 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZephyr quantum-assisted hierarchical Calo4pQVAE for particle-calorimeter interactions
Dec 06, 2024With the approach of the High Luminosity Large Hadron Collider (HL-LHC) era set to begin particle collisions by the end of this decade, it is evident that the computational demands of traditional collision simulation methods are becoming increasingly unsustainable. Existing approaches, which rely heavily on first-principles Monte Carlo simulations for modeling event showers in calorimeters, are projected to require millions of CPU-years annually -- far exceeding current computational capacities. This bottleneck presents an exciting opportunity for advancements in computational physics by integrating deep generative models with quantum simulations. We propose a quantum-assisted hierarchical deep generative surrogate founded on a variational autoencoder (VAE) in combination with an energy conditioned restricted Boltzmann machine (RBM) embedded in the model's latent space as a prior. By mapping the topology of D-Wave's Zephyr quantum annealer (QA) into the nodes and couplings of a 4-partite RBM, we leverage quantum simulation to accelerate our shower generation times significantly. To evaluate our framework, we use Dataset 2 of the CaloChallenge 2022. Through the integration of classical computation and quantum simulation, this hybrid framework paves way for utilizing large-scale quantum simulations as priors in deep generative models.
Conditioned quantum-assisted deep generative surrogate for particle-calorimeter interactions
Oct 30, 2024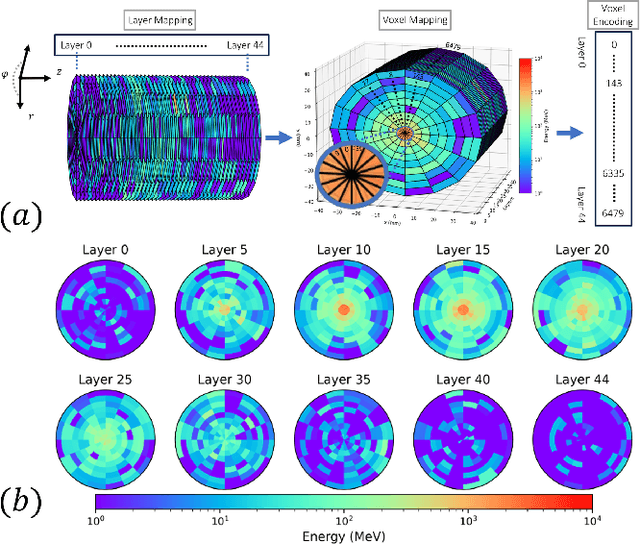
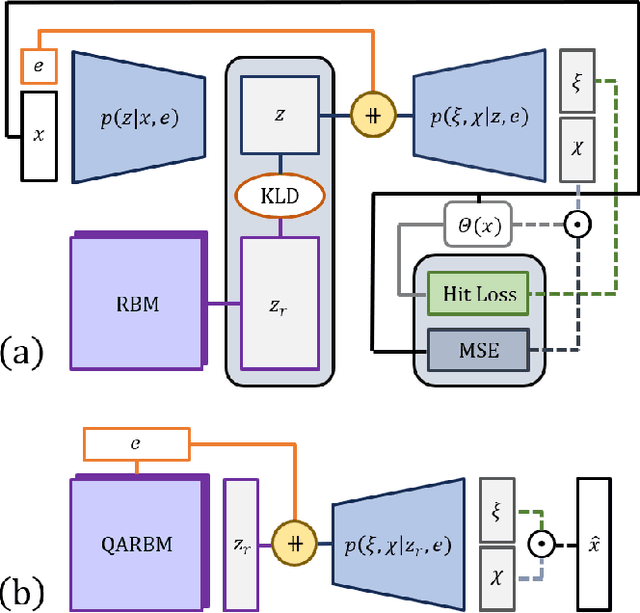
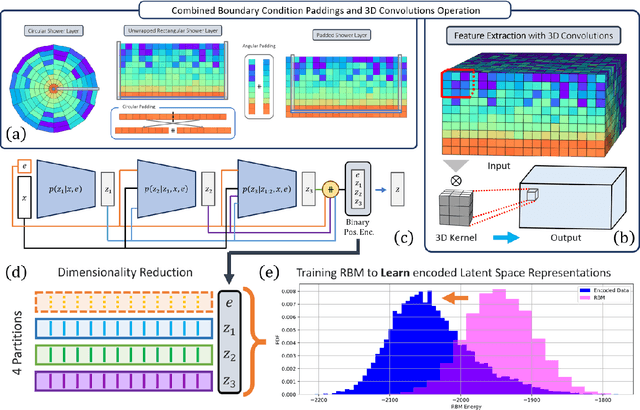
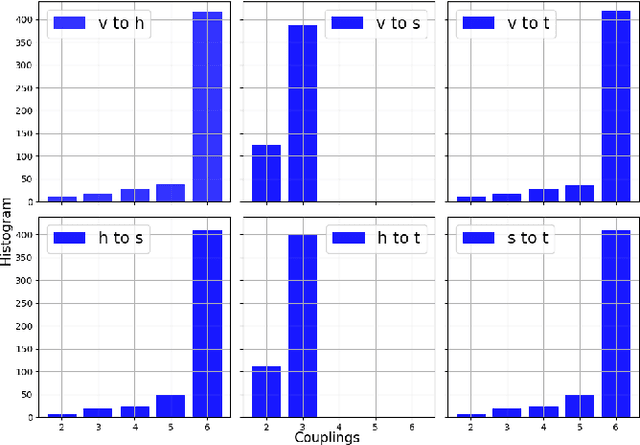
Particle collisions at accelerators such as the Large Hadron Collider, recorded and analyzed by experiments such as ATLAS and CMS, enable exquisite measurements of the Standard Model and searches for new phenomena. Simulations of collision events at these detectors have played a pivotal role in shaping the design of future experiments and analyzing ongoing ones. However, the quest for accuracy in Large Hadron Collider (LHC) collisions comes at an imposing computational cost, with projections estimating the need for millions of CPU-years annually during the High Luminosity LHC (HL-LHC) run \cite{collaboration2022atlas}. Simulating a single LHC event with \textsc{Geant4} currently devours around 1000 CPU seconds, with simulations of the calorimeter subdetectors in particular imposing substantial computational demands \cite{rousseau2023experimental}. To address this challenge, we propose a conditioned quantum-assisted deep generative model. Our model integrates a conditioned variational autoencoder (VAE) on the exterior with a conditioned Restricted Boltzmann Machine (RBM) in the latent space, providing enhanced expressiveness compared to conventional VAEs. The RBM nodes and connections are meticulously engineered to enable the use of qubits and couplers on D-Wave's Pegasus-structured \textit{Advantage} quantum annealer (QA) for sampling. We introduce a novel method for conditioning the quantum-assisted RBM using \textit{flux biases}. We further propose a novel adaptive mapping to estimate the effective inverse temperature in quantum annealers. The effectiveness of our framework is illustrated using Dataset 2 of the CaloChallenge \cite{calochallenge}.
Deep Graph Convolutional Reinforcement Learning for Financial Portfolio Management -- DeepPocket
May 06, 2021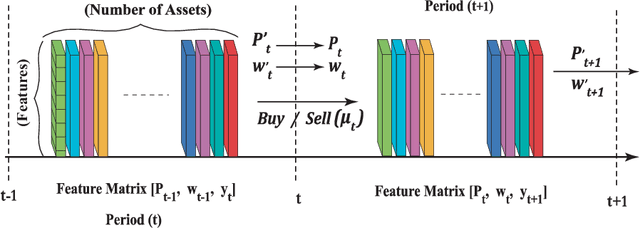
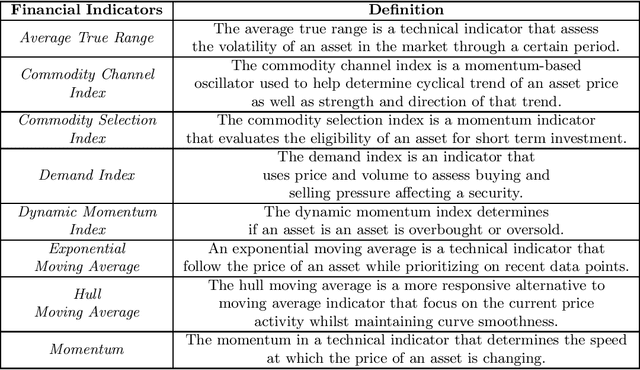
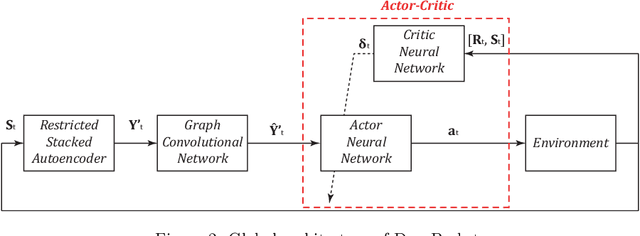
Portfolio management aims at maximizing the return on investment while minimizing risk by continuously reallocating the assets forming the portfolio. These assets are not independent but correlated during a short time period. A graph convolutional reinforcement learning framework called DeepPocket is proposed whose objective is to exploit the time-varying interrelations between financial instruments. These interrelations are represented by a graph whose nodes correspond to the financial instruments while the edges correspond to a pair-wise correlation function in between assets. DeepPocket consists of a restricted, stacked autoencoder for feature extraction, a convolutional network to collect underlying local information shared among financial instruments, and an actor-critic reinforcement learning agent. The actor-critic structure contains two convolutional networks in which the actor learns and enforces an investment policy which is, in turn, evaluated by the critic in order to determine the best course of action by constantly reallocating the various portfolio assets to optimize the expected return on investment. The agent is initially trained offline with online stochastic batching on historical data. As new data become available, it is trained online with a passive concept drift approach to handle unexpected changes in their distributions. DeepPocket is evaluated against five real-life datasets over three distinct investment periods, including during the Covid-19 crisis, and clearly outperformed market indexes.
