 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating acts of mechanistic reasoning in student team conversations with mechanistic machine learning
Apr 23, 2026STEM education researchers are often interested in identifying moments of students' mechanistic reasoning for deeper analysis, but have limited capacity to search through many team conversation transcripts to find segments with a high concentration of such reasoning. We offer a solution in the form of an interpretable machine learning model that outputs time-varying probabilities that individual students are engaging in acts of mechanistic reasoning, leveraging evidence from their own utterances as well as contributions from the rest of the group. Using the toolkit of intentionally-designed probabilistic models, we introduce a specific inductive bias that steers the probabilistic dynamics toward desired, domain-aligned behavior. Experiments compare trained models with and without the inductive bias components, investigating whether their presence improves the desired model behavior on transcripts involving never-before-seen students and a novel discussion context. Our results show that the inductive bias improves generalization -- supporting the claim that interpretability is built into the model for this task rather than imposed post hoc. We conclude with practical recommendations for STEM education researchers seeking to adopt the tool and for ML researchers aiming to extend the model's design. Overall, we hope this work encourages the development of mechanistically interpretable models that are understandable and controllable for both end users and model designers in STEM education research.
Using machine learning to measure evidence of students' sensemaking in physics courses
Mar 19, 2025In the education system, problem-solving correctness is often inappropriately conflated with student learning. Advances in both Physics Education Research (PER) and Machine Learning (ML) provide the initial tools to develop a more meaningful and efficient measurement scheme for whether physics students are engaging in sensemaking: a learning process of figuring out the how and why for a particular phenomena. In this work, we contribute such a measurement scheme, which quantifies the evidence of students' physical sensemaking given their written explanations for their solutions to physics problems. We outline how the proposed human annotation scheme can be automated into a deployable ML model using language encoders and shared probabilistic classifiers. The procedure is scalable for a large number of problems and students. We implement three unique language encoders with logistic regression, and provide a deployability analysis on 385 real student explanations from the 2023 Introduction to Physics course at Tufts University. Furthermore, we compute sensemaking scores for all students, and analyze these measurements alongside their corresponding problem-solving accuracies. We find no linear relationship between these two variables, supporting the hypothesis that one is not a reliable proxy for the other. We discuss how sensemaking scores can be used alongside problem-solving accuracies to provide a more nuanced snapshot of student performance in physics class.
Generative Modeling with Quantum Neurons
Feb 01, 2023
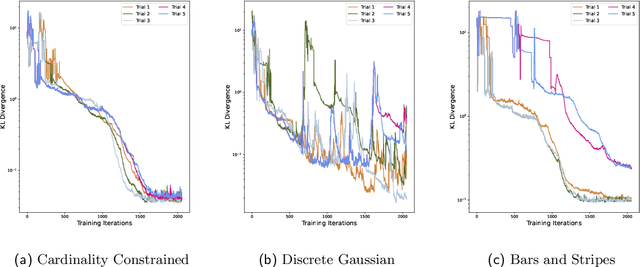
The recently proposed Quantum Neuron Born Machine (QNBM) has demonstrated quality initial performance as the first quantum generative machine learning (ML) model proposed with non-linear activations. However, previous investigations have been limited in scope with regards to the model's learnability and simulatability. In this work, we make a considerable leap forward by providing an extensive deep dive into the QNBM's potential as a generative model. We first demonstrate that the QNBM's network representation makes it non-trivial to be classically efficiently simulated. Following this result, we showcase the model's ability to learn (express and train on) a wider set of probability distributions, and benchmark the performance against a classical Restricted Boltzmann Machine (RBM). The QNBM is able to outperform this classical model on all distributions, even for the most optimally trained RBM among our simulations. Specifically, the QNBM outperforms the RBM with an improvement factor of 75.3x, 6.4x, and 3.5x for the discrete Gaussian, cardinality-constrained, and Bars and Stripes distributions respectively. Lastly, we conduct an initial investigation into the model's generalization capabilities and use a KL test to show that the model is able to approximate the ground truth probability distribution more closely than the training distribution when given access to a limited amount of data. Overall, we put forth a stronger case in support of using the QNBM for larger-scale generative tasks.
