 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Retrieval Barrier: Indirect Prompt Injection in the Wild for LLM Systems
Jan 11, 2026Large language models (LLMs) increasingly rely on retrieving information from external corpora. This creates a new attack surface: indirect prompt injection (IPI), where hidden instructions are planted in the corpora and hijack model behavior once retrieved. Previous studies have highlighted this risk but often avoid the hardest step: ensuring that malicious content is actually retrieved. In practice, unoptimized IPI is rarely retrieved under natural queries, which leaves its real-world impact unclear. We address this challenge by decomposing the malicious content into a trigger fragment that guarantees retrieval and an attack fragment that encodes arbitrary attack objectives. Based on this idea, we design an efficient and effective black-box attack algorithm that constructs a compact trigger fragment to guarantee retrieval for any attack fragment. Our attack requires only API access to embedding models, is cost-efficient (as little as $0.21 per target user query on OpenAI's embedding models), and achieves near-100% retrieval across 11 benchmarks and 8 embedding models (including both open-source models and proprietary services). Based on this attack, we present the first end-to-end IPI exploits under natural queries and realistic external corpora, spanning both RAG and agentic systems with diverse attack objectives. These results establish IPI as a practical and severe threat: when a user issued a natural query to summarize emails on frequently asked topics, a single poisoned email was sufficient to coerce GPT-4o into exfiltrating SSH keys with over 80% success in a multi-agent workflow. We further evaluate several defenses and find that they are insufficient to prevent the retrieval of malicious text, highlighting retrieval as a critical open vulnerability.
Exposing Hidden Interfaces: LLM-Guided Type Inference for Reverse Engineering macOS Private Frameworks
Jan 04, 2026Private macOS frameworks underpin critical services and daemons but remain undocumented and distributed only as stripped binaries, complicating security analysis. We present MOTIF, an agentic framework that integrates tool-augmented analysis with a finetuned large language model specialized for Objective-C type inference. The agent manages runtime metadata extraction, binary inspection, and constraint checking, while the model generates candidate method signatures that are validated and refined into compilable headers. On MOTIF-Bench, a benchmark built from public frameworks with groundtruth headers, MOTIF improves signature recovery from 15% to 86% compared to baseline static analysis tooling, with consistent gains in tool-use correctness and inference stability. Case studies on private frameworks show that reconstructed headers compile, link, and facilitate downstream security research and vulnerability studies. By transforming opaque binaries into analyzable interfaces, MOTIF establishes a scalable foundation for systematic auditing of macOS internals.
DeBackdoor: A Deductive Framework for Detecting Backdoor Attacks on Deep Models with Limited Data
Mar 27, 2025


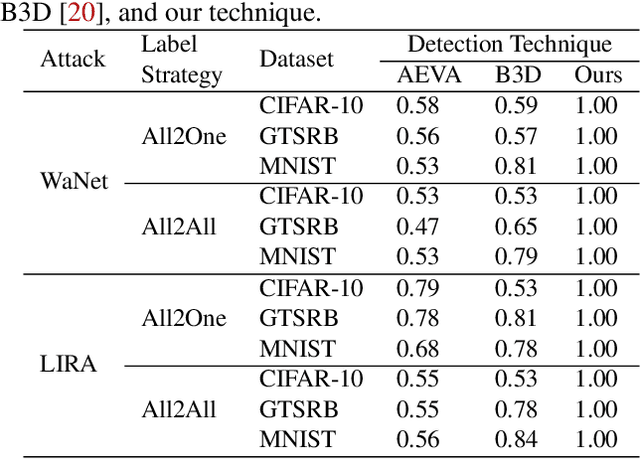
Backdoor attacks are among the most effective, practical, and stealthy attacks in deep learning. In this paper, we consider a practical scenario where a developer obtains a deep model from a third party and uses it as part of a safety-critical system. The developer wants to inspect the model for potential backdoors prior to system deployment. We find that most existing detection techniques make assumptions that are not applicable to this scenario. In this paper, we present a novel framework for detecting backdoors under realistic restrictions. We generate candidate triggers by deductively searching over the space of possible triggers. We construct and optimize a smoothed version of Attack Success Rate as our search objective. Starting from a broad class of template attacks and just using the forward pass of a deep model, we reverse engineer the backdoor attack. We conduct extensive evaluation on a wide range of attacks, models, and datasets, with our technique performing almost perfectly across these settings.
Domain-specific Guided Summarization for Mental Health Posts
Nov 03, 2024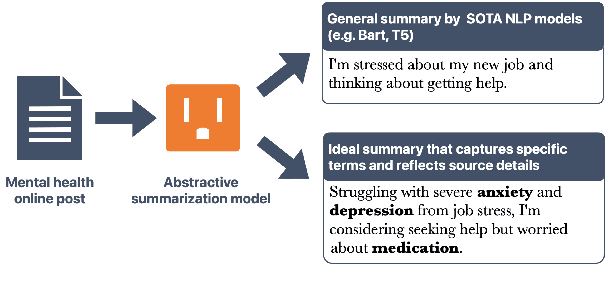



