 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearnable phases of matter
Feb 11, 2026We identify fundamental limitations in machine learning by demonstrating that non-trivial mixed-state phases of matter are computationally hard to learn. Focusing on unsupervised learning of distributions, we show that autoregressive neural networks fail to learn global properties of distributions characterized by locally indistinguishable (LI) states. We demonstrate that conditional mutual information (CMI) is a useful diagnostic for LI: we show that for classical distributions, long-range CMI of a state implies a spatially LI partner. By introducing a restricted statistical query model, we prove that nontrivial phases with long-range CMI, such as strong-to-weak spontaneous symmetry breaking phases, are hard to learn. We validate our claims by using recurrent, convolutional, and Transformer neural networks to learn the syndrome and physical distributions of toric/surface code under bit flip noise. Our findings suggest hardness of learning as a diagnostic tool for detecting mixed-state phases and transitions and error-correction thresholds, and they suggest CMI and more generally ``non-local Gibbsness'' as metrics for how hard a distribution is to learn.
Private and interpretable clinical prediction with quantum-inspired tensor train models
Feb 05, 2026Machine learning in clinical settings must balance predictive accuracy, interpretability, and privacy. Models such as logistic regression (LR) offer transparency, while neural networks (NNs) provide greater predictive power; yet both remain vulnerable to privacy attacks. We empirically assess these risks by designing attacks that identify which public datasets were used to train a model under varying levels of adversarial access, applying them to LORIS, a publicly available LR model for immunotherapy response prediction, as well as to additional shallow NN models trained for the same task. Our results show that both models leak significant training-set information, with LRs proving particularly vulnerable in white-box scenarios. Moreover, we observe that common practices such as cross-validation in LRs exacerbate these risks. To mitigate these vulnerabilities, we propose a quantum-inspired defense based on tensorizing discretized models into tensor trains (TTs), which fully obfuscates parameters while preserving accuracy, reducing white-box attacks to random guessing and degrading black-box attacks comparably to Differential Privacy. TT models retain LR interpretability and extend it through efficient computation of marginal and conditional distributions, while also enabling this higher level of interpretability for NNs. Our results demonstrate that tensorization is widely applicable and establishes a practical foundation for private, interpretable, and effective clinical prediction.
Exploring the Energy Landscape of RBMs: Reciprocal Space Insights into Bosons, Hierarchical Learning and Symmetry Breaking
Mar 27, 2025Deep generative models have become ubiquitous due to their ability to learn and sample from complex distributions. Despite the proliferation of various frameworks, the relationships among these models remain largely unexplored, a gap that hinders the development of a unified theory of AI learning. We address two central challenges: clarifying the connections between different deep generative models and deepening our understanding of their learning mechanisms. We focus on Restricted Boltzmann Machines (RBMs), known for their universal approximation capabilities for discrete distributions. By introducing a reciprocal space formulation, we reveal a connection between RBMs, diffusion processes, and coupled Bosons. We show that at initialization, the RBM operates at a saddle point, where the local curvature is determined by the singular values, whose distribution follows the Marcenko-Pastur law and exhibits rotational symmetry. During training, this rotational symmetry is broken due to hierarchical learning, where different degrees of freedom progressively capture features at multiple levels of abstraction. This leads to a symmetry breaking in the energy landscape, reminiscent of Landau theory. This symmetry breaking in the energy landscape is characterized by the singular values and the weight matrix eigenvector matrix. We derive the corresponding free energy in a mean-field approximation. We show that in the limit of infinite size RBM, the reciprocal variables are Gaussian distributed. Our findings indicate that in this regime, there will be some modes for which the diffusion process will not converge to the Boltzmann distribution. To illustrate our results, we trained replicas of RBMs with different hidden layer sizes using the MNIST dataset. Our findings bridge the gap between disparate generative frameworks and also shed light on the processes underpinning learning in generative models.
