 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Scan Recurrent Neural Quantum States for Scalable Variational Monte Carlo
May 13, 2026Neural-network quantum states have emerged as a powerful variational framework for quantum many-body systems, with recent progress often driven by massively parallel architectures such as transformers. Recurrent neural network quantum states, however, are frequently regarded as intrinsically sequential and therefore less scalable. Here we revisit this view by showing that modern recurrent architectures can support fast, accurate, and computationally accessible neural quantum state simulations. Using autoregressive recurrent wave functions together with recent advances in parallelizable recurrence, we develop variational ansätze, called parallel scan recurrent neural quantum states (PSR-NQS), which can be trained efficiently within variational Monte Carlo in one and two spatial dimensions. We demonstrate accurate benchmark results and show that, with iterative retraining, our approach reaches two-dimensional spin lattices as large as $52\times52$ while remaining in agreement with available quantum Monte Carlo data. Our results establish recurrent architectures as a practical and promising route toward scalable neural quantum state simulations with modest computational resources.
Geometry-Induced Long-Range Correlations in Recurrent Neural Network Quantum States
Apr 09, 2026Neural Quantum States based on autoregressive recurrent neural network (RNN) wave functions enable efficient sampling without Markov-chain autocorrelation, but standard RNN architectures are biased toward finite-length correlations and can fail on states with long-range dependencies. A common response is to adopt transformer-style self-attention, but this typically comes with substantially higher computational and memory overhead. Here we introduce dilated RNN wave functions, where recurrent units access distant sites through dilated connections, injecting an explicit long-range inductive bias while retaining a favorable $\mathcal{O}(N \log N)$ forward pass scaling. We show analytically that dilation changes the correlation geometry and can induce power-law correlation scaling in a simplified linearized and perturbative setting. Numerically, for the critical 1D transverse-field Ising model, dilated RNNs reproduce the expected power-law connected two-point correlations in contrast to the exponential decay typical of conventional RNN ansätze. We further show that the dilated RNN accurately approximates the one-dimensional Cluster state, a paradigmatic example with long-range conditional correlations that has previously been reported to be challenging for RNN-based wave functions. These results highlight dilation as a simple geometric mechanism for building correlation-aware autoregressive neural quantum states.
Graph--Theoretic Analysis of Phase Optimization Complexity in Variational Wave Functions for Heisenberg Antiferromagnets
Feb 04, 2026Despite extensive study, the phase structure of the wavefunctions in frustrated Heisenberg antiferromagnets (HAF) is not yet systematically characterized. In this work, we represent the Hilbert space of an HAF as a weighted graph, which we term the Hilbert graph (HG), whose vertices are spin configurations and whose edges are generated by off-diagonal spin-flip terms of the Heisenberg Hamiltonian, with weights set by products of wavefunction amplitudes. Holding the amplitudes fixed and restricting phases to $\mathbb{Z}_2$ values, the phase-dependent variational energy can be recast as a classical Ising antiferromagnet on the HG, so that phase reconstruction of the ground state reduces to a weighted Max-Cut instance. This shows that phase reconstruction HAF is worst-case NP-hard and provides a direct link between wavefunction sign structure and combinatorial optimization.
Lattice Protein Folding with Variational Annealing
Feb 28, 2025Understanding the principles of protein folding is a cornerstone of computational biology, with implications for drug design, bioengineering, and the understanding of fundamental biological processes. Lattice protein folding models offer a simplified yet powerful framework for studying the complexities of protein folding, enabling the exploration of energetically optimal folds under constrained conditions. However, finding these optimal folds is a computationally challenging combinatorial optimization problem. In this work, we introduce a novel upper-bound training scheme that employs masking to identify the lowest-energy folds in two-dimensional Hydrophobic-Polar (HP) lattice protein folding. By leveraging Dilated Recurrent Neural Networks (RNNs) integrated with an annealing process driven by temperature-like fluctuations, our method accurately predicts optimal folds for benchmark systems of up to 60 beads. Our approach also effectively masks invalid folds from being sampled without compromising the autoregressive sampling properties of RNNs. This scheme is generalizable to three spatial dimensions and can be extended to lattice protein models with larger alphabets. Our findings emphasize the potential of advanced machine learning techniques in tackling complex protein folding problems and a broader class of constrained combinatorial optimization challenges.
