 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining deep physical neural networks with local physical information bottleneck
Feb 10, 2026Deep learning has revolutionized modern society but faces growing energy and latency constraints. Deep physical neural networks (PNNs) are interconnected computing systems that directly exploit analog dynamics for energy-efficient, ultrafast AI execution. Realizing this potential, however, requires universal training methods tailored to physical intricacies. Here, we present the Physical Information Bottleneck (PIB), a general and efficient framework that integrates information theory and local learning, enabling deep PNNs to learn under arbitrary physical dynamics. By allocating matrix-based information bottlenecks to each unit, we demonstrate supervised, unsupervised, and reinforcement learning across electronic memristive chips and optical computing platforms. PIB also adapts to severe hardware faults and allows for parallel training via geographically distributed resources. Bypassing auxiliary digital models and contrastive measurements, PIB recasts PNN training as an intrinsic, scalable information-theoretic process compatible with diverse physical substrates.
Training of Physical Neural Networks
Jun 05, 2024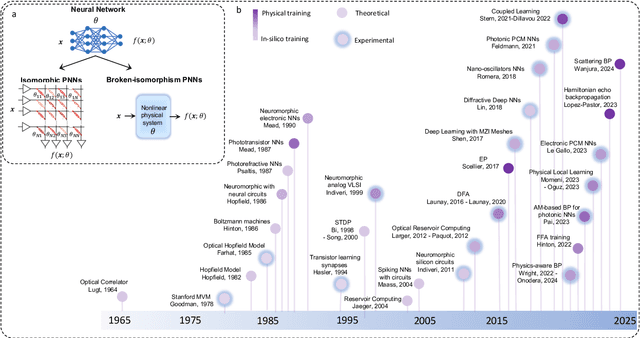
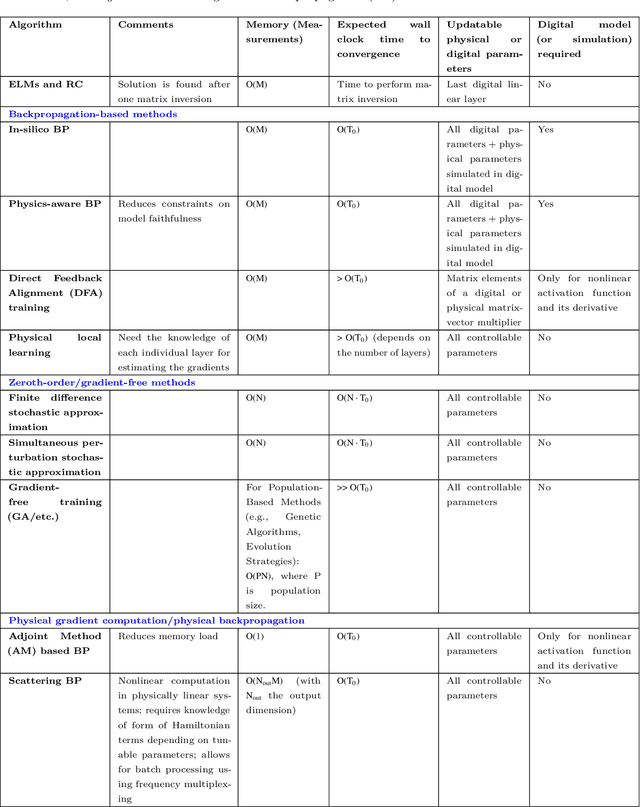
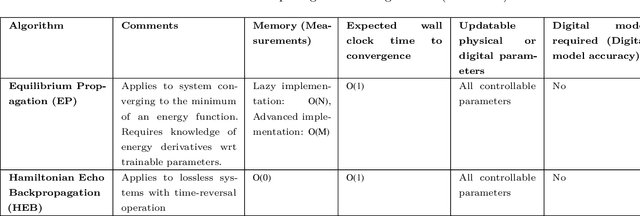
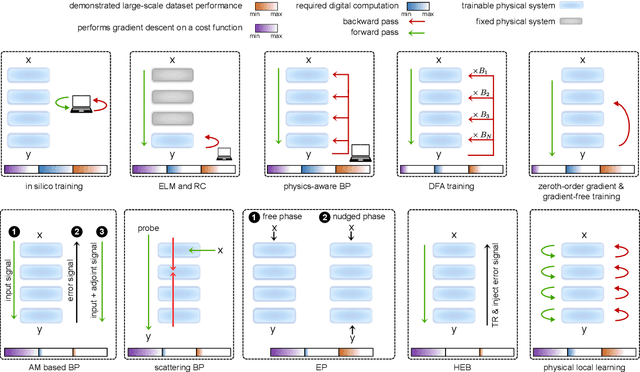
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Deep Learning with Passive Optical Nonlinear Mapping
Jul 18, 2023Deep learning has fundamentally transformed artificial intelligence, but the ever-increasing complexity in deep learning models calls for specialized hardware accelerators. Optical accelerators can potentially offer enhanced performance, scalability, and energy efficiency. However, achieving nonlinear mapping, a critical component of neural networks, remains challenging optically. Here, we introduce a design that leverages multiple scattering in a reverberating cavity to passively induce optical nonlinear random mapping, without the need for additional laser power. A key advantage emerging from our work is that we show we can perform optical data compression, facilitated by multiple scattering in the cavity, to efficiently compress and retain vital information while also decreasing data dimensionality. This allows rapid optical information processing and generation of low dimensional mixtures of highly nonlinear features. These