 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful to Whom? Questioning Interpretability Measures in NLP
Aug 13, 2023A common approach to quantifying model interpretability is to calculate faithfulness metrics based on iteratively masking input tokens and measuring how much the predicted label changes as a result. However, we show that such metrics are generally not suitable for comparing the interpretability of different neural text classifiers as the response to masked inputs is highly model-specific. We demonstrate that iterative masking can produce large variation in faithfulness scores between comparable models, and show that masked samples are frequently outside the distribution seen during training. We further investigate the impact of adversarial attacks and adversarial training on faithfulness scores, and demonstrate the relevance of faithfulness measures for analyzing feature salience in text adversarial attacks. Our findings provide new insights into the limitations of current faithfulness metrics and key considerations to utilize them appropriately.
Measuring Improvement of F$_1$-Scores in Detection of Self-Admitted Technical Debt
Mar 16, 2023
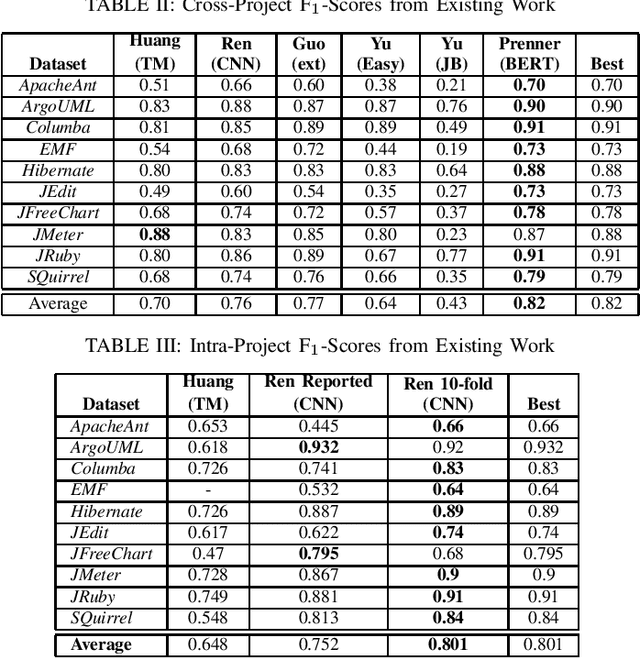
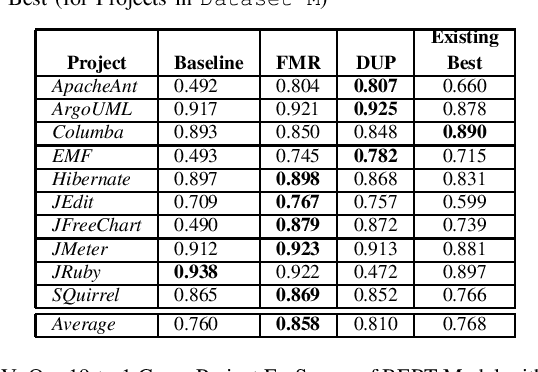
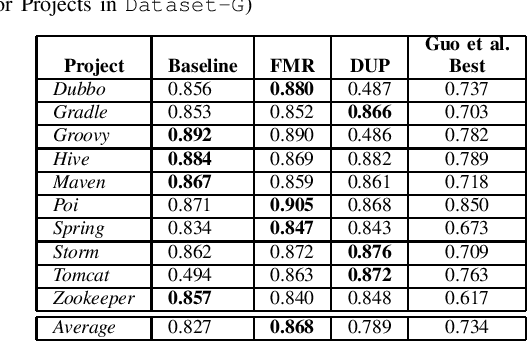
Artificial Intelligence and Machine Learning have witnessed rapid, significant improvements in Natural Language Processing (NLP) tasks. Utilizing Deep Learning, researchers have taken advantage of repository comments in Software Engineering to produce accurate methods for detecting Self-Admitted Technical Debt (SATD) from 20 open-source Java projects' code. In this work, we improve SATD detection with a novel approach that leverages the Bidirectional Encoder Representations from Transformers (BERT) architecture. For comparison, we re-evaluated previous deep learning methods and applied stratified 10-fold cross-validation to report reliable F$_1$-scores. We examine our model in both cross-project and intra-project contexts. For each context, we use re-sampling and duplication as augmentation strategies to account for data imbalance. We find that our trained BERT model improves over the best performance of all previous methods in 19 of the 20 projects in cross-project scenarios. However, the data augmentation techniques were not sufficient to overcome the lack of data present in the intra-project scenarios, and existing methods still perform better. Future research will look into ways to diversify SATD datasets in order to maximize the latent power in large BERT models.