Do Quantum Circuit Born Machines Generalize?
Jul 27, 2022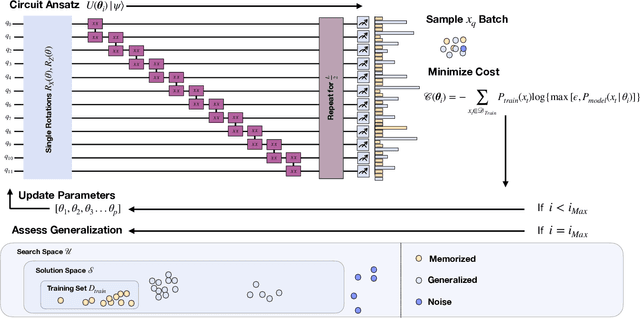
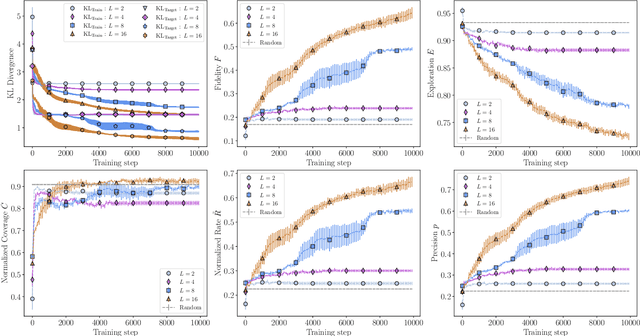
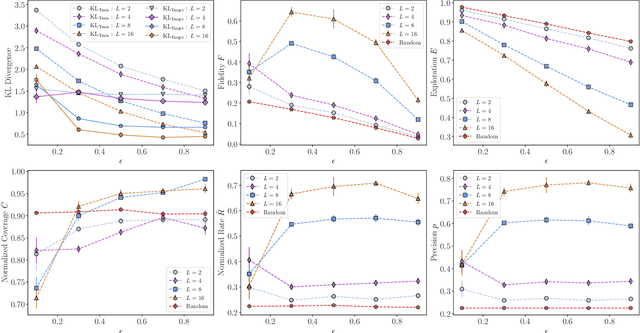
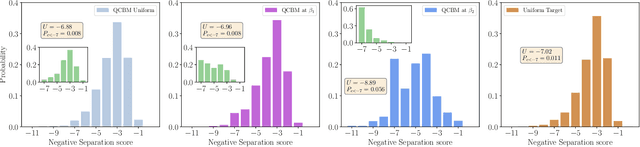
In recent proposals of quantum circuit models for generative tasks, the discussion about their performance has been limited to their ability to reproduce a known target distribution. For example, expressive model families such as Quantum Circuit Born Machines (QCBMs) have been almost entirely evaluated on their capability to learn a given target distribution with high accuracy. While this aspect may be ideal for some tasks, it limits the scope of a generative model's assessment to its ability to memorize data rather than generalize. As a result, there has been little understanding of a model's generalization performance and the relation between such capability and the resource requirements, e.g., the circuit depth and the amount of training data. In this work, we leverage upon a recently proposed generalization evaluation framework to begin addressing this knowledge gap. We first investigate the QCBM's learning process of a cardinality-constrained distribution and see an increase in generalization performance while increasing the circuit depth. In the 12-qubit example presented here, we observe that with as few as 30% of the valid patterns as the training set, the QCBM exhibits the best generalization performance toward generating unseen and valid patterns. Lastly, we assess the QCBM's ability to generalize not only to valid features, but to high-quality bitstrings distributed according to an adequately biased distribution. We see that the QCBM is able to effectively learn the bias and generate unseen samples with higher quality than those in the training set. To the best of our knowledge, this is the first work in the literature that presents the QCBM's generalization performance as an integral evaluation metric for quantum generative models, and demonstrates the QCBM's ability to generalize to high-quality, desired novel samples.