are particularly useful for applications demanding high-speed analysis and responses such as in edge computing devices. Utilizing rapid optical information processing capabilities, our optical platforms could potentially offer more efficient and real-time processing solutions for a broad range of applications. We demonstrate the efficacy of our design in improving computational performance across tasks, including classification, image reconstruction, key-point detection, and object detection, all achieved through optical data compression combined with a digital decoder. Notably, we observed high performance, at an extreme compression ratio, for real-time pedestrian detection. Our findings pave the way for novel algorithms and architectural designs for optical computing.
Intelligent Computing: The Latest Advances, Challenges and Future
Nov 21, 2022Computing is a critical driving force in the development of human civilization. In recent years, we have witnessed the emergence of intelligent computing, a new computing paradigm that is reshaping traditional computing and promoting digital revolution in the era of big data, artificial intelligence and internet-of-things with new computing theories, architectures, methods, systems, and applications. Intelligent computing has greatly broadened the scope of computing, extending it from traditional computing on data to increasingly diverse computing paradigms such as perceptual intelligence, cognitive intelligence, autonomous intelligence, and human-computer fusion intelligence. Intelligence and computing have undergone paths of different evolution and development for a long time but have become increasingly intertwined in recent years: intelligent computing is not only intelligence-oriented but also intelligence-driven. Such cross-fertilization has prompted the emergence and rapid advancement of intelligent computing. Intelligent computing is still in its infancy and an abundance of innovations in the theories, systems, and applications of intelligent computing are expected to occur soon. We present the first comprehensive survey of literature on intelligent computing, covering its theory fundamentals, the technological fusion of intelligence and computing, important applications, challenges, and future perspectives. We believe that this survey is highly timely and will provide a comprehensive reference and cast valuable insights into intelligent computing for academic and industrial researchers and practitioners.
