 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Demonstrating Practical Quantum Advantage: Racing Quantum against Classical Generative Models
Mar 27, 2023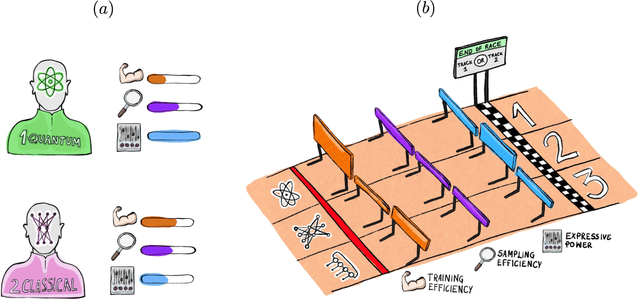
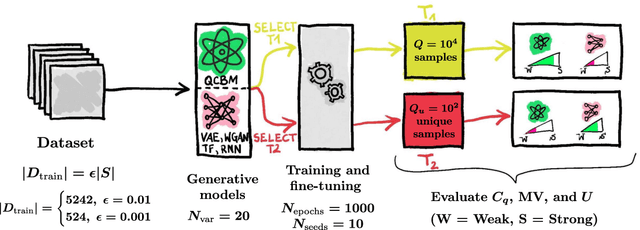

Generative modeling has seen a rising interest in both classical and quantum machine learning, and it represents a promising candidate to obtain a practical quantum advantage in the near term. In this study, we build over a proposed framework for evaluating the generalization performance of generative models, and we establish the first quantitative comparative race towards practical quantum advantage (PQA) between classical and quantum generative models, namely Quantum Circuit Born Machines (QCBMs), Transformers (TFs), Recurrent Neural Networks (RNNs), Variational Autoencoders (VAEs), and Wasserstein Generative Adversarial Networks (WGANs). After defining four types of PQAs scenarios, we focus on what we refer to as potential PQA, aiming to compare quantum models with the best-known classical algorithms for the task at hand. We let the models race on a well-defined and application-relevant competition setting, where we illustrate and demonstrate our framework on 20 variables (qubits) generative modeling task. Our results suggest that QCBMs are more efficient in the data-limited regime than the other state-of-the-art classical generative models. Such a feature is highly desirable in a wide range of real-world applications where the available data is scarce.
Do Quantum Circuit Born Machines Generalize?
Jul 27, 2022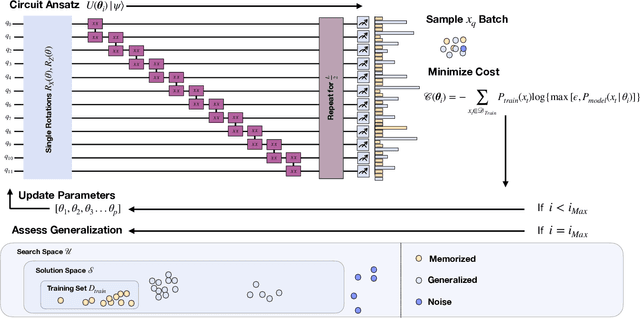
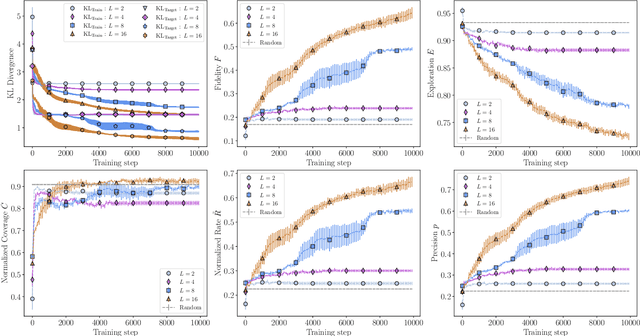
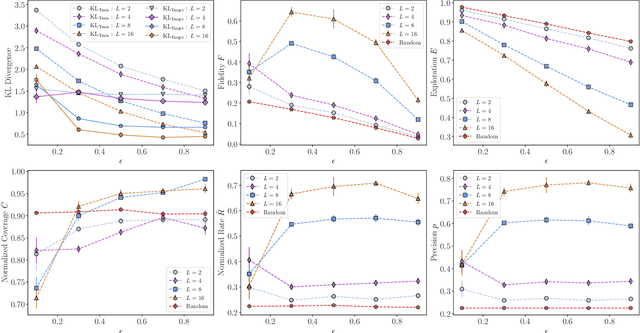
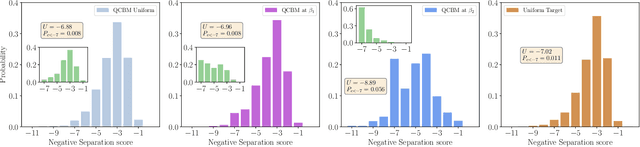