Recurrent neural network wave functions for Rydberg atom arrays on kagome lattice
May 30, 2024
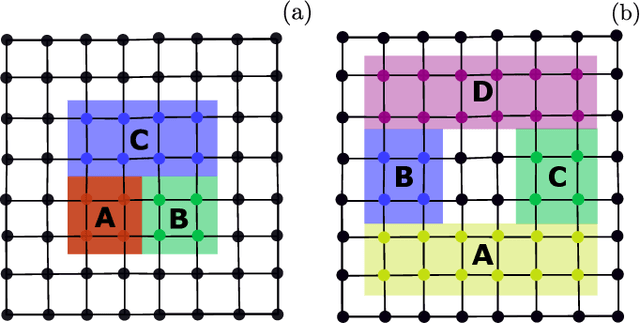
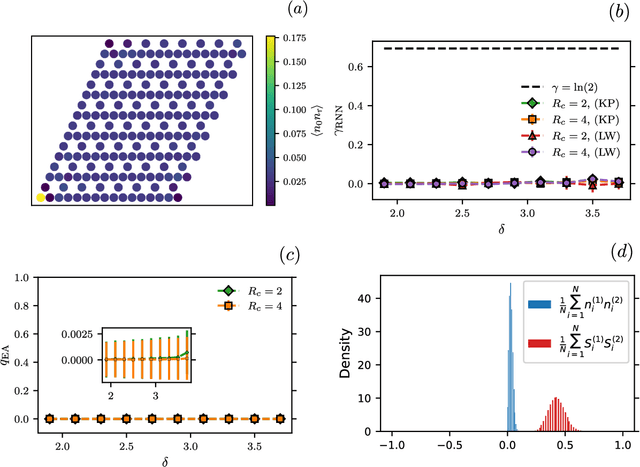
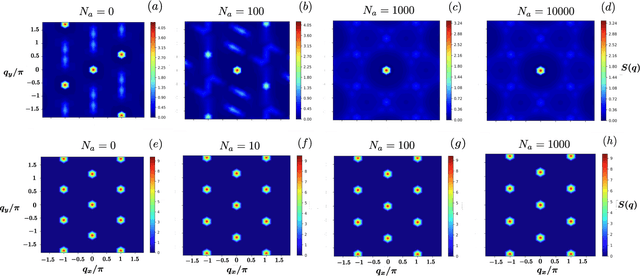
Rydberg atom array experiments have demonstrated the ability to act as powerful quantum simulators, preparing strongly-correlated phases of matter which are challenging to study for conventional computer simulations. A key direction has been the implementation of interactions on frustrated geometries, in an effort to prepare exotic many-body states such as spin liquids and glasses. In this paper, we apply two-dimensional recurrent neural network (RNN) wave functions to study the ground states of Rydberg atom arrays on the kagome lattice. We implement an annealing scheme to find the RNN variational parameters in regions of the phase diagram where exotic phases may occur, corresponding to rough optimization landscapes. For Rydberg atom array Hamiltonians studied previously on the kagome lattice, our RNN ground states show no evidence of exotic spin liquid or emergent glassy behavior. In the latter case, we argue that the presence of a non-zero Edwards-Anderson order parameter is an artifact of the long autocorrelations times experienced with quantum Monte Carlo simulations. This result emphasizes the utility of autoregressive models, such as RNNs, to explore Rydberg atom array physics on frustrated lattices and beyond.
A Framework for Demonstrating Practical Quantum Advantage: Racing Quantum against Classical Generative Models
Mar 27, 2023
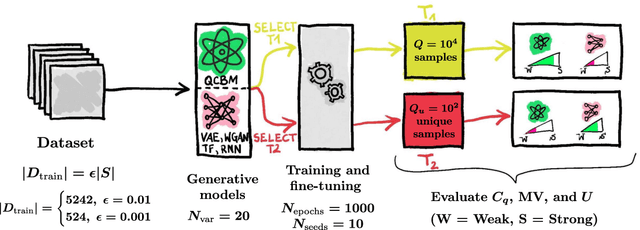

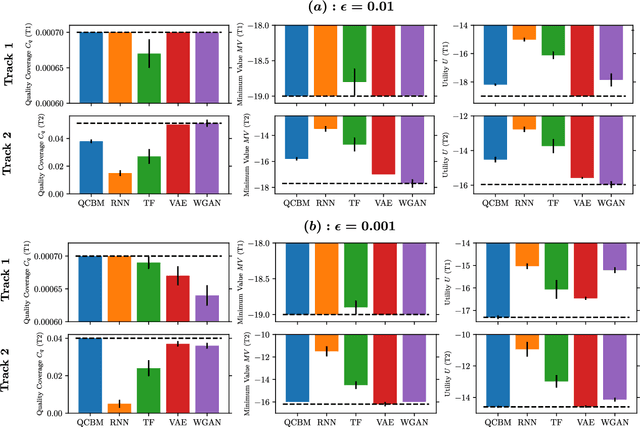
Generative modeling has seen a rising interest in both classical and quantum machine learning, and it represents a promising candidate to obtain a practical quantum advantage in the near term. In this study, we build over a proposed framework for evaluating the generalization performance of generative models, and we establish the first quantitative comparative race towards practical quantum advantage (PQA) between classical and quantum generative models, namely Quantum Circuit Born Machines (QCBMs), Transformers (TFs), Recurrent Neural Networks (RNNs), Variational Autoencoders (VAEs), and Wasserstein Generative Adversarial Networks (WGANs). After defining four types of PQAs scenarios, we focus on what we refer to as potential PQA, aiming to compare quantum models with the best-known classical algorithms for the task at hand. We let the models race on a well-defined and application-relevant competition setting, where we illustrate and demonstrate our framework on 20 variables (qubits) generative modeling task. Our results suggest that QCBMs are more efficient in the data-limited regime than the other state-of-the-art classical generative models. Such a feature is highly desirable in a wide range of real-world applications where the available data is scarce.