Online learning of the transfer matrix of dynamic scattering media: wavefront shaping meets multidimensional time series
Oct 08, 2022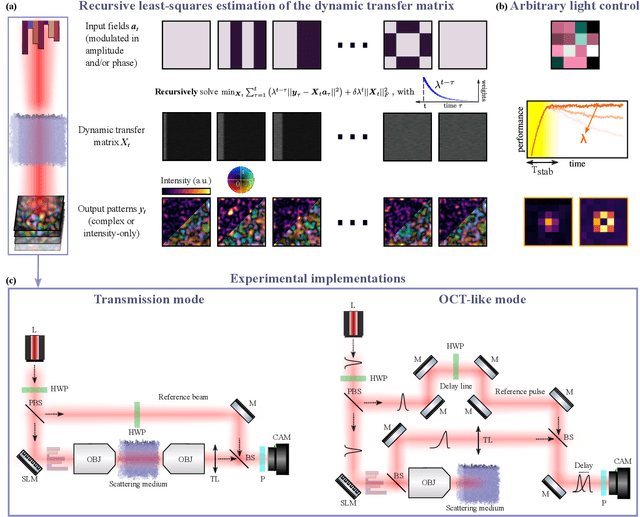
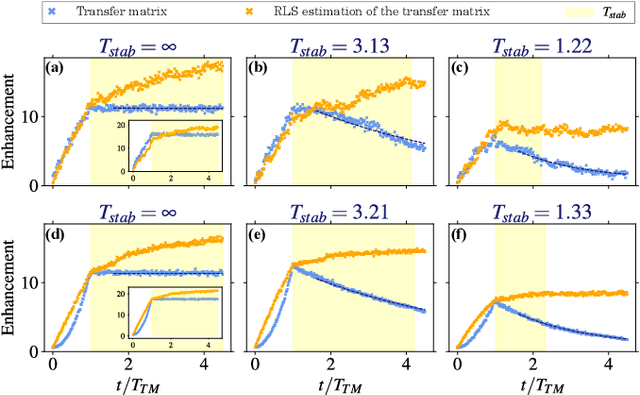
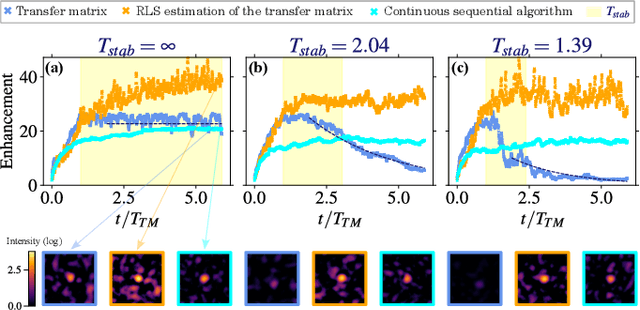
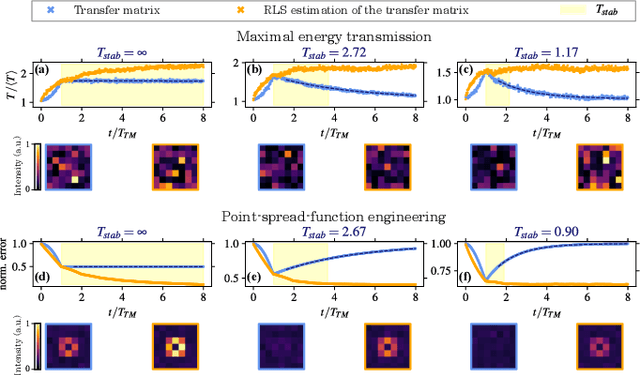
Thanks to the latest advancements in wavefront shaping, optical methods have proven crucial to achieve imaging and control light in multiply scattering media, like biological tissues. However, the stability times of living biological specimens often prevent such methods from gaining insights into relevant functioning mechanisms in cellular and organ systems. Here we present a recursive and online optimization routine, borrowed from time series analysis, to optimally track the transfer matrix of dynamic scattering media over arbitrarily long timescales. While preserving the advantages of both optimization-based routines and transfer-matrix measurements, it operates in a memory-efficient manner. Because it can be readily implemented in existing wavefront shaping setups, featuring amplitude and/or phase modulation and phase-resolved or intensity-only acquisition, it paves the way for efficient optical investigations of living biological specimens.
