 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZephyr quantum-assisted hierarchical Calo4pQVAE for particle-calorimeter interactions
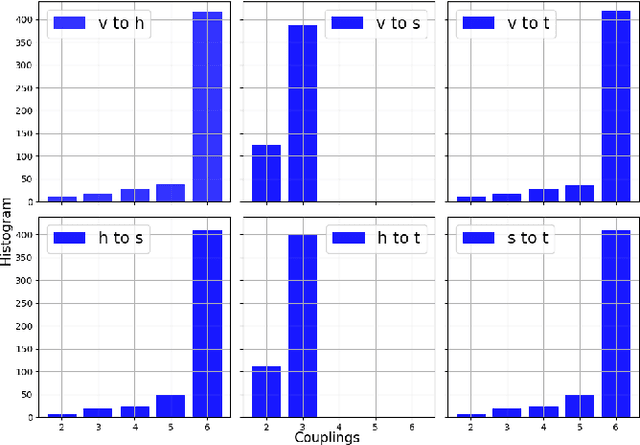
Dec 06, 2024With the approach of the High Luminosity Large Hadron Collider (HL-LHC) era set to begin particle collisions by the end of this decade, it is evident that the computational demands of traditional collision simulation methods are becoming increasingly unsustainable. Existing approaches, which rely heavily on first-principles Monte Carlo simulations for modeling event showers in calorimeters, are projected to require millions of CPU-years annually -- far exceeding current computational capacities. This bottleneck presents an exciting opportunity for advancements in computational physics by integrating deep generative models with quantum simulations. We propose a quantum-assisted hierarchical deep generative surrogate founded on a variational autoencoder (VAE) in combination with an energy conditioned restricted Boltzmann machine (RBM) embedded in the model's latent space as a prior. By mapping the topology of D-Wave's Zephyr quantum annealer (QA) into the nodes and couplings of a 4-partite RBM, we leverage quantum simulation to accelerate our shower generation times significantly. To evaluate our framework, we use Dataset 2 of the CaloChallenge 2022. Through the integration of classical computation and quantum simulation, this hybrid framework paves way for utilizing large-scale quantum simulations as priors in deep generative models.
Conditioned quantum-assisted deep generative surrogate for particle-calorimeter interactions
Oct 30, 2024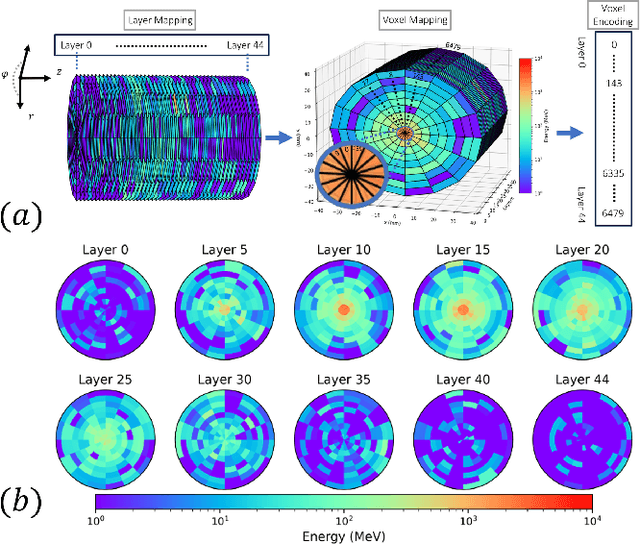
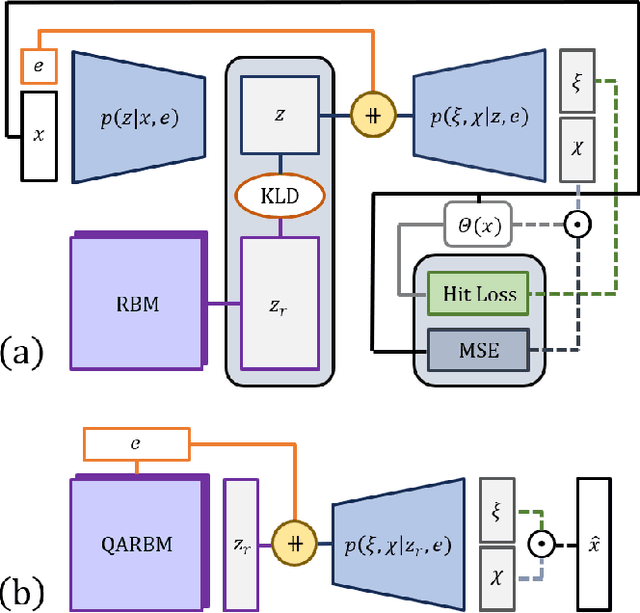
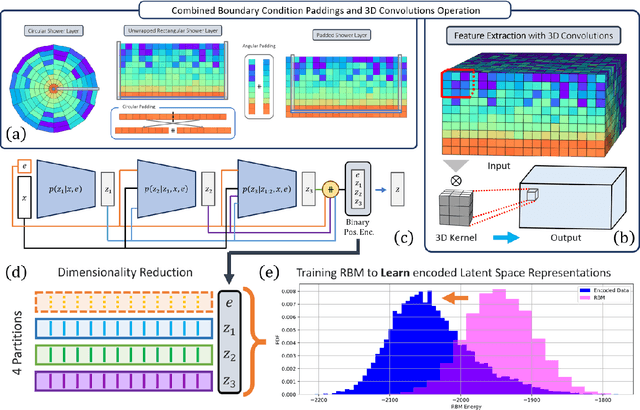
Particle collisions at accelerators such as the Large Hadron Collider, recorded and analyzed by experiments such as ATLAS and CMS, enable exquisite measurements of the Standard Model and searches for new phenomena. Simulations of collision events at these detectors have played a pivotal role in shaping the design of future