Introducing Non-Linearity into Quantum Generative Models
May 28, 2022


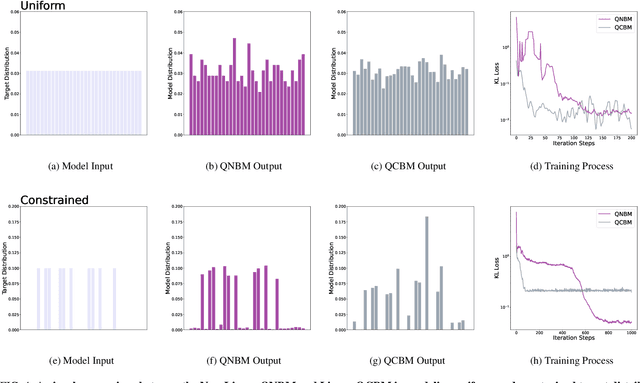
The evolution of an isolated quantum system is linear, and hence quantum algorithms are reversible, including those that utilize quantum circuits as generative machine learning models. However, some of the most successful classical generative models, such as those based on neural networks, involve highly non-linear and thus non-reversible dynamics. In this paper, we explore the effect of these dynamics in quantum generative modeling by introducing a model that adds non-linear activations via a neural network structure onto the standard Born Machine framework - the Quantum Neuron Born Machine (QNBM). To achieve this, we utilize a previously introduced Quantum Neuron subroutine, which is a repeat-until-success circuit with mid-circuit measurements and classical control. After introducing the QNBM, we investigate how its performance depends on network size, by training a 3-layer QNBM with 4 output neurons and various input and hidden layer sizes. We then compare our non-linear QNBM to the linear Quantum Circuit Born Machine (QCBM). We allocate similar time and memory resources to each model, such that the only major difference is the qubit overhead required by the QNBM. With gradient-based training, we show that while both models can easily learn a trivial uniform probability distribution, on a more challenging class of distributions, the QNBM achieves an almost 3x smaller error rate than a QCBM with a similar number of tunable parameters. We therefore show that non-linearity is a useful resource in quantum generative models, and we put forth the QNBM as a new model with good generative performance and potential for quantum advantage.
Evaluating Generalization in Classical and Quantum Generative Models
Jan 21, 2022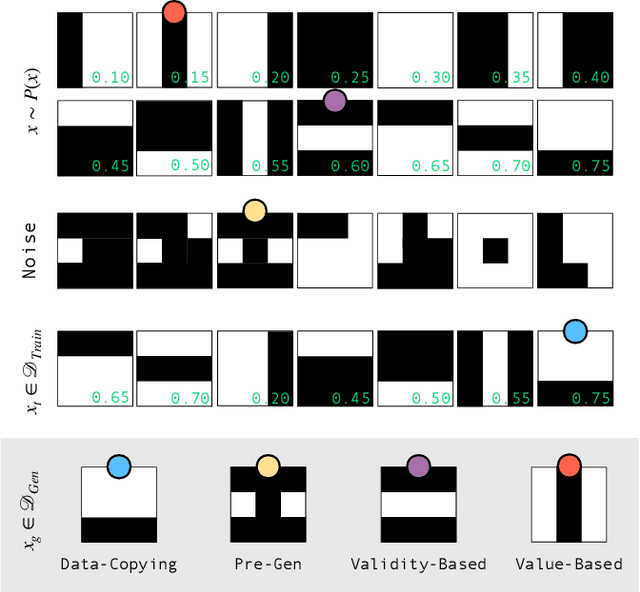