Autoregressive model path dependence near Ising criticality
Aug 28, 2024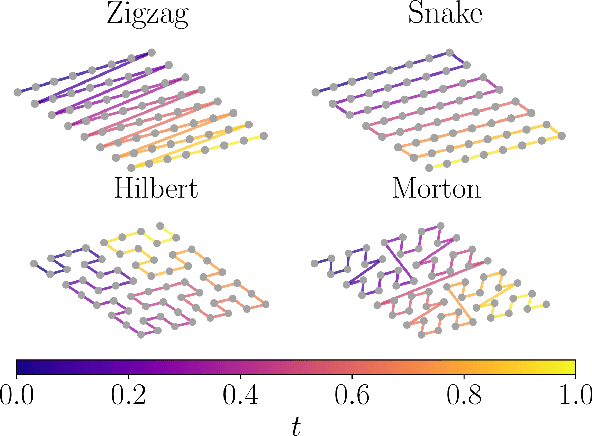
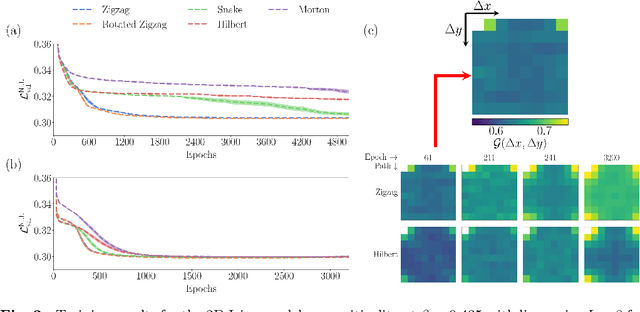
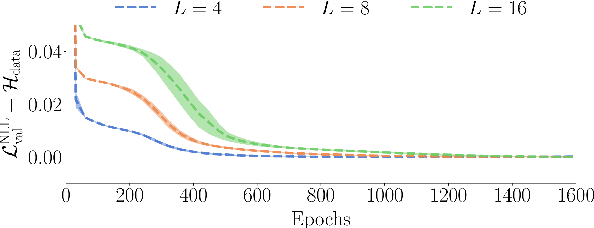
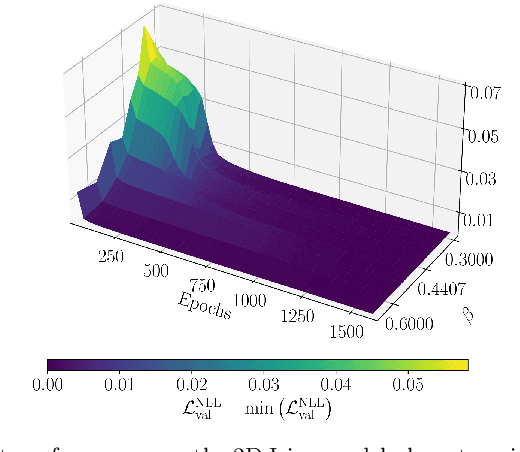
Autoregressive models are a class of generative model that probabilistically predict the next output of a sequence based on previous inputs. The autoregressive sequence is by definition one-dimensional (1D), which is natural for language tasks and hence an important component of modern architectures like recurrent neural networks (RNNs) and transformers. However, when language models are used to predict outputs on physical systems that are not intrinsically 1D, the question arises of which choice of autoregressive sequence -- if any -- is optimal. In this paper, we study the reconstruction of critical correlations in the two-dimensional (2D) Ising model, using RNNs and transformers trained on binary spin data obtained near the thermal phase transition. We compare the training performance for a number of different 1D autoregressive sequences imposed on finite-size 2D lattices. We find that paths with long 1D segments are more efficient at training the autoregressive models compared to space-filling curves that better preserve the 2D locality. Our results illustrate the potential importance in choosing the optimal autoregressive sequence ordering when training modern language models for tasks in physics.
Robust quantum dots charge autotuning using neural networks uncertainty
Jun 07, 2024This study presents a machine-learning-based procedure to automate the charge tuning of semiconductor spin qubits with minimal human intervention, addressing one of the significant challenges in scaling up quantum dot technologies. This method exploits artificial neural networks to identify noisy transition lines in stability diagrams, guiding a robust exploration strategy leveraging neural networks' uncertainty estimations. Tested across three distinct offline experimental datasets representing different single quantum dot technologies, the approach achieves over 99% tuning success rate in optimal cases, where more than 10% of the success is directly attributable to uncertainty exploitation. The challenging constraints of small training sets containing high diagram-to-diagram variability allowed us to evaluate the capabilities and limits of the proposed procedure.