McDiarmid Drift Detection Methods for Evolving Data Streams
Jan 17, 2018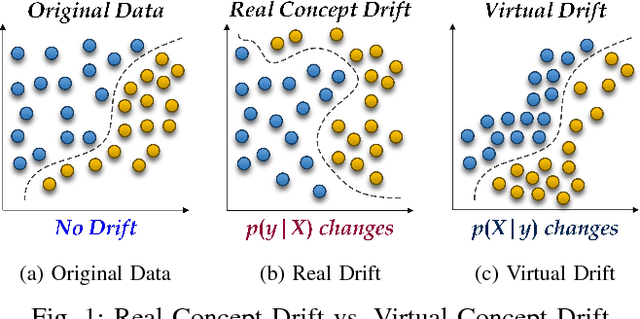
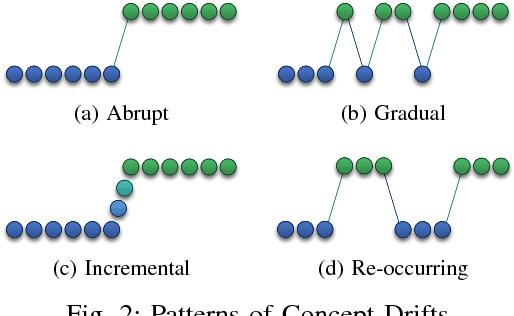
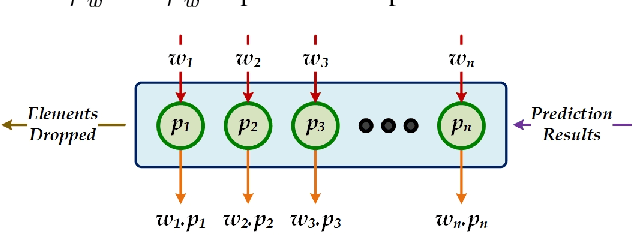
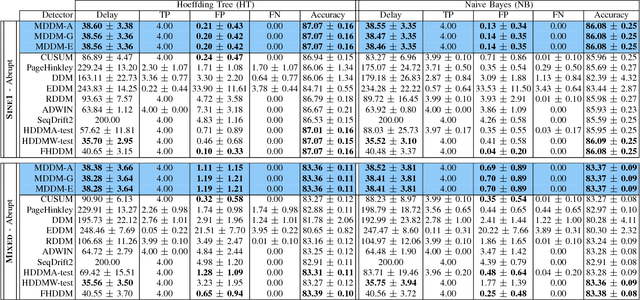
Increasingly, Internet of Things (IoT) domains, such as sensor networks, smart cities, and social networks, generate vast amounts of data. Such data are not only unbounded and rapidly evolving. Rather, the content thereof dynamically evolves over time, often in unforeseen ways. These variations are due to so-called concept drifts, caused by changes in the underlying data generation mechanisms. In a classification setting, concept drift causes the previously learned models to become inaccurate, unsafe and even unusable. Accordingly, concept drifts need to be detected, and handled, as soon as possible. In medical applications and emergency response settings, for example, change in behaviours should be detected in near real-time, to avoid potential loss of life. To this end, we introduce the McDiarmid Drift Detection Method (MDDM), which utilizes McDiarmid's inequality in order to detect concept drift. The MDDM approach proceeds by sliding a window over prediction results, and associate window entries with weights. Higher weights are assigned to the most recent entries, in order to emphasize their importance. As instances are processed, the detection algorithm compares a weighted mean of elements inside the sliding window with the maximum weighted mean observed so far. A significant difference between the two weighted means, upper-bounded by the McDiarmid inequality, implies a concept drift. Our extensive experimentation against synthetic and real-world data streams show that our novel method outperforms the state-of-the-art. Specifically, MDDM yields shorter detection delays as well as lower false negative rates, while maintaining high classification accuracies.