In BLOOM: Creativity and Affinity in Artificial Lyrics and Art
Jan 13, 2023



We apply a large multilingual language model (BLOOM-176B) in open-ended generation of Chinese song lyrics, and evaluate the resulting lyrics for coherence and creativity using human reviewers. We find that current computational metrics for evaluating large language model outputs (MAUVE) have limitations in evaluation of creative writing. We note that the human concept of creativity requires lyrics to be both comprehensible and distinctive -- and that humans assess certain types of machine-generated lyrics to score more highly than real lyrics by popular artists. Inspired by the inherently multimodal nature of album releases, we leverage a Chinese-language stable diffusion model to produce high-quality lyric-guided album art, demonstrating a creative approach for an artist seeking inspiration for an album or single. Finally, we introduce the MojimLyrics dataset, a Chinese-language dataset of popular song lyrics for future research.
Machine Generated Text: A Comprehensive Survey of Threat Models and Detection Methods
Oct 13, 2022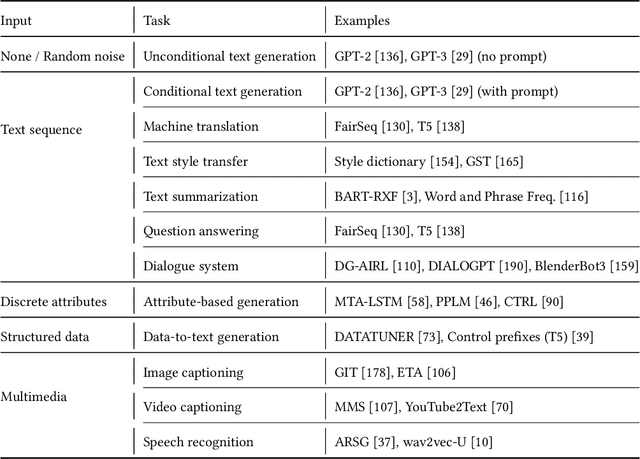

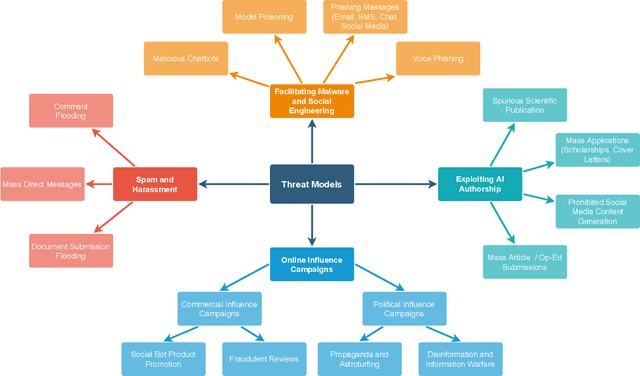

Advances in natural language generation (NLG) have resulted in machine generated text that is increasingly difficult to distinguish from human authored text. Powerful open-source models are freely available, and user-friendly tools democratizing access to generative models are proliferating. The great potential of state-of-the-art NLG systems is tempered by the multitude of avenues for abuse. Detection of machine generated text is a key countermeasure for reducing abuse of NLG models, with significant technical challenges and numerous open problems. We provide a survey that includes both 1) an extensive analysis of threat models posed by contemporary NLG systems, and 2) the most complete review of machine generated text detection methods to date. This survey places machine generated text within its cybersecurity and social context, and provides strong guidance for future work addressing the most critical threat models, and ensuring detection systems themselves demonstrate trustworthiness through fairness, robustness, and accountability.