experiments and analyzing ongoing ones. However, the quest for accuracy in Large Hadron Collider (LHC) collisions comes at an imposing computational cost, with projections estimating the need for millions of CPU-years annually during the High Luminosity LHC (HL-LHC) run \cite{collaboration2022atlas}. Simulating a single LHC event with \textsc{Geant4} currently devours around 1000 CPU seconds, with simulations of the calorimeter subdetectors in particular imposing substantial computational demands \cite{rousseau2023experimental}. To address this challenge, we propose a conditioned quantum-assisted deep generative model. Our model integrates a conditioned variational autoencoder (VAE) on the exterior with a conditioned Restricted Boltzmann Machine (RBM) in the latent space, providing enhanced expressiveness compared to conventional VAEs. The RBM nodes and connections are meticulously engineered to enable the use of qubits and couplers on D-Wave's Pegasus-structured \textit{Advantage} quantum annealer (QA) for sampling. We introduce a novel method for conditioning the quantum-assisted RBM using \textit{flux biases}. We further propose a novel adaptive mapping to estimate the effective inverse temperature in quantum annealers. The effectiveness of our framework is illustrated using Dataset 2 of the CaloChallenge \cite{calochallenge}.
CaloQVAE : Simulating high-energy particle-calorimeter interactions using hybrid quantum-classical generative models
Dec 15, 2023The Large Hadron Collider's high luminosity era presents major computational challenges in the analysis of collision events. Large amounts of Monte Carlo (MC) simulation will be required to constrain the statistical uncertainties of the simulated datasets below these of the experimental data. Modelling of high-energy particles propagating through the calorimeter section of the detector is the most computationally intensive MC simulation task. We introduce a technique combining recent advancements in generative models and quantum annealing for fast and efficient simulation of high-energy particle-calorimeter interactions.
