 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws from Sequential Feature Recovery: A Solvable Hierarchical Model
May 14, 2026We propose a simple mechanism by which scaling laws emerge from feature learning in multi-layer networks. We study a high-dimensional hierarchical target that is a globally high-degree function, but that can be represented by a combination of latent compositional features whose weights decrease as a power law. We show that a layer-wise spectral algorithm adapted to this compositional structure achieves improved scaling relative to shallow, non-adaptive methods, and recovers the latent directions sequentially: strong features become detectable at small sample sizes, while weaker features require more data. We prove sharp feature-wise recovery thresholds and show that aggregating these transitions yields an explicit power-law decay of the prediction error. Technically, the analysis relies on random matrix methods and a resolvent-based perturbation argument, which gives matching upper and lower bounds for individual eigenvector recovery beyond what standard gap-based perturbation bounds provide. Numerical experiments confirm the predicted sequential recovery, finite-size smoothing of the thresholds, and separation from non-hierarchical kernel baselines. Together, these results show how smooth scaling laws can emerge from a cascade of sharp feature-learning transitions.
Deep Learning as Neural Low-Degree Filtering: A Spectral Theory of Hierarchical Feature Learning
May 13, 2026Understanding how deep neural networks learn useful internal representations from data remains a central open problem in the theory of deep learning. We introduce Neural Low-Degree Filtering (Neural LoFi), a stylized limit of gradient-based training in which hierarchical feature learning becomes an explicit iterative spectral procedure. In this limit, the dynamics at each layer decouple: given the current representation, the next layer selects directions with maximal accessible low-degree correlation to the label. This yields a tractable surrogate mechanism for deep learning, together with a natural kernel-space interpretation. Neural LoFi provides a mathematically explicit framework for studying multi-layer feature learning beyond the lazy regime. It predicts how representations are selected layer by layer, explains how emergence of concepts arises with given sample complexity,and gives a concrete mechanism by which depth progressively constructs new features from old ones through low-degree compositionality. We complement the theory with mechanistic experiments on fully connected and convolutional architectures, showing that Neural LoFi improves over lazy random-feature baselines, recovers meaningful structured filters, and predicts representations aligned with early gradient-descent feature discovery with real datasets.
A Noise Sensitivity Exponent Controls Large Statistical-to-Computational Gaps in Single- and Multi-Index Models
Mar 18, 2026Understanding when learning is statistically possible yet computationally hard is a central challenge in high-dimensional statistics. In this work, we investigate this question in the context of single- and multi-index models, classes of functions widely studied as benchmarks to probe the ability of machine learning methods to discover features in high-dimensional data. Our main contribution is to show that a Noise Sensitivity Exponent (NSE) - a simple quantity determined by the activation function - governs the existence and magnitude of statistical-to-computational gaps within a broad regime of these models. We first establish that, in single-index models with large additive noise, the onset of a computational bottleneck is fully characterized by the NSE. We then demonstrate that the same exponent controls a statistical-computational gap in the specialization transition of large separable multi-index models, where individual components become learnable. Finally, in hierarchical multi-index models, we show that the NSE governs the optimal computational rate in which different directions are sequentially learned. Taken together, our results identify the NSE as a unifying property linking noise robustness, computational hardness, and feature specialization in high-dimensional learning.
ColBERT-Zero: To Pre-train Or Not To Pre-train ColBERT models
Feb 18, 2026Current state-of-the-art multi-vector models are obtained through a small Knowledge Distillation (KD) training step on top of strong single-vector models, leveraging the large-scale pre-training of these models. In this paper, we study the pre-training of multi-vector models and show that large-scale multi-vector pre-training yields much stronger multi-vector models. Notably, a fully ColBERT-pre-trained model, ColBERT-Zero, trained only on public data, outperforms GTE-ModernColBERT as well as its base model, GTE-ModernBERT, which leverages closed and much stronger data, setting new state-of-the-art for model this size. We also find that, although performing only a small KD step is not enough to achieve results close to full pre-training, adding a supervised step beforehand allows to achieve much closer performance while skipping the most costly unsupervised phase. Finally, we find that aligning the fine-tuning and pre-training setups is crucial when repurposing existing models. To enable exploration of our results, we release various checkpoints as well as code used to train them.
Deep Learning of Compositional Targets with Hierarchical Spectral Methods
Feb 11, 2026Why depth yields a genuine computational advantage over shallow methods remains a central open question in learning theory. We study this question in a controlled high-dimensional Gaussian setting, focusing on compositional target functions. We analyze their learnability using an explicit three-layer fitting model trained via layer-wise spectral estimators. Although the target is globally a high-degree polynomial, its compositional structure allows learning to proceed in stages: an intermediate representation reveals structure that is inaccessible at the input level. This reduces learning to simpler spectral estimation problems, well studied in the context of multi-index models, whereas any shallow estimator must resolve all components simultaneously. Our analysis relies on Gaussian universality, leading to sharp separations in sample complexity between two and three-layer learning strategies.