Adversarial Robustness of Neural-Statistical Features in Detection of Generative Transformers
Mar 02, 2022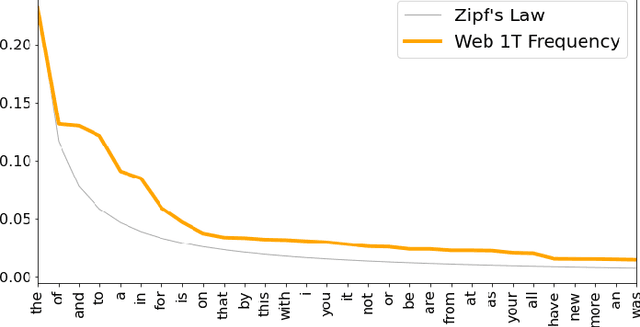
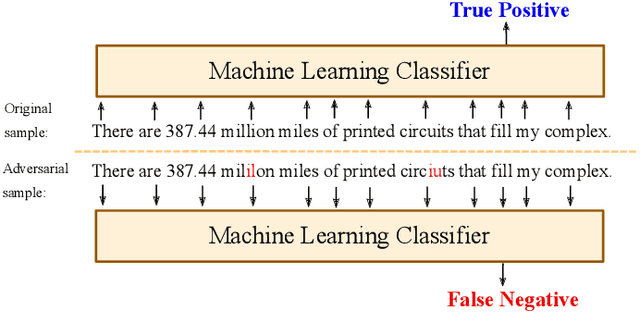
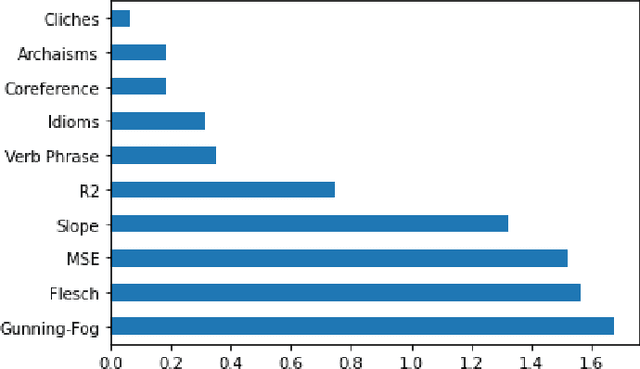
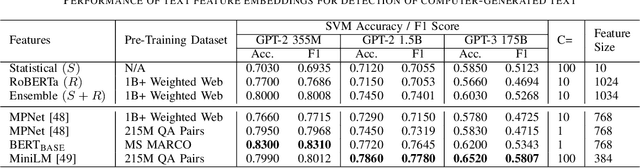
The detection of computer-generated text is an area of rapidly increasing significance as nascent generative models allow for efficient creation of compelling human-like text, which may be abused for the purposes of spam, disinformation, phishing, or online influence campaigns. Past work has studied detection of current state-of-the-art models, but despite a developing threat landscape, there has been minimal analysis of the robustness of detection methods to adversarial attacks. To this end, we evaluate neural and non-neural approaches on their ability to detect computer-generated text, their robustness against text adversarial attacks, and the impact that successful adversarial attacks have on human judgement of text quality. We find that while statistical features underperform neural features, statistical features provide additional adversarial robustness that can be leveraged in ensemble detection models. In the process, we find that previously effective complex phrasal features for detection of computer-generated text hold little predictive power against contemporary generative models, and identify promising statistical features to use instead. Finally, we pioneer the usage of $\Delta$MAUVE as a proxy measure for human judgement of adversarial text quality.
Towards Ethical Content-Based Detection of Online Influence Campaigns
Aug 29, 2019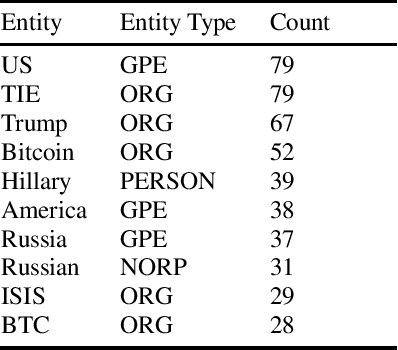


The detection of clandestine efforts to influence users in online communities is a challenging problem with significant active development. We demonstrate that features derived from the text of user comments are useful for identifying suspect activity, but lead to increased erroneous identifications when keywords over-represented in past influence campaigns are present. Drawing on research in native language identification (NLI), we use "named entity masking" (NEM) to create sentence features robust to this shortcoming, while maintaining comparable classification accuracy. We demonstrate that while NEM consistently reduces false positives when key named entities are mentioned, both masked and unmasked models exhibit increased false positive rates on English sentences by Russian native speakers, raising ethical considerations that should be addressed in future research.