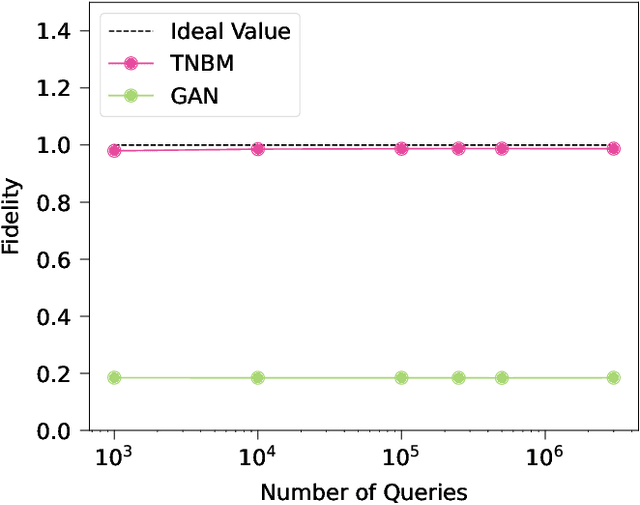
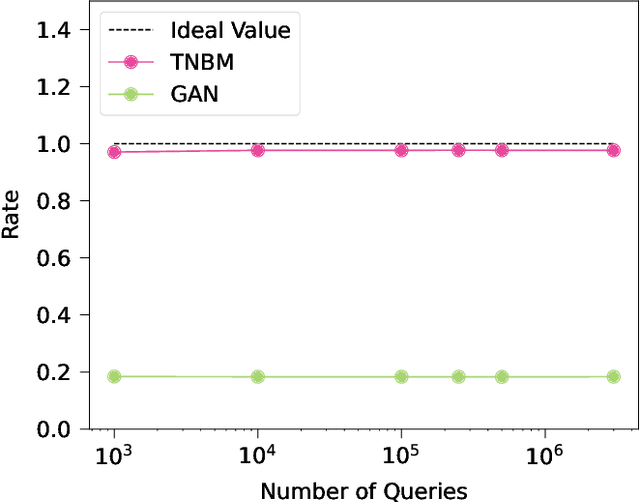
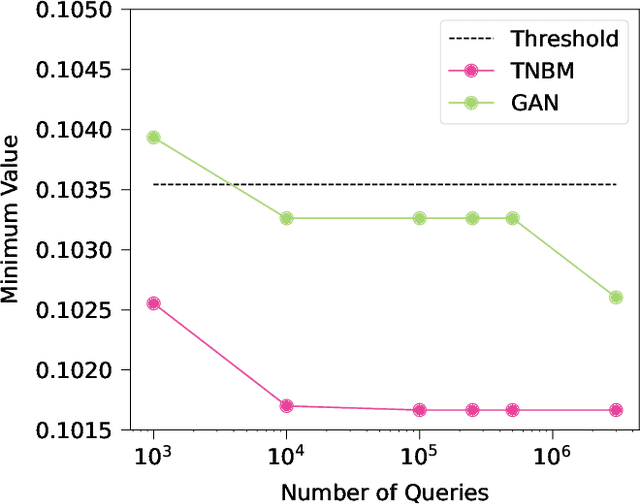
Defining and accurately measuring generalization in generative models remains an ongoing challenge and a topic of active research within the machine learning community. This is in contrast to discriminative models, where there is a clear definition of generalization, i.e., the model's classification accuracy when faced with unseen data. In this work, we construct a simple and unambiguous approach to evaluate the generalization capabilities of generative models. Using the sample-based generalization metrics proposed here, any generative model, from state-of-the-art classical generative models such as GANs to quantum models such as Quantum Circuit Born Machines, can be evaluated on the same ground on a concrete well-defined framework. In contrast to other sample-based metrics for probing generalization, we leverage constrained optimization problems (e.g., cardinality constrained problems) and use these discrete datasets to define specific metrics capable of unambiguously measuring the quality of the samples and the model's generalization capabilities for generating data beyond the training set but still within the valid solution space. Additionally, our metrics can diagnose trainability issues such as mode collapse and overfitting, as we illustrate when comparing GANs to quantum-inspired models built out of tensor networks. Our simulation results show that our quantum-inspired models have up to a $68 \times$ enhancement in generating unseen unique and valid samples compared to GANs, and a ratio of 61:2 for generating samples with better quality than those observed in the training set. We foresee these metrics as valuable tools for rigorously defining practical quantum advantage in the domain of generative modeling.