CaloQVAE : Simulating high-energy particle-calorimeter interactions using hybrid quantum-classical generative models
Dec 15, 2023The Large Hadron Collider's high luminosity era presents major computational challenges in the analysis of collision events. Large amounts of Monte Carlo (MC) simulation will be required to constrain the statistical uncertainties of the simulated datasets below these of the experimental data. Modelling of high-energy particles propagating through the calorimeter section of the detector is the most computationally intensive MC simulation task. We introduce a technique combining recent advancements in generative models and quantum annealing for fast and efficient simulation of high-energy particle-calorimeter interactions.
Investigating Topological Order using Recurrent Neural Networks
Mar 26, 2023Recurrent neural networks (RNNs), originally developed for natural language processing, hold great promise for accurately describing strongly correlated quantum many-body systems. Here, we employ 2D RNNs to investigate two prototypical quantum many-body Hamiltonians exhibiting topological order. Specifically, we demonstrate that RNN wave functions can effectively capture the topological order of the toric code and a Bose-Hubbard spin liquid on the kagome lattice by estimating their topological entanglement entropies. We also find that RNNs favor coherent superpositions of minimally-entangled states over minimally-entangled states themselves. Overall, our findings demonstrate that RNN wave functions constitute a powerful tool to study phases of matter beyond Landau's symmetry-breaking paradigm.
Supplementing Recurrent Neural Network Wave Functions with Symmetry and Annealing to Improve Accuracy
Jul 28, 2022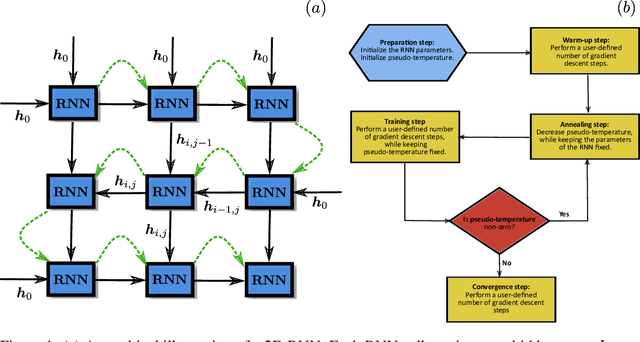
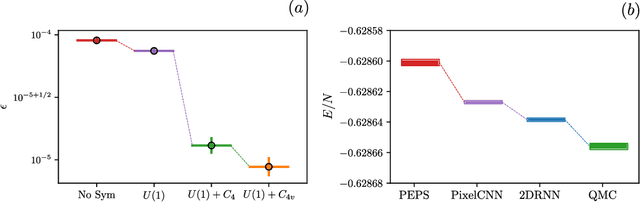
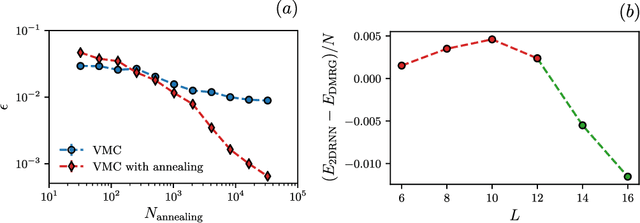
Recurrent neural networks (RNNs) are a class of neural networks that have emerged from the paradigm of artificial intelligence and has enabled lots of interesting advances in the field of natural language processing. Interestingly, these architectures were shown to be powerful ansatze to approximate the ground state of quantum systems. Here, we build over the results of [Phys. Rev. Research 2, 023358 (2020)] and construct a more powerful RNN wave function ansatz in two dimensions. We use symmetry and annealing to obtain accurate estimates of ground state energies of the two-dimensional (2D) Heisenberg model, on the square lattice and on the triangular lattice. We show that our method is superior to Density Matrix Renormalisation Group (DMRG) for system sizes larger than or equal to $14 \times 14$ on the triangular lattice.