In recent proposals of quantum circuit models for generative tasks, the discussion about their performance has been limited to their ability to reproduce a known target distribution. For example, expressive model families such as Quantum Circuit Born Machines (QCBMs) have been almost entirely evaluated on their capability to learn a given target distribution with high accuracy. While this aspect may be ideal for some tasks, it limits the scope of a generative model's assessment to its ability to memorize data rather than generalize. As a result, there has been little understanding of a model's generalization performance and the relation between such capability and the resource requirements, e.g., the circuit depth and the amount of training data. In this work, we leverage upon a recently proposed generalization evaluation framework to begin addressing this knowledge gap. We first investigate the QCBM's learning process of a cardinality-constrained distribution and see an increase in generalization performance while increasing the circuit depth. In the 12-qubit example presented here, we observe that with as few as 30% of the valid patterns as the training set, the QCBM exhibits the best generalization performance toward generating unseen and valid patterns. Lastly, we assess the QCBM's ability to generalize not only to valid features, but to high-quality bitstrings distributed according to an adequately biased distribution. We see that the QCBM is able to effectively learn the bias and generate unseen samples with higher quality than those in the training set. To the best of our knowledge, this is the first work in the literature that presents the QCBM's generalization performance as an integral evaluation metric for quantum generative models, and demonstrates the QCBM's ability to generalize to high-quality, desired novel samples.
Evaluating Generalization in Classical and Quantum Generative Models
Jan 21, 2022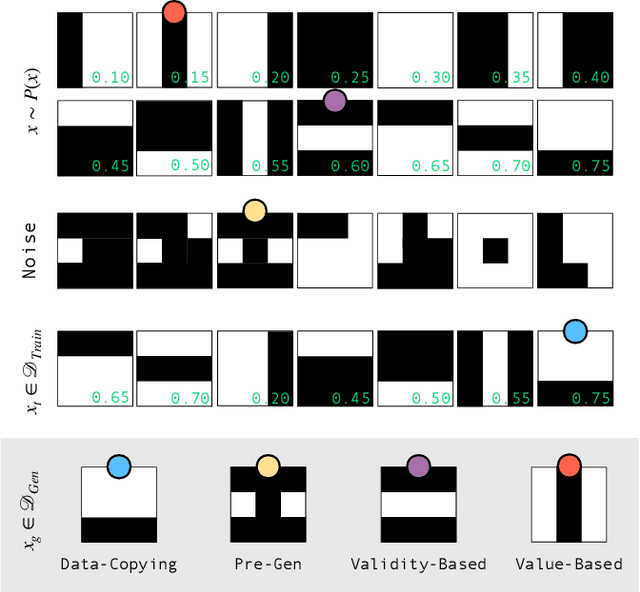