Long-time simulations with high fidelity on quantum hardware
Feb 08, 2021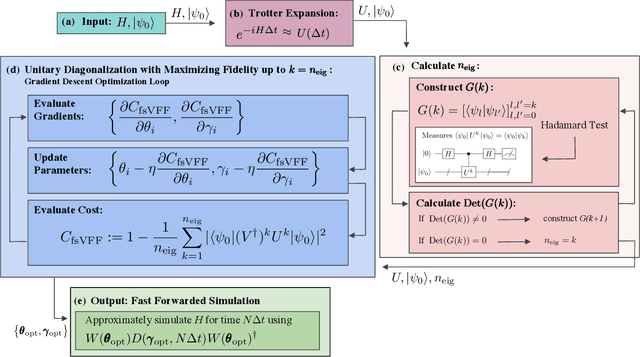
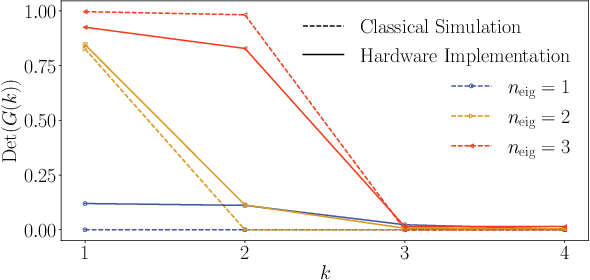

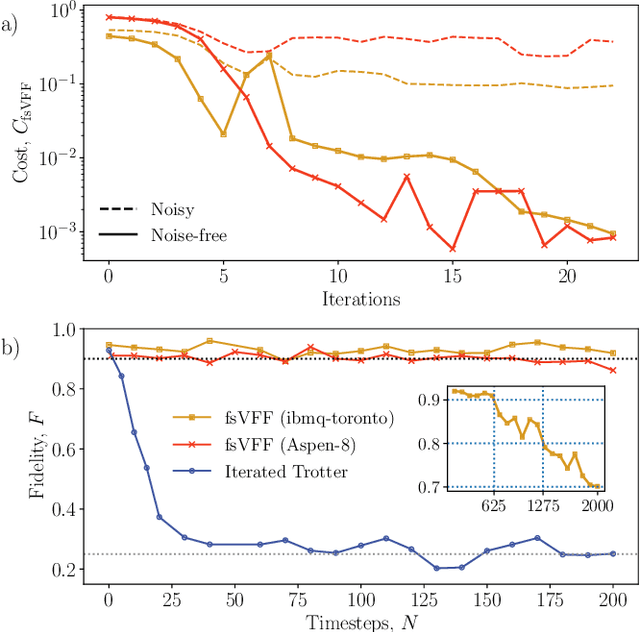
Moderate-size quantum computers are now publicly accessible over the cloud, opening the exciting possibility of performing dynamical simulations of quantum systems. However, while rapidly improving, these devices have short coherence times, limiting the depth of algorithms that may be successfully implemented. Here we demonstrate that, despite these limitations, it is possible to implement long-time, high fidelity simulations on current hardware. Specifically, we simulate an XY-model spin chain on the Rigetti and IBM quantum computers, maintaining a fidelity of at least 0.9 for over 600 time steps. This is a factor of 150 longer than is possible using the iterated Trotter method. Our simulations are performed using a new algorithm that we call the fixed state Variational Fast Forwarding (fsVFF) algorithm. This algorithm decreases the circuit depth and width required for a quantum simulation by finding an approximate diagonalization of a short time evolution unitary. Crucially, fsVFF only requires finding a diagonalization on the subspace spanned by the initial state, rather than on the total Hilbert space as with previous methods, substantially reducing the required resources.