Investigating Topological Order using Recurrent Neural Networks
Mar 26, 2023Recurrent neural networks (RNNs), originally developed for natural language processing, hold great promise for accurately describing strongly correlated quantum many-body systems. Here, we employ 2D RNNs to investigate two prototypical quantum many-body Hamiltonians exhibiting topological order. Specifically, we demonstrate that RNN wave functions can effectively capture the topological order of the toric code and a Bose-Hubbard spin liquid on the kagome lattice by estimating their topological entanglement entropies. We also find that RNNs favor coherent superpositions of minimally-entangled states over minimally-entangled states themselves. Overall, our findings demonstrate that RNN wave functions constitute a powerful tool to study phases of matter beyond Landau's symmetry-breaking paradigm.
Quantum HyperNetworks: Training Binary Neural Networks in Quantum Superposition
Jan 19, 2023



Binary neural networks, i.e., neural networks whose parameters and activations are constrained to only two possible values, offer a compelling avenue for the deployment of deep learning models on energy- and memory-limited devices. However, their training, architectural design, and hyperparameter tuning remain challenging as these involve multiple computationally expensive combinatorial optimization problems. Here we introduce quantum hypernetworks as a mechanism to train binary neural networks on quantum computers, which unify the search over parameters, hyperparameters, and architectures in a single optimization loop. Through classical simulations, we demonstrate that of our approach effectively finds optimal parameters, hyperparameters and architectural choices with high probability on classification problems including a two-dimensional Gaussian dataset and a scaled-down version of the MNIST handwritten digits. We represent our quantum hypernetworks as variational quantum circuits, and find that an optimal circuit depth maximizes the probability of finding performant binary neural networks. Our unified approach provides an immense scope for other applications in the field of machine learning.
Supplementing Recurrent Neural Network Wave Functions with Symmetry and Annealing to Improve Accuracy
Jul 28, 2022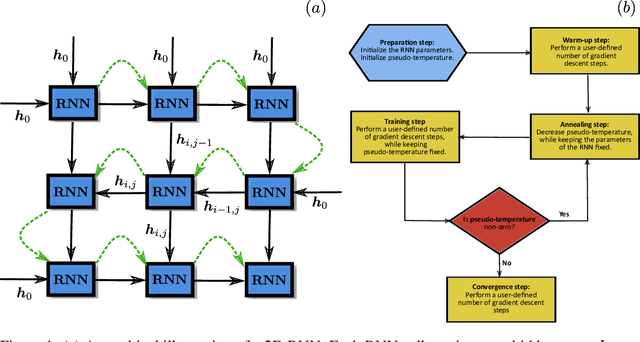
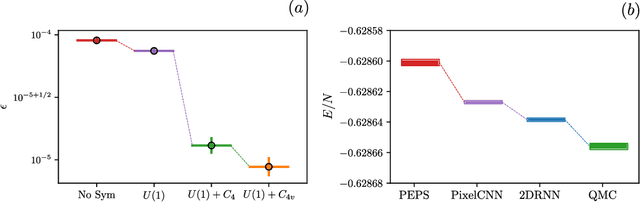
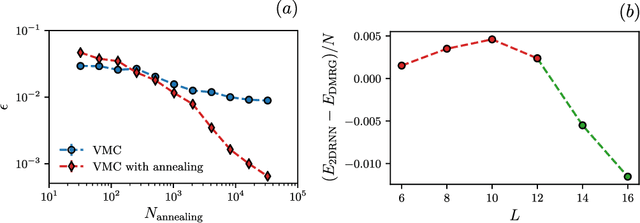
Recurrent neural networks (RNNs) are a class of neural networks that have emerged from the paradigm of artificial intelligence and has enabled lots of interesting advances in the field of natural language processing. Interestingly, these architectures were shown to be powerful ansatze to approximate the ground state of quantum systems. Here, we build over the results of [Phys. Rev. Research 2, 023358 (2020)] and construct a more powerful RNN wave function ansatz in two dimensions. We use symmetry and annealing to obtain accurate estimates of ground state energies of the two-dimensional (2D) Heisenberg model, on the square lattice and on the triangular lattice. We show that our method is superior to Density Matrix Renormalisation Group (DMRG) for system sizes larger than or equal to $14 \times 14$ on the triangular lattice.
