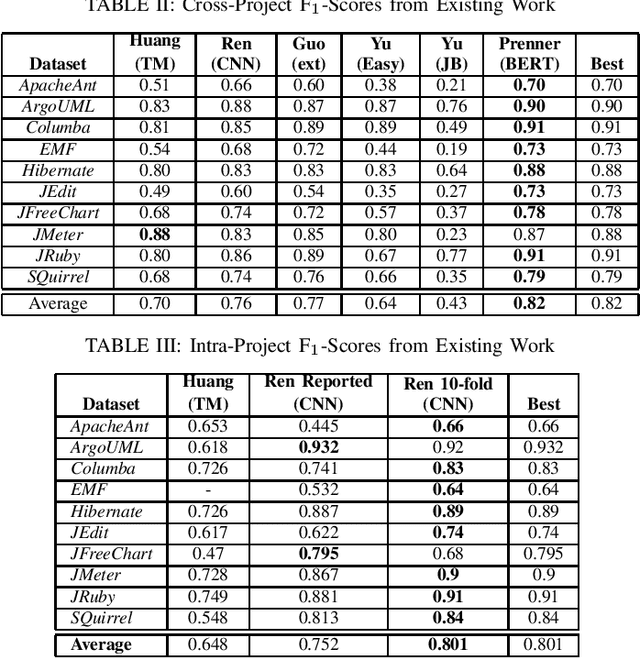
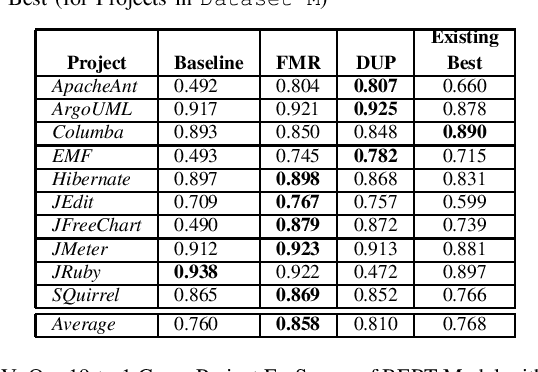
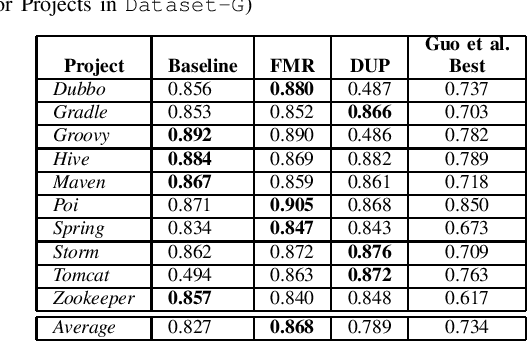
Artificial Intelligence and Machine Learning have witnessed rapid, significant improvements in Natural Language Processing (NLP) tasks. Utilizing Deep Learning, researchers have taken advantage of repository comments in Software Engineering to produce accurate methods for detecting Self-Admitted Technical Debt (SATD) from 20 open-source Java projects' code. In this work, we improve SATD detection with a novel approach that leverages the Bidirectional Encoder Representations from Transformers (BERT) architecture. For comparison, we re-evaluated previous deep learning methods and applied stratified 10-fold cross-validation to report reliable F$_1$-scores. We examine our model in both cross-project and intra-project contexts. For each context, we use re-sampling and duplication as augmentation strategies to account for data imbalance. We find that our trained BERT model improves over the best performance of all previous methods in 19 of the 20 projects in cross-project scenarios. However, the data augmentation techniques were not sufficient to overcome the lack of data present in the intra-project scenarios, and existing methods still perform better. Future research will look into ways to diversify SATD datasets in order to maximize the latent power in large BERT models.