In domain-specific contexts, particularly mental health, abstractive summarization requires advanced techniques adept at handling specialized content to generate domain-relevant and faithful summaries. In response to this, we introduce a guided summarizer equipped with a dual-encoder and an adapted decoder that utilizes novel domain-specific guidance signals, i.e., mental health terminologies and contextually rich sentences from the source document, to enhance its capacity to align closely with the content and context of guidance, thereby generating a domain-relevant summary. Additionally, we present a post-editing correction model to rectify errors in the generated summary, thus enhancing its consistency with the original content in detail. Evaluation on the MentSum dataset reveals that our model outperforms existing baseline models in terms of both ROUGE and FactCC scores. Although the experiments are specifically designed for mental health posts, the methodology we've developed offers broad applicability, highlighting its versatility and effectiveness in producing high-quality domain-specific summaries.
Prompting Video-Language Foundation Models with Domain-specific Fine-grained Heuristics for Video Question Answering
Oct 12, 2024



Video Question Answering (VideoQA) represents a crucial intersection between video understanding and language processing, requiring both discriminative unimodal comprehension and sophisticated cross-modal interaction for accurate inference. Despite advancements in multi-modal pre-trained models and video-language foundation models, these systems often struggle with domain-specific VideoQA due to their generalized pre-training objectives. Addressing this gap necessitates bridging the divide between broad cross-modal knowledge and the specific inference demands of VideoQA tasks. To this end, we introduce HeurVidQA, a framework that leverages domain-specific entity-action heuristics to refine pre-trained video-language foundation models. Our approach treats these models as implicit knowledge engines, employing domain-specific entity-action prompters to direct the model's focus toward precise cues that enhance reasoning. By delivering fine-grained heuristics, we improve the model's ability to identify and interpret key entities and actions, thereby enhancing its reasoning capabilities. Extensive evaluations across multiple VideoQA datasets demonstrate that our method significantly outperforms existing models, underscoring the importance of integrating domain-specific knowledge into video-language models for more accurate and context-aware VideoQA.
* IEEE Transactions on Circuits and Systems for Video Technology
Multi-granularity Contrastive Cross-modal Collaborative Generation for End-to-End Long-term Video Question Answering
Oct 12, 2024