Quantum Unsupervised and Supervised Learning on Superconducting Processors
Sep 10, 2019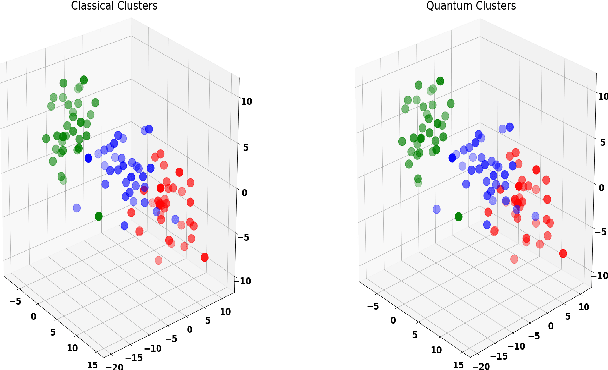
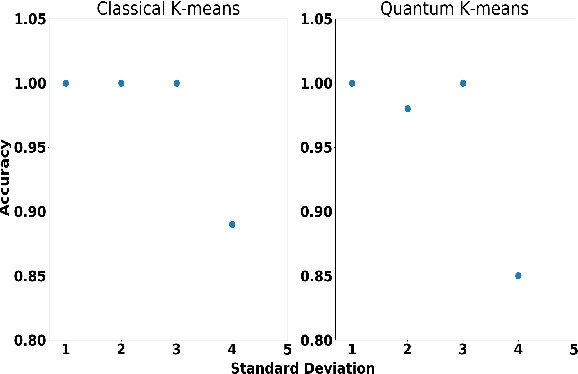
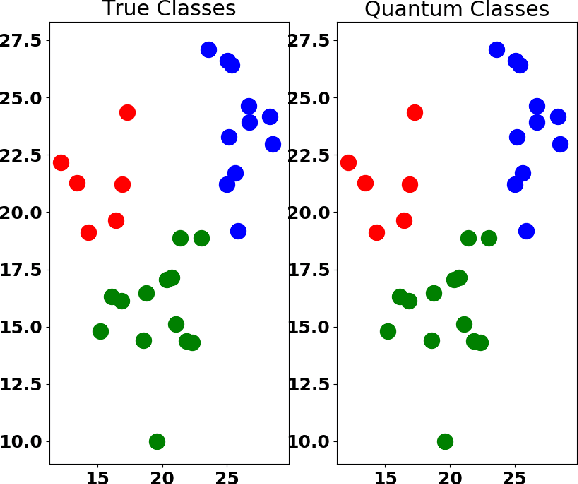
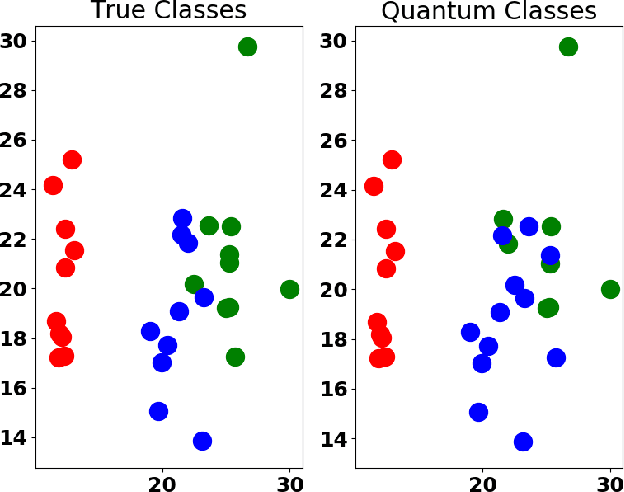
Machine learning algorithms perform well on identifying patterns in many datasets due to their versatility. However, as one increases the size of the data, the time for training and using these statistical models grows quickly. Here, we propose and implement on the IBMQ a quantum analogue to K-means clustering, and compare it to a previously developed quantum support vector machine. We find the algorithm's accuracy comparable to classical K-means for clustering and classification problems, and find that it becomes less computationally expensive to implement for large datasets.