Physics-based neural network for non-invasive control of coherent light in scattering media
Jun 01, 2022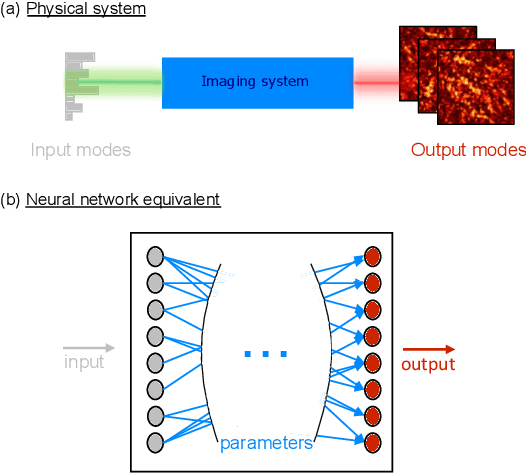

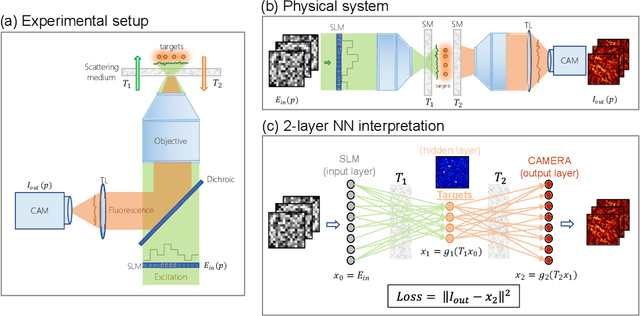
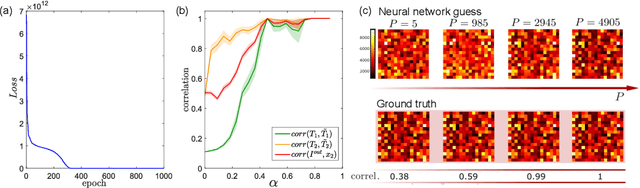
Optical imaging through complex media, such as biological tissues or fog, is challenging due to light scattering. In the multiple scattering regime, wavefront shaping provides an effective method to retrieve information; it relies on measuring how the propagation of different optical wavefronts are impacted by scattering. Based on this principle, several wavefront shaping techniques were successfully developed, but most of them are highly invasive and limited to proof-of-principle experiments. Here, we propose to use a neural network approach to non-invasively characterize and control light scattering inside the medium and also to retrieve information of hidden objects buried within it. Unlike most of the recently-proposed approaches, the architecture of our neural network with its layers, connected nodes and activation functions has a true physical meaning as it mimics the propagation of light in our optical system. It is trained with an experimentally-measured input/output dataset built from a series of incident light patterns and corresponding camera snapshots. We apply our physics-based neural network to a fluorescence microscope in epi-configuration and demonstrate its performance through numerical simulations and experiments. This flexible method can include physical priors and we show that it can be applied to other systems as, for example, non-linear or coherent contrast mechanisms.
Large field-of-view non-invasive imaging through scattering layers using fluctuating random illumination
Jul 17, 2021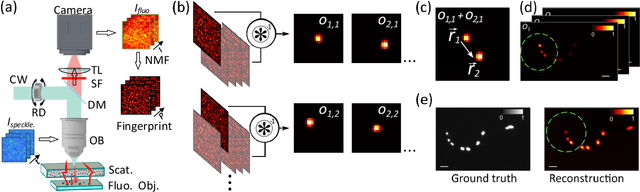


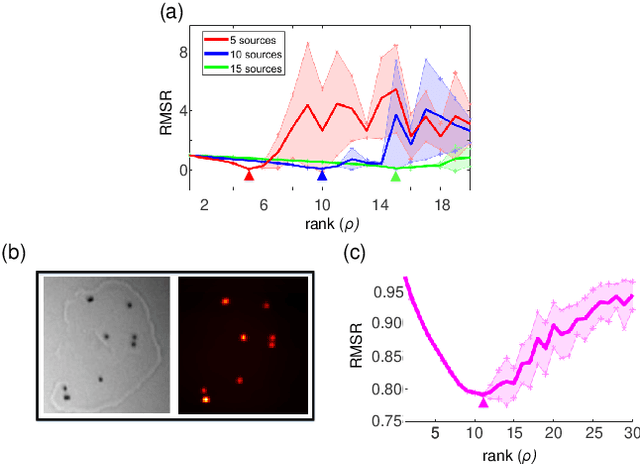
On-invasive optical imaging techniques are essential diagnostic tools in many fields. Although various recent methods have been proposed to utilize and control light in multiple scattering media, non-invasive optical imaging through and inside scattering layers across a large field of view remains elusive due to the physical limits set by the optical memory effect, especially without wavefront shaping techniques. Here, we demonstrate an approach that enables non-invasive fluorescence imaging behind scattering layers with field-of-views extending well beyond the optical memory effect. The method consists in demixing the speckle patterns emitted by a fluorescent object under variable unknown random illumination, using matrix factorization and a novel fingerprint-based reconstruction. Experimental validation shows the efficiency and robustness of the method with various fluorescent samples, covering a field of view up to three times the optical memory effect range. Our non-invasive imaging technique is simple, neither requires a spatial light modulator nor a guide star, and can be generalized to a wide range of incoherent contrast mechanisms and illumination schemes.