CaloDVAE : Discrete Variational Autoencoders for Fast Calorimeter Shower Simulation
Oct 14, 2022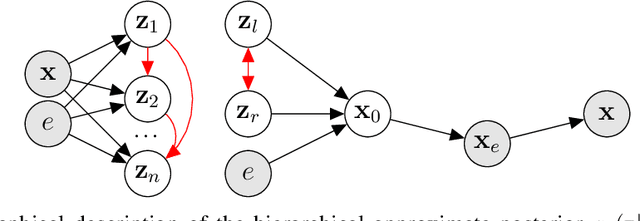

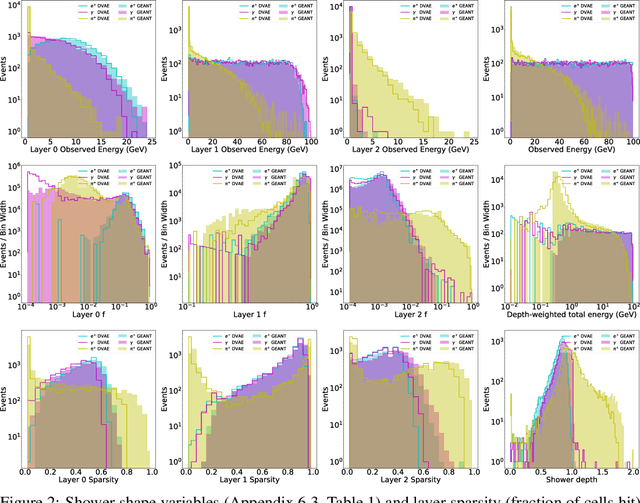

Calorimeter simulation is the most computationally expensive part of Monte Carlo generation of samples necessary for analysis of experimental data at the Large Hadron Collider (LHC). The High-Luminosity upgrade of the LHC would require an even larger amount of such samples. We present a technique based on Discrete Variational Autoencoders (DVAEs) to simulate particle showers in Electromagnetic Calorimeters. We discuss how this work paves the way towards exploration of quantum annealing processors as sampling devices for generation of simulated High Energy Physics datasets.
Variational Autoencoders for Generative Modelling of Water Cherenkov Detectors
Nov 01, 2019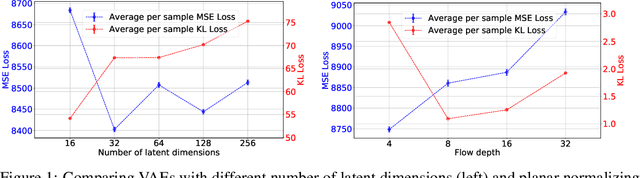



Matter-antimatter asymmetry is one of the major unsolved problems in physics that can be probed through precision measurements of charge-parity symmetry violation at current and next-generation neutrino oscillation experiments. In this work, we demonstrate the capability of variational autoencoders and normalizing flows to approximate the generative distribution of simulated data for water Cherenkov detectors commonly used in these experiments. We study the performance of these methods and their applicability for semi-supervised learning and synthetic data generation.
Fine-grained Entity Recognition with Reduced False Negatives and Large Type Coverage
Apr 30, 2019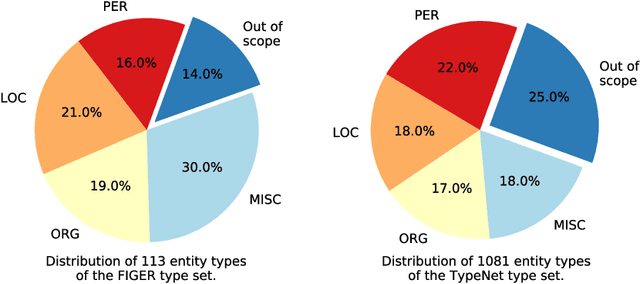


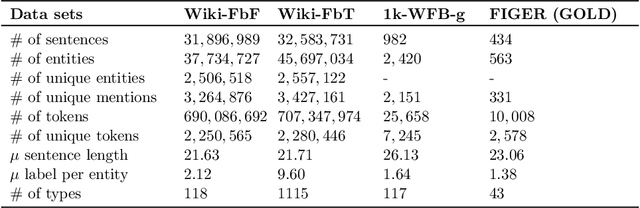
Fine-grained Entity Recognition (FgER) is the task of detecting and classifying entity mentions to a large set of types spanning diverse domains such as biomedical, finance and sports. We observe that when the type set spans several domains, detection of entity mention becomes a limitation for supervised learning models. The primary reason being lack of dataset where entity boundaries are properly annotated while covering a large spectrum of entity types. Our work directly addresses this issue. We propose Heuristics Allied with Distant Supervision (HAnDS) framework to automatically construct a quality dataset suitable for the FgER task. HAnDS framework exploits the high interlink among Wikipedia and Freebase in a pipelined manner, reducing annotation errors introduced by naively using distant supervision approach. Using HAnDS framework, we create two datasets, one suitable for building FgER systems recognizing up to 118 entity types based on the FIGER type hierarchy and another for up to 1115 entity types based on the TypeNet hierarchy. Our extensive empirical experimentation warrants the quality of the generated datasets. Along with this, we also provide a manually annotated dataset for benchmarking FgER systems.