Reservoir of Diverse Adaptive Learners and Stacking Fast Hoeffding Drift Detection Methods for Evolving Data Streams
Sep 07, 2017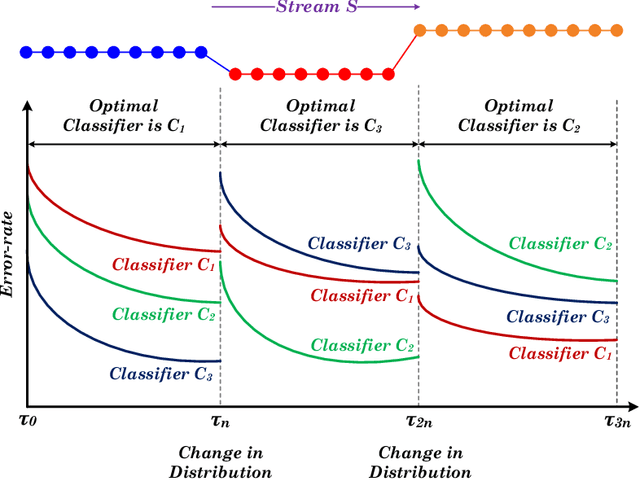
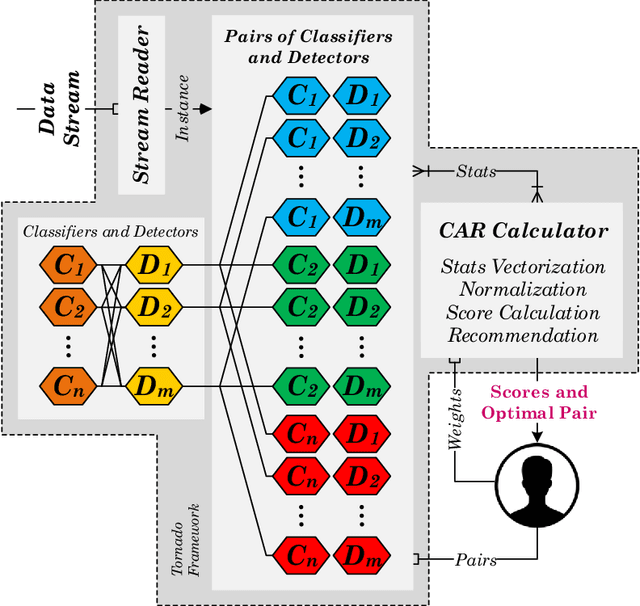
The last decade has seen a surge of interest in adaptive learning algorithms for data stream classification, with applications ranging from predicting ozone level peaks, learning stock market indicators, to detecting computer security violations. In addition, a number of methods have been developed to detect concept drifts in these streams. Consider a scenario where we have a number of classifiers with diverse learning styles and different drift detectors. Intuitively, the current 'best' (classifier, detector) pair is application dependent and may change as a result of the stream evolution. Our research builds on this observation. We introduce the $\mbox{Tornado}$ framework that implements a reservoir of diverse classifiers, together with a variety of drift detection algorithms. In our framework, all (classifier, detector) pairs proceed, in parallel, to construct models against the evolving data streams. At any point in time, we select the pair which currently yields the best performance. We further incorporate two novel stacking-based drift detection methods, namely the $\mbox{FHDDMS}$ and $\mbox{FHDDMS}_{add}$ approaches. The experimental evaluation confirms that the current 'best' (classifier, detector) pair is not only heavily dependent on the characteristics of the stream, but also that this selection evolves as the stream flows. Further, our $\mbox{FHDDMS}$ variants detect concept drifts accurately in a timely fashion while outperforming the state-of-the-art.