 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Photonic co-processors in HPC: using LightOn OPUs for Randomized Numerical Linear Algebra
May 07, 2021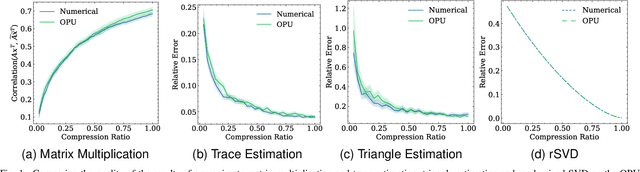
Randomized Numerical Linear Algebra (RandNLA) is a powerful class of methods, widely used in High Performance Computing (HPC). RandNLA provides approximate solutions to linear algebra functions applied to large signals, at reduced computational costs. However, the randomization step for dimensionality reduction may itself become the computational bottleneck on traditional hardware. Leveraging near constant-time linear random projections delivered by LightOn Optical Processing Units we show that randomization can be significantly accelerated, at negligible precision loss, in a wide range of important RandNLA algorithms, such as RandSVD or trace estimators.
Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment
Dec 11, 2020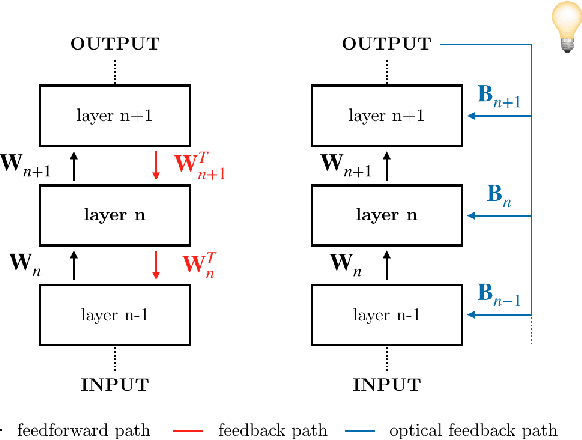


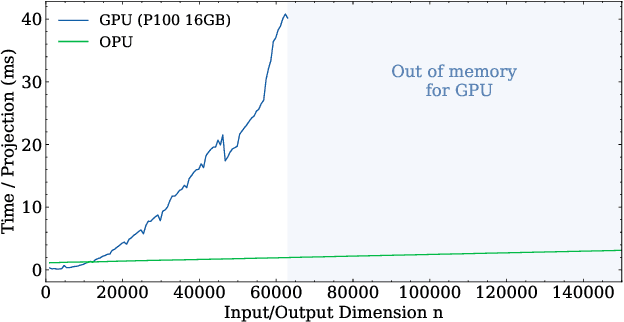
The scaling hypothesis motivates the expansion of models past trillions of parameters as a path towards better performance. Recent significant developments, such as GPT-3, have been driven by this conjecture. However, as models scale-up, training them efficiently with backpropagation becomes difficult. Because model, pipeline, and data parallelism distribute parameters and gradients over compute nodes, communication is challenging to orchestrate: this is a bottleneck to further scaling. In this work, we argue that alternative training methods can mitigate these issues, and can inform the design of extreme-scale training hardware. Indeed, using a synaptically asymmetric method with a parallelizable backward pass, such as Direct Feedback Alignement, communication needs are drastically reduced. We present a photonic accelerator for Direct Feedback Alignment, able to compute random projections with trillions of parameters. We demonstrate our system on benchmark tasks, using both fully-connected and graph convolutional networks. Our hardware is the first architecture-agnostic photonic co-processor for training neural networks. This is a significant step towards building scalable hardware, able to go beyond backpropagation, and opening new avenues for deep learning.
Light-in-the-loop: using a photonics co-processor for scalable training of neural networks
Jun 03, 2020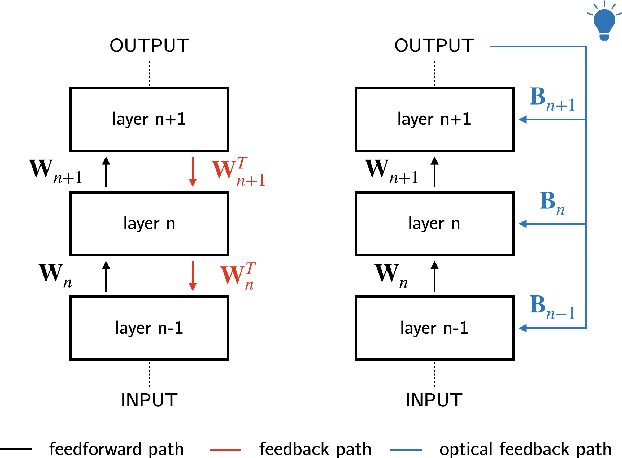
As neural networks grow larger and more complex and data-hungry, training costs are skyrocketing. Especially when lifelong learning is necessary, such as in recommender systems or self-driving cars, this might soon become unsustainable. In this study, we present the first optical co-processor able to accelerate the training phase of digitally-implemented neural networks. We rely on direct feedback alignment as an alternative to backpropagation, and perform the error projection step optically. Leveraging the optical random projections delivered by our co-processor, we demonstrate its use to train a neural network for handwritten digits recognition.
Random Projections through multiple optical scattering: Approximating kernels at the speed of light
Oct 25, 2015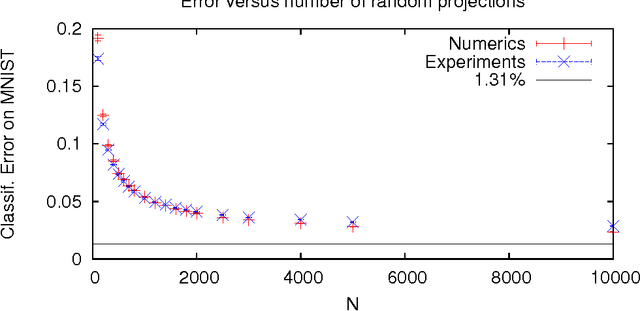

Random projections have proven extremely useful in many signal processing and machine learning applications. However, they often require either to store a very large random matrix, or to use a different, structured matrix to reduce the computational and memory costs. Here, we overcome this difficulty by proposing an analog, optical device, that performs the random projections literally at the speed of light without having to store any matrix in memory. This is achieved using the physical properties of multiple coherent scattering of coherent light in random media. We use this device on a simple task of classification with a kernel machine, and we show that, on the MNIST database, the experimental results closely match the theoretical performance of the corresponding kernel. This framework can help make kernel methods practical for applications that have large training sets and/or require real-time prediction. We discuss possible extensions of the method in terms of a class of kernels, speed, memory consumption and different problems.