McDiarmid Drift Detection Methods for Evolving Data Streams
Jan 17, 2018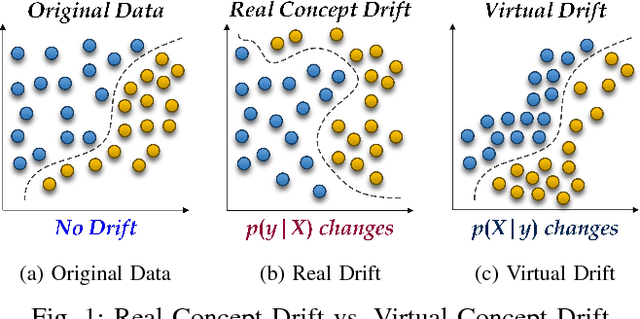
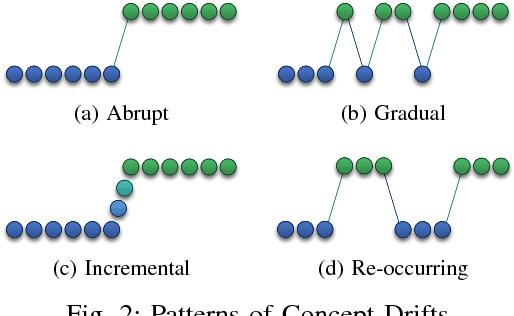
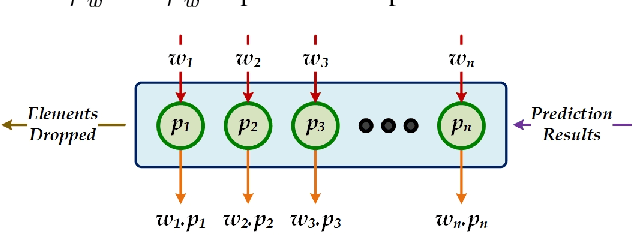
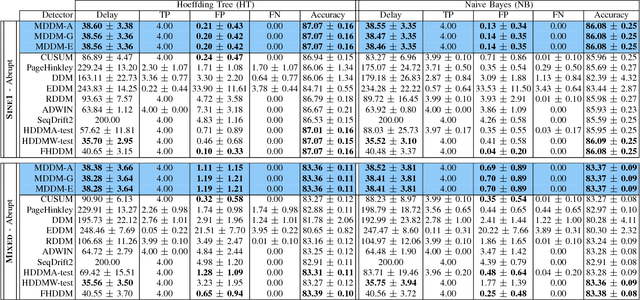
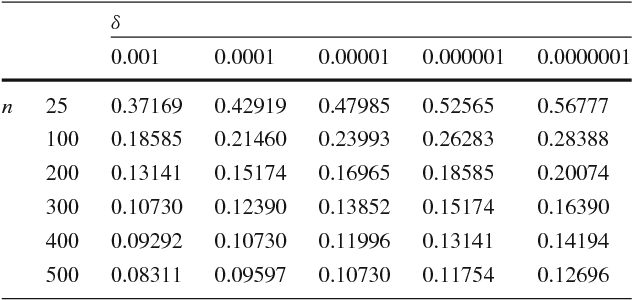
Increasingly, Internet of Things (IoT) domains, such as sensor networks, smart cities, and social networks, generate vast amounts of data. Such data are not only unbounded and rapidly evolving. Rather, the content thereof dynamically evolves over time, often in unforeseen ways. These variations are due to so-called concept drifts, caused by changes in the underlying data generation mechanisms. In a classification setting, concept drift causes the previously learned models to become inaccurate, unsafe and even unusable. Accordingly, concept drifts need to be detected, and handled, as soon as possible. In medical applications and emergency response settings, for example, change in behaviours should be detected in near real-time, to avoid potential loss of life. To this end, we introduce the McDiarmid Drift Detection Method (MDDM), which utilizes McDiarmid's inequality in order to detect concept drift. The MDDM approach proceeds by sliding a window over prediction results, and associate window entries with weights. Higher weights are assigned to the most recent entries, in order to emphasize their importance. As instances are processed, the detection algorithm compares a weighted mean of elements inside the sliding window with the maximum weighted mean observed so far. A significant difference between the two weighted means, upper-bounded by the McDiarmid inequality, implies a concept drift. Our extensive experimentation against synthetic and real-world data streams show that our novel method outperforms the state-of-the-art. Specifically, MDDM yields shorter detection delays as well as lower false negative rates, while maintaining high classification accuracies.