Optimal scaling laws in learning hierarchical multi-index models
Feb 05, 2026In this work, we provide a sharp theory of scaling laws for two-layer neural networks trained on a class of hierarchical multi-index targets, in a genuinely representation-limited regime. We derive exact information-theoretic scaling laws for subspace recovery and prediction error, revealing how the hierarchical features of the target are sequentially learned through a cascade of phase transitions. We further show that these optimal rates are achieved by a simple, target-agnostic spectral estimator, which can be interpreted as the small learning-rate limit of gradient descent on the first-layer weights. Once an adapted representation is identified, the readout can be learned statistically optimally, using an efficient procedure. As a consequence, we provide a unified and rigorous explanation of scaling laws, plateau phenomena, and spectral structure in shallow neural networks trained on such hierarchical targets.
Provable Learning of Random Hierarchy Models and Hierarchical Shallow-to-Deep Chaining
Jan 27, 2026The empirical success of deep learning is often attributed to deep networks' ability to exploit hierarchical structure in data, constructing increasingly complex features across layers. Yet despite substantial progress in deep learning theory, most optimization results sill focus on networks with only two or three layers, leaving the theoretical understanding of hierarchical learning in genuinely deep models limited. This leads to a natural question: can we prove that deep networks, trained by gradient-based methods, can efficiently exploit hierarchical structure? In this work, we consider Random Hierarchy Models -- a hierarchical context-free grammar introduced by arXiv:2307.02129 and conjectured to separate deep and shallow networks. We prove that, under mild conditions, a deep convolutional network can be efficiently trained to learn this function class. Our proof builds on a general observation: if intermediate layers can receive clean signal from the labels and the relevant features are weakly identifiable, then layerwise training each individual layer suffices to hierarchically learn the target function.
The Nuclear Route: Sharp Asymptotics of ERM in Overparameterized Quadratic Networks
May 23, 2025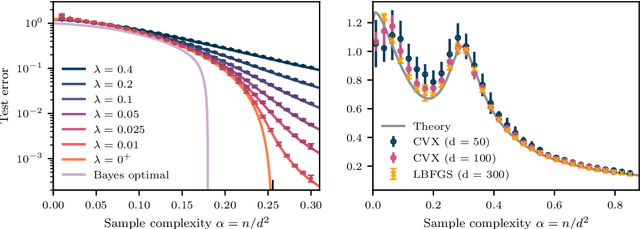


We study the high-dimensional asymptotics of empirical risk minimization (ERM) in over-parametrized two-layer neural networks with quadratic activations trained on synthetic data. We derive sharp asymptotics for both training and test errors by mapping the $\ell_2$-regularized learning problem to a convex matrix sensing task with nuclear norm penalization. This reveals that capacity control in such networks emerges from a low-rank structure in the learned feature maps. Our results characterize the global minima of the loss and yield precise generalization thresholds, showing how the width of the target function governs learnability. This analysis bridges and extends ideas from spin-glass methods, matrix factorization, and convex optimization and emphasizes the deep link between low-rank matrix sensing and learning in quadratic neural networks.
Learning with Restricted Boltzmann Machines: Asymptotics of AMP and GD in High Dimensions
May 23, 2025



The Restricted Boltzmann Machine (RBM) is one of the simplest generative neural networks capable of learning input distributions. Despite its simplicity, the analysis of its performance in learning from the training data is only well understood in cases that essentially reduce to singular value decomposition of the data. Here, we consider the limit of a large dimension of the input space and a constant number of hidden units. In this limit, we simplify the standard RBM training objective into a form that is equivalent to the multi-index model with non-separable regularization. This opens a path to analyze training of the RBM using methods that are established for multi-index models, such as Approximate Message Passing (AMP) and its state evolution, and the analysis of Gradient Descent (GD) via the dynamical mean-field theory. We then give rigorous asymptotics of the training dynamics of RBM on data generated by the spiked covariance model as a prototype of a structure suitable for unsupervised learning. We show in particular that RBM reaches the optimal computational weak recovery threshold, aligning with the BBP transition, in the spiked covariance model.
Fundamental Limits of Matrix Sensing: Exact Asymptotics, Universality, and Applications
Mar 18, 2025In the matrix sensing problem, one wishes to reconstruct a matrix from (possibly noisy) observations of its linear projections along given directions. We consider this model in the high-dimensional limit: while previous works on this model primarily focused on the recovery of low-rank matrices, we consider in this work more general classes of structured signal matrices with potentially large rank, e.g. a product of two matrices of sizes proportional to the dimension. We provide rigorous asymptotic equations characterizing the Bayes-optimal learning performance from a number of samples which is proportional to the number of entries in the matrix. Our proof is composed of three key ingredients: $(i)$ we prove universality properties to handle structured sensing matrices, related to the ''Gaussian equivalence'' phenomenon in statistical learning, $(ii)$ we provide a sharp characterization of Bayes-optimal learning in generalized linear models with Gaussian data and structured matrix priors, generalizing previously studied settings, and $(iii)$ we leverage previous works on the problem of matrix denoising. The generality of our results allow for a variety of applications: notably, we mathematically establish predictions obtained via non-rigorous methods from statistical physics in [ETB+24] regarding Bilinear Sequence Regression, a benchmark model for learning from sequences of tokens, and in [MTM+24] on Bayes-optimal learning in neural networks with quadratic activation function, and width proportional to the dimension.