* 11 pages, 4 figures, 1 table. Originally published in Machine Learning and the Physical Sciences Workshop (NeurIPS 2021), see: https://ml4physicalsciences.github.io/2021/files/NeurIPS_ML4PS_2021_92.pdf. Our reproducibility code can be found on https://github.com/mhibatallah/RNNWavefunctions
Do Quantum Circuit Born Machines Generalize?
Jul 27, 2022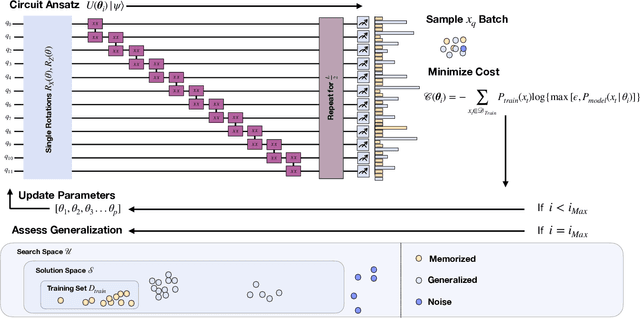
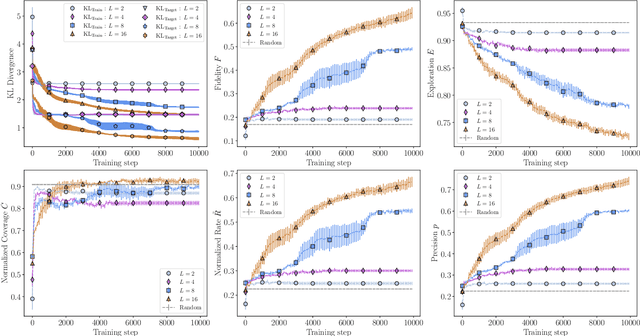
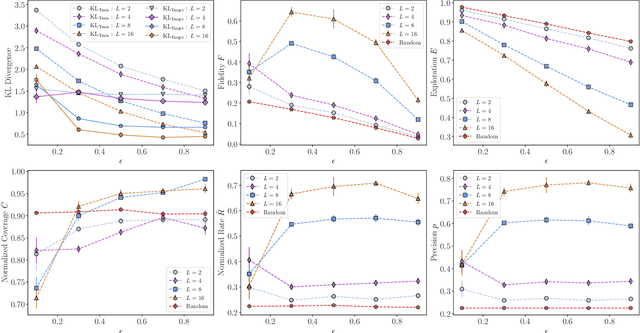
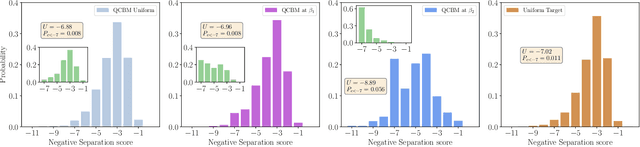
In recent proposals of quantum circuit models for generative tasks, the discussion about their performance has been limited to their ability to reproduce a known target distribution. For example, expressive model families such as Quantum Circuit Born Machines (QCBMs) have been almost entirely evaluated on their capability to learn a given target distribution with high accuracy. While this aspect may be ideal for some tasks, it limits the scope of a generative model's assessment to its ability to memorize data rather than generalize. As a result, there has been little understanding of a model's generalization performance and the relation between such capability and the resource requirements, e.g., the circuit depth and the amount of training data. In this work, we leverage upon a recently proposed generalization evaluation framework to begin addressing this knowledge gap. We first investigate the QCBM's learning process of a cardinality-constrained distribution and see an increase in generalization performance while increasing the circuit depth. In the 12-qubit example presented here, we observe that with as few as 30% of the valid patterns as the training set, the QCBM exhibits the best generalization performance toward generating unseen and valid patterns. Lastly, we assess the QCBM's ability to generalize not only to valid features, but to high-quality bitstrings distributed according to an adequately biased distribution. We see that the QCBM is able to effectively learn the bias and generate unseen samples with higher quality than those in the training set. To the best of our knowledge, this is the first work in the literature that presents the QCBM's generalization performance as an integral evaluation metric for quantum generative models, and demonstrates the QCBM's ability to generalize to high-quality, desired novel samples.