Reservoir of Diverse Adaptive Learners and Stacking Fast Hoeffding Drift Detection Methods for Evolving Data Streams
Sep 07, 2017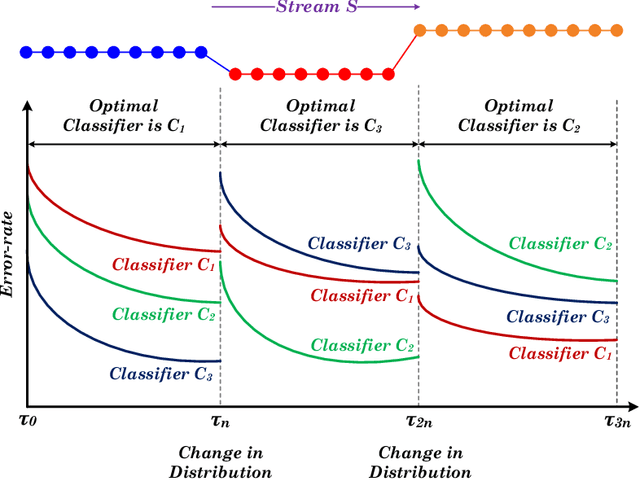
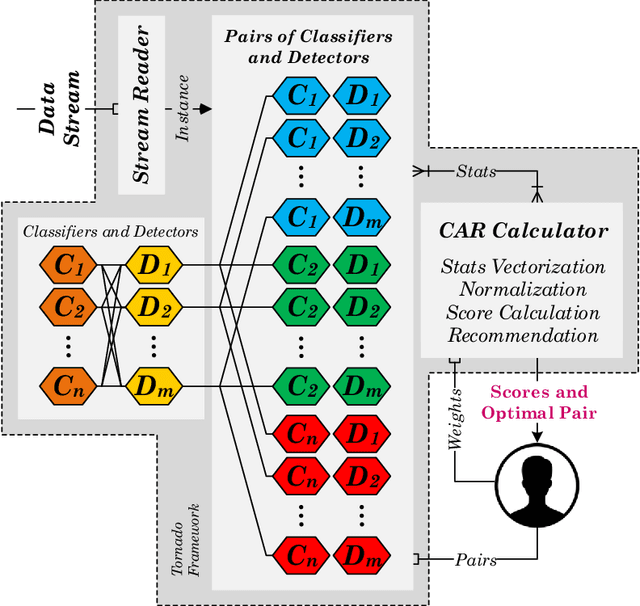
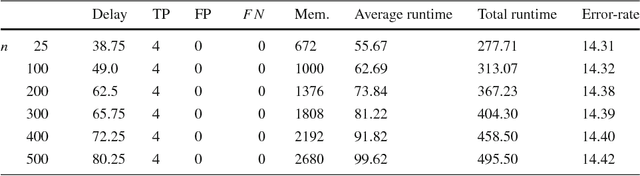
The last decade has seen a surge of interest in adaptive learning algorithms for data stream classification, with applications ranging from predicting ozone level peaks, learning stock market indicators, to detecting computer security violations. In addition, a number of methods have been developed to detect concept drifts in these streams. Consider a scenario where we have a number of classifiers with diverse learning styles and different drift detectors. Intuitively, the current 'best' (classifier, detector) pair is application dependent and may change as a result of the stream evolution. Our research builds on this observation. We introduce the $\mbox{Tornado}$ framework that implements a reservoir of diverse classifiers, together with a variety of drift detection algorithms. In our framework, all (classifier, detector) pairs proceed, in parallel, to construct models against the evolving data streams. At any point in time, we select the pair which currently yields the best performance. We further incorporate two novel stacking-based drift detection methods, namely the $\mbox{FHDDMS}$ and $\mbox{FHDDMS}_{add}$ approaches. The experimental evaluation confirms that the current 'best' (classifier, detector) pair is not only heavily dependent on the characteristics of the stream, but also that this selection evolves as the stream flows. Further, our $\mbox{FHDDMS}$ variants detect concept drifts accurately in a timely fashion while outperforming the state-of-the-art.