A Unified Labeling Approach by Pooling Diverse Datasets for Entity Typing
Oct 27, 2018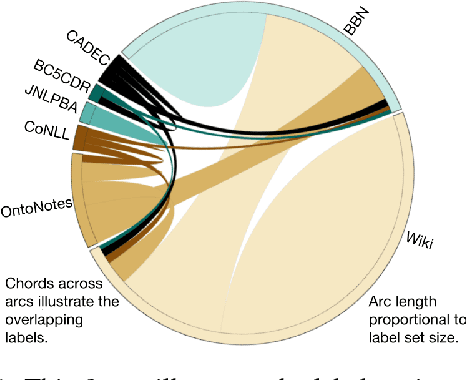
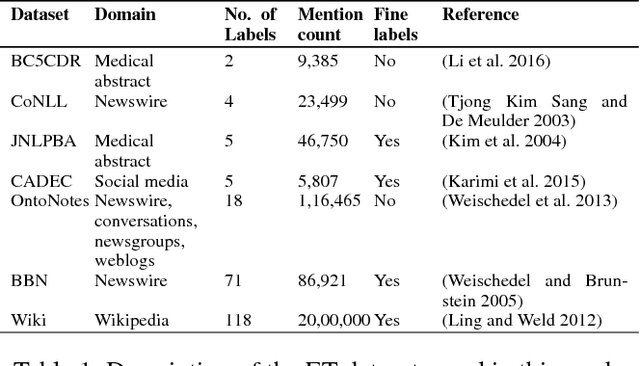
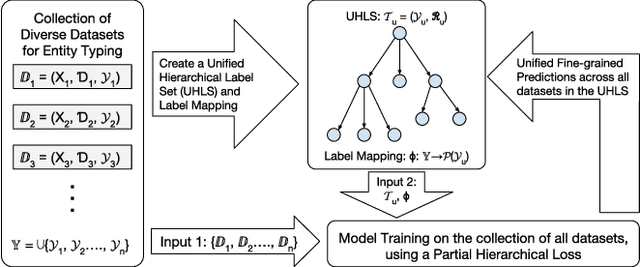
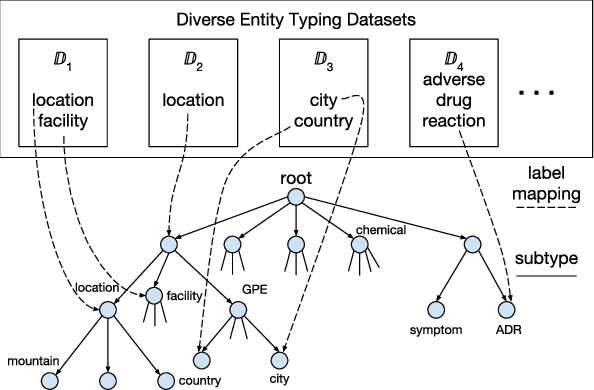
Evolution of entity typing (ET) has led to the generation of multiple datasets. These datasets span from being coarse-grained to fine-grained encompassing numerous domains. Existing works primarily focus on improving the performance of a model on an individual dataset, independently. This narrowly focused view of ET causes two issues: 1) type assignment when information about the test data domain or target label set is not available; 2) fine-grained type prediction when there is no dataset in the same domain with finer-type annotations. Our goal is to shift the focus from individual domain-specific datasets to all the datasets available for ET. In our proposed approach, we convert the label set of all datasets to a unified hierarchical label set while preserving the semantic properties of the individual labels. Then utilizing a partial label loss, we train a single neural network based classifier using every available dataset for the ET task. We empirically evaluate the effectiveness of our approach on seven real-world diverse ET datasets. The results convey that the combined training on multiple datasets helps the model to generalize better and to predict fine-types across all domains without relying on a specific domain or label set information during evaluation.