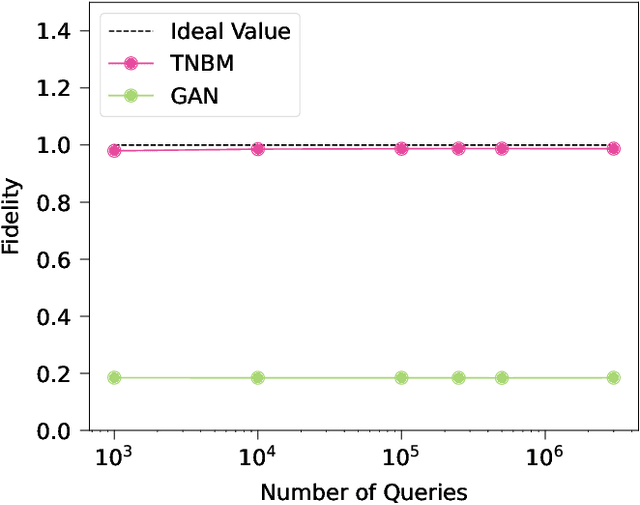
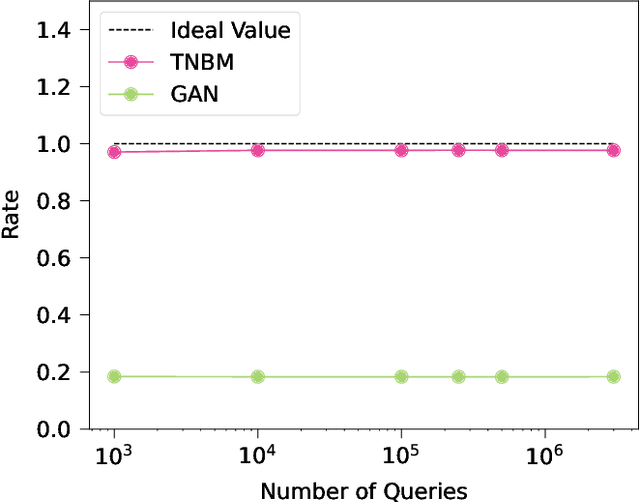
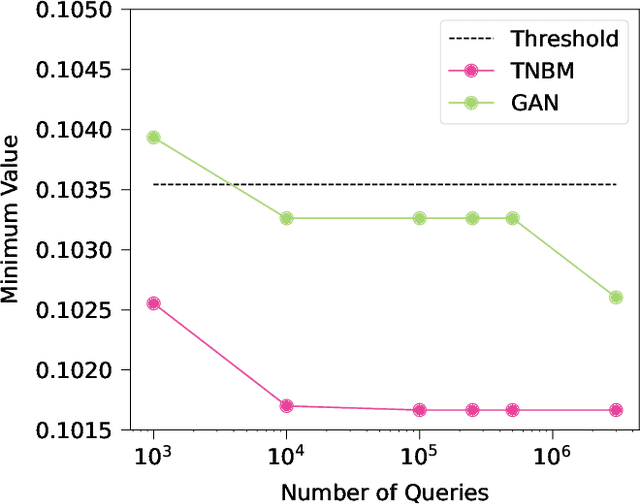
Defining and accurately measuring generalization in generative models remains an ongoing challenge and a topic of active research within the machine learning community. This is in contrast to discriminative models, where there is a clear definition of generalization, i.e., the model's classification accuracy when faced with unseen data. In this work, we construct a simple and unambiguous approach to evaluate the generalization capabilities of generative models. Using the sample-based generalization metrics proposed here, any generative model, from state-of-the-art classical generative models such as GANs to quantum models such as Quantum Circuit Born Machines, can be evaluated on the same ground on a concrete well-defined framework. In contrast to other sample-based metrics for probing generalization, we leverage constrained optimization problems (e.g., cardinality constrained problems) and use these discrete datasets to define specific metrics capable of unambiguously measuring the quality of the samples and the model's generalization capabilities for generating data beyond the training set but still within the valid solution space. Additionally, our metrics can diagnose trainability issues such as mode collapse and overfitting, as we illustrate when comparing GANs to quantum-inspired models built out of tensor networks. Our simulation results show that our quantum-inspired models have up to a $68 \times$ enhancement in generating unseen unique and valid samples compared to GANs, and a ratio of 61:2 for generating samples with better quality than those observed in the training set. We foresee these metrics as valuable tools for rigorously defining practical quantum advantage in the domain of generative modeling.