 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generalization in Classical and Quantum Generative Models
Paper and Code
Jan 21, 2022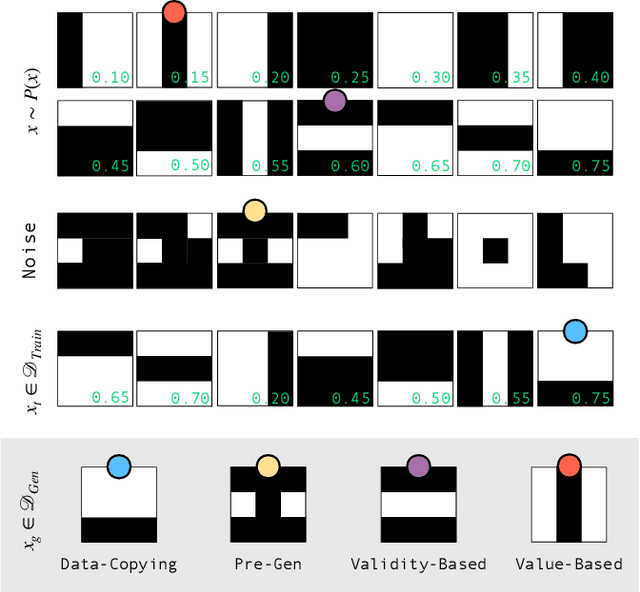
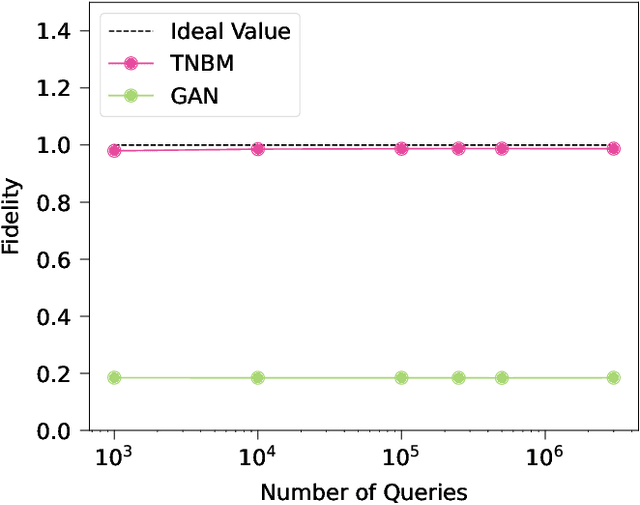
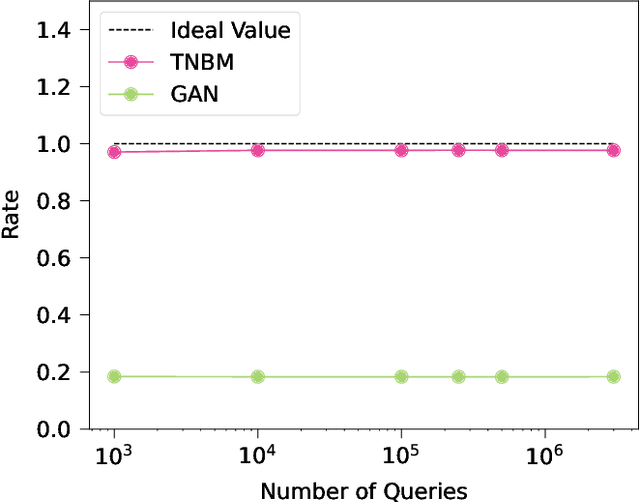
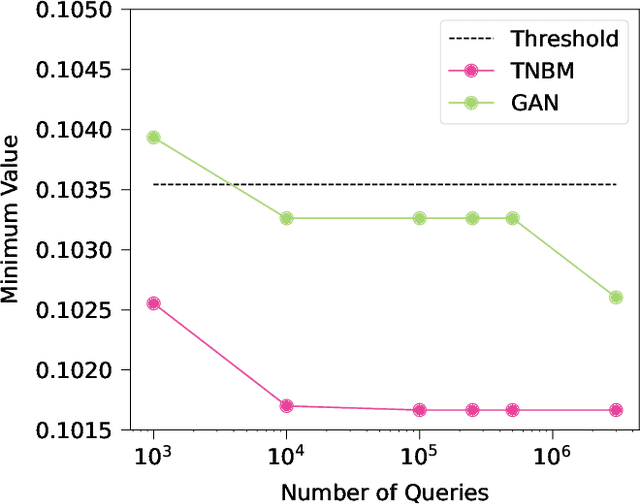
Defining and accurately measuring generalization in generative models remains an ongoing challenge and a topic of active research within the machine learning community. This is in contrast to discriminative models, where there is a clear definition of generalization, i.e., the model's classification accuracy when faced with unseen data. In this work, we construct a simple and unambiguous approach to evaluate the generalization capabilities of generative models. Using the sample-based generalization metrics proposed here, any generative model, from state-of-the-art classical generative models such as GANs to quantum models such as Quantum Circuit Born Machines, can be evaluated on the same ground on a concrete well-defined framework. In contrast to other sample-based metrics for probing generalization, we leverage constrained optimization problems (e.g., cardinality constrained problems) and use these discrete datasets to define specific metrics capable of unambiguously measuring the quality of the samples and the model's generalization capabilities for generating data beyond the training set but still within the valid solution space. Additionally, our metrics can diagnose trainability issues such as mode collapse and overfitting, as we illustrate when comparing GANs to quantum-inspired models built out of tensor networks. Our simulation results show that our quantum-inspired models have up to a $68 \times$ enhancement in generating unseen unique and valid samples compared to GANs, and a ratio of 61:2 for generating samples with better quality than those observed in the training set. We foresee these metrics as valuable tools for rigorously defining practical quantum advantage in the domain of generative modeling.