Deeply Sub-Wavelength Localization with Reverberation-Coded-Aperture
Feb 10, 2021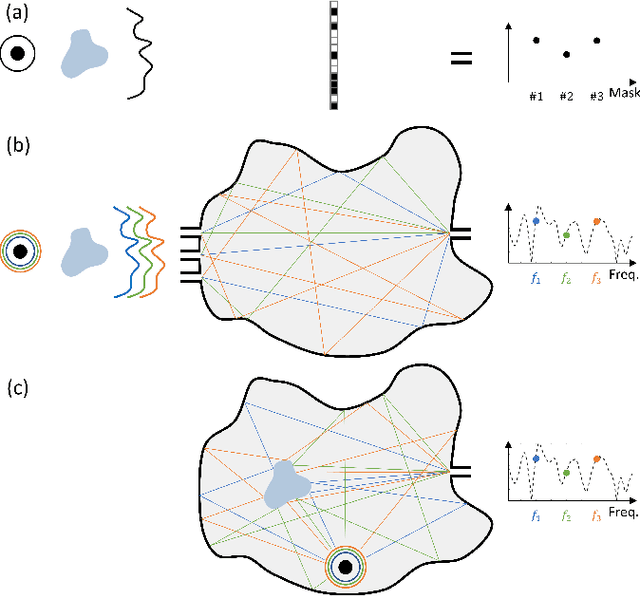
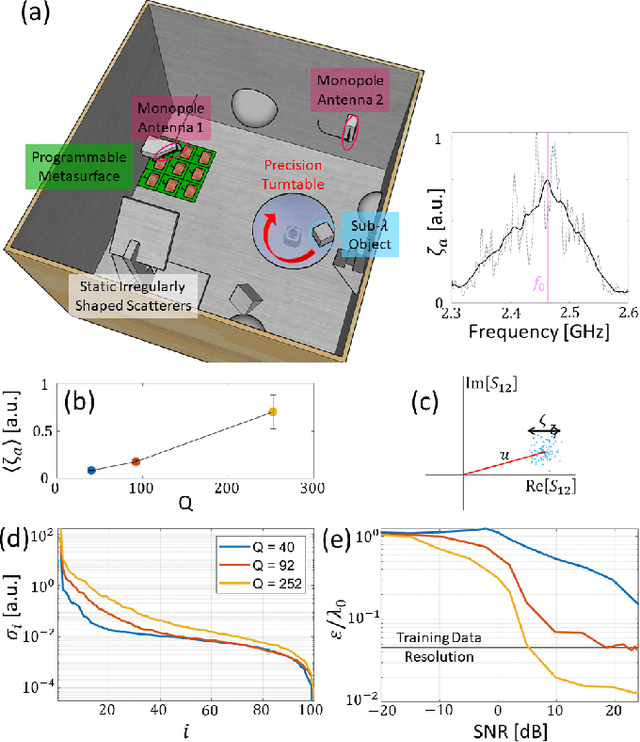
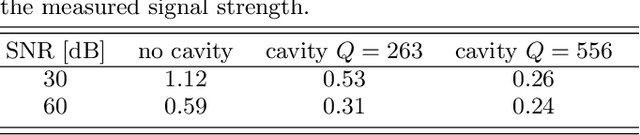
Accessing sub-wavelength information about a scene from the far-field without invasive near-field manipulations is a fundamental challenge in wave engineering. Yet it is well understood that the dwell time of waves in complex media sets the scale for the waves' sensitivity to perturbations. Modern coded-aperture imagers leverage the degrees of freedom (DoF) offered by complex media as natural multiplexor but do not recognize and reap the fundamental difference between placing the object of interest outside or within the complex medium. Here, we show that the precision of localizing a sub-wavelength object can be improved by several orders of magnitude simply by enclosing it in its far field with a reverberant chaotic cavity. We identify deep learning as suitable noise-robust tool to extract sub-wavelength information encoded in multiplexed measurements, achieving resolutions well beyond those available in the training data. We demonstrate our finding in the microwave domain: harnessing the configurational DoF of a simple programmable metasurface, we localize a sub-wavelength object inside a chaotic cavity with a resolution of $\lambda/76$ using intensity-only single-frequency single-pixel measurements. Our results may have important applications in photoacoustic imaging as well as human-machine interaction based on reverberating elastic waves, sound or microwaves.
Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment
Dec 11, 2020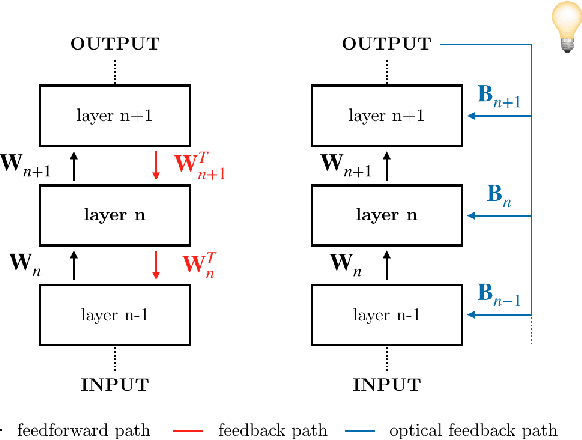


The scaling hypothesis motivates the expansion of models past trillions of parameters as a path towards better performance. Recent significant developments, such as GPT-3, have been driven by this conjecture. However, as models scale-up, training them efficiently with backpropagation becomes difficult. Because model, pipeline, and data parallelism distribute parameters and gradients over compute nodes, communication is challenging to orchestrate: this is a bottleneck to further scaling. In this work, we argue that alternative training methods can mitigate these issues, and can inform the design of extreme-scale training hardware. Indeed, using a synaptically asymmetric method with a parallelizable backward pass, such as Direct Feedback Alignement, communication needs are drastically reduced. We present a photonic accelerator for Direct Feedback Alignment, able to compute random projections with trillions of parameters. We demonstrate our system on benchmark tasks, using both fully-connected and graph convolutional networks. Our hardware is the first architecture-agnostic photonic co-processor for training neural networks. This is a significant step towards building scalable hardware, able to go beyond backpropagation, and opening new avenues for deep learning.
Light-in-the-loop: using a photonics co-processor for scalable training of neural networks
Jun 03, 2020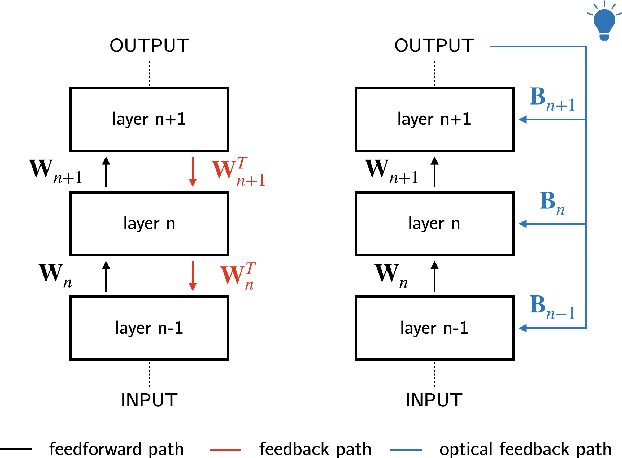
As neural networks grow larger and more complex and data-hungry, training costs are skyrocketing. Especially when lifelong learning is necessary, such as in recommender systems or self-driving cars, this might soon become unsustainable. In this study, we present the first optical co-processor able to accelerate the training phase of digitally-implemented neural networks. We rely on direct feedback alignment as an alternative to backpropagation, and perform the error projection step optically. Leveraging the optical random projections delivered by our co-processor, we demonstrate its use to train a neural network for handwritten digits recognition.