* 11 pages, 4 figures, 1 table. Originally published in Machine Learning and the Physical Sciences Workshop (NeurIPS 2021), see: https://ml4physicalsciences.github.io/2021/files/NeurIPS_ML4PS_2021_92.pdf. Our reproducibility code can be found on https://github.com/mhibatallah/RNNWavefunctions
Twin Neural Network Regression is a Semi-Supervised Regression Algorithm
Jun 11, 2021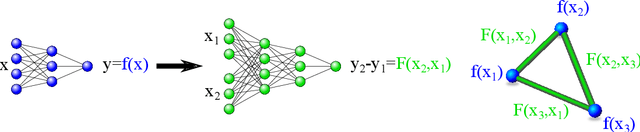
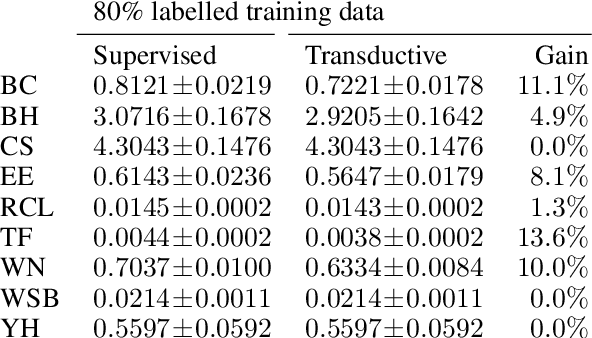
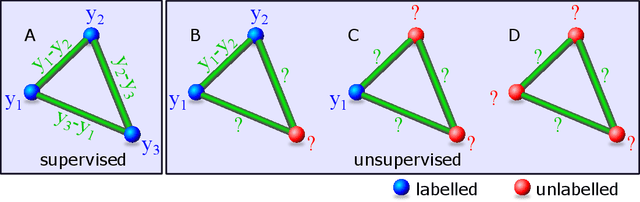
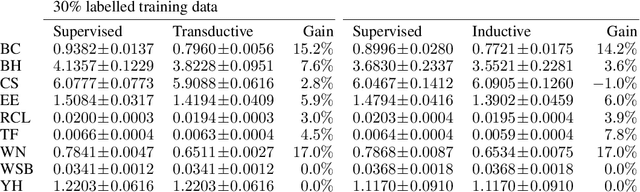
Twin neural network regression (TNNR) is a semi-supervised regression algorithm, it can be trained on unlabelled data points as long as other, labelled anchor data points, are present. TNNR is trained to predict differences between the target values of two different data points rather than the targets themselves. By ensembling predicted differences between the targets of an unseen data point and all training data points, it is possible to obtain a very accurate prediction for the original regression problem. Since any loop of predicted differences should sum to zero, loops can be supplied to the training data, even if the data points themselves within loops are unlabelled. Semi-supervised training improves TNNR performance, which is already state of the art, significantly.
Variational Neural Annealing
Jan 25, 2021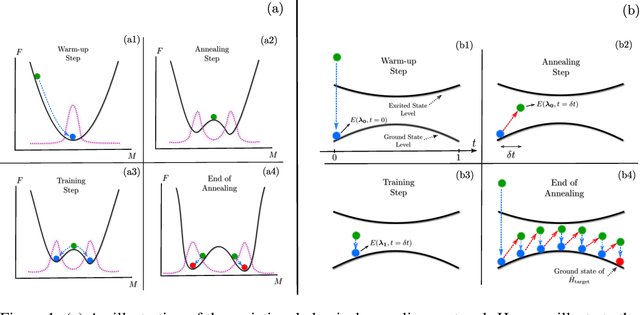
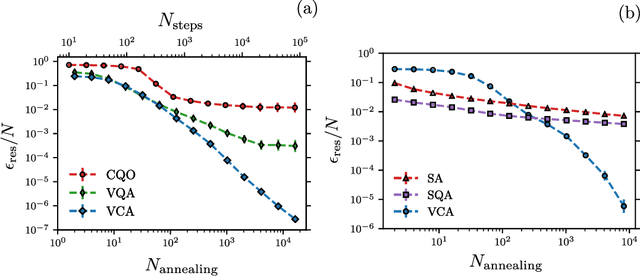
Many important challenges in science and technology can be cast as optimization problems. When viewed in a statistical physics framework, these can be tackled by simulated annealing, where a gradual cooling procedure helps search for groundstate solutions of a target Hamiltonian. While powerful, simulated annealing is known to have prohibitively slow sampling dynamics when the optimization landscape is rough or glassy. Here we show that by generalizing the target distribution with a parameterized model, an analogous annealing framework based on the variational principle can be used to search for groundstate solutions. Modern autoregressive models such as recurrent neural networks provide ideal parameterizations since they can be exactly sampled without slow dynamics even when the model encodes a rough landscape. We implement this procedure in the classical and quantum settings on several prototypical spin glass Hamiltonians, and find that it significantly outperforms traditional simulated annealing in the asymptotic limit, illustrating the potential power of this yet unexplored route to optimization.