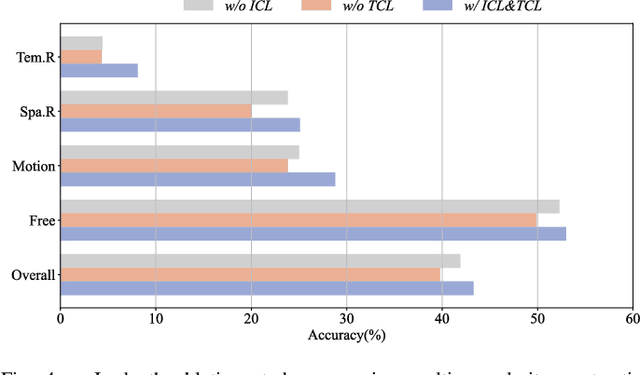
Long-term Video Question Answering (VideoQA) is a challenging vision-and-language bridging task focusing on semantic understanding of untrimmed long-term videos and diverse free-form questions, simultaneously emphasizing comprehensive cross-modal reasoning to yield precise answers. The canonical approaches often rely on off-the-shelf feature extractors to detour the expensive computation overhead, but often result in domain-independent modality-unrelated representations. Furthermore, the inherent gradient blocking between unimodal comprehension and cross-modal interaction hinders reliable answer generation. In contrast, recent emerging successful video-language pre-training models enable cost-effective end-to-end modeling but fall short in domain-specific ratiocination and exhibit disparities in task formulation. Toward this end, we present an entirely end-to-end solution for long-term VideoQA: Multi-granularity Contrastive cross-modal collaborative Generation (MCG) model. To derive discriminative representations possessing high visual concepts, we introduce Joint Unimodal Modeling (JUM) on a clip-bone architecture and leverage Multi-granularity Contrastive Learning (MCL) to harness the intrinsically or explicitly exhibited semantic correspondences. To alleviate the task formulation discrepancy problem, we propose a Cross-modal Collaborative Generation (CCG) module to reformulate VideoQA as a generative task instead of the conventional classification scheme, empowering the model with the capability for cross-modal high-semantic fusion and generation so as to rationalize and answer. Extensive experiments conducted on six publicly available VideoQA datasets underscore the superiority of our proposed method.
* Transactions on Image Processing
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Large Language Models for Cyber Security: A Systematic Literature Review
May 08, 2024
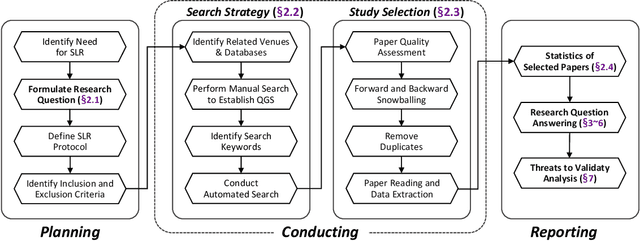


The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
A Comprehensive Survey of 3D Dense Captioning: Localizing and Describing Objects in 3D Scenes
Mar 12, 2024



Three-Dimensional (3D) dense captioning is an emerging vision-language bridging task that aims to generate multiple detailed and accurate descriptions for 3D scenes. It presents significant potential and challenges due to its closer representation of the real world compared to 2D visual captioning, as well as complexities in data collection and processing of 3D point cloud sources. Despite the popularity and success of existing methods, there is a lack of comprehensive surveys summarizing the advancements in this field, which hinders its progress. In this paper, we provide a comprehensive review of 3D dense captioning, covering task definition, architecture classification, dataset analysis, evaluation metrics, and in-depth prosperity discussions. Based on a synthesis of previous literature, we refine a standard pipeline that serves as a common paradigm for existing methods. We also introduce a clear taxonomy of existing models, summarize technologies involved in different modules, and conduct detailed experiment analysis. Instead of a chronological order introduction, we categorize the methods into different classes to facilitate exploration and analysis of the differences and connections among existing techniques. We also provide a reading guideline to assist readers with different backgrounds and purposes in reading efficiently. Furthermore, we propose a series of promising future directions for 3D dense captioning by identifying challenges and aligning them with the development of related tasks, offering valuable insights and inspiring future research in this field. Our aim is to provide a comprehensive understanding of 3D dense captioning, foster further investigations, and contribute to the development of novel applications in multimedia and related domains.