 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Online Learning and Information Exponents: On The Importance of Batch size, and Time/Complexity Tradeoffs
Jun 04, 2024We study the impact of the batch size $n_b$ on the iteration time $T$ of training two-layer neural networks with one-pass stochastic gradient descent (SGD) on multi-index target functions of isotropic covariates. We characterize the optimal batch size minimizing the iteration time as a function of the hardness of the target, as characterized by the information exponents. We show that performing gradient updates with large batches $n_b \lesssim d^{\frac{\ell}{2}}$ minimizes the training time without changing the total sample complexity, where $\ell$ is the information exponent of the target to be learned \citep{arous2021online} and $d$ is the input dimension. However, larger batch sizes than $n_b \gg d^{\frac{\ell}{2}}$ are detrimental for improving the time complexity of SGD. We provably overcome this fundamental limitation via a different training protocol, \textit{Correlation loss SGD}, which suppresses the auto-correlation terms in the loss function. We show that one can track the training progress by a system of low-dimensional ordinary differential equations (ODEs). Finally, we validate our theoretical results with numerical experiments.
Repetita Iuvant: Data Repetition Allows SGD to Learn High-Dimensional Multi-Index Functions
May 24, 2024Neural networks can identify low-dimensional relevant structures within high-dimensional noisy data, yet our mathematical understanding of how they do so remains scarce. Here, we investigate the training dynamics of two-layer shallow neural networks trained with gradient-based algorithms, and discuss how they learn pertinent features in multi-index models, that is target functions with low-dimensional relevant directions. In the high-dimensional regime, where the input dimension $d$ diverges, we show that a simple modification of the idealized single-pass gradient descent training scenario, where data can now be repeated or iterated upon twice, drastically improves its computational efficiency. In particular, it surpasses the limitations previously believed to be dictated by the Information and Leap exponents associated with the target function to be learned. Our results highlight the ability of networks to learn relevant structures from data alone without any pre-processing. More precisely, we show that (almost) all directions are learned with at most $O(d \log d)$ steps. Among the exceptions is a set of hard functions that includes sparse parities. In the presence of coupling between directions, however, these can be learned sequentially through a hierarchical mechanism that generalizes the notion of staircase functions. Our results are proven by a rigorous study of the evolution of the relevant statistics for high-dimensional dynamics.
NLP Verification: Towards a General Methodology for Certifying Robustness
Mar 15, 2024Deep neural networks have exhibited substantial success in the field of Natural Language Processing (NLP) and ensuring their safety and reliability is crucial: there are safety critical contexts where such models must be robust to variability or attack, and give guarantees over their output. Unlike Computer Vision, NLP lacks a unified verification methodology and, despite recent advancements in literature, they are often light on the pragmatical issues of NLP verification. In this paper, we make an attempt to distil and evaluate general components of an NLP verification pipeline, that emerges from the progress in the field to date. Our contributions are two-fold. Firstly, we give a general characterisation of verifiable subspaces that result from embedding sentences into continuous spaces. We identify, and give an effective method to deal with, the technical challenge of semantic generalisability of verified subspaces; and propose it as a standard metric in the NLP verification pipelines (alongside with the standard metrics of model accuracy and model verifiability). Secondly, we propose a general methodology to analyse the effect of the embedding gap, a problem that refers to the discrepancy between verification of geometric subpspaces on the one hand, and semantic meaning of sentences which the geometric subspaces are supposed to represent, on the other hand. In extreme cases, poor choices in embedding of sentences may invalidate verification results. We propose a number of practical NLP methods that can help to identify the effects of the embedding gap; and in particular we propose the metric of falsifiability of semantic subpspaces as another fundamental metric to be reported as part of the NLP verification pipeline. We believe that together these general principles pave the way towards a more consolidated and effective development of this new domain.
The Benefits of Reusing Batches for Gradient Descent in Two-Layer Networks: Breaking the Curse of Information and Leap Exponents
Feb 05, 2024

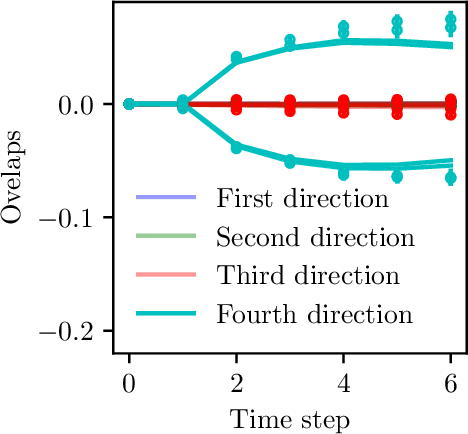
We investigate the training dynamics of two-layer neural networks when learning multi-index target functions. We focus on multi-pass gradient descent (GD) that reuses the batches multiple times and show that it significantly changes the conclusion about which functions are learnable compared to single-pass gradient descent. In particular, multi-pass GD with finite stepsize is found to overcome the limitations of gradient flow and single-pass GD given by the information exponent (Ben Arous et al., 2021) and leap exponent (Abbe et al., 2023) of the target function. We show that upon re-using batches, the network achieves in just two time steps an overlap with the target subspace even for functions not satisfying the staircase property (Abbe et al., 2021). We characterize the (broad) class of functions efficiently learned in finite time. The proof of our results is based on the analysis of the Dynamical Mean-Field Theory (DMFT). We further provide a closed-form description of the dynamical process of the low-dimensional projections of the weights, and numerical experiments illustrating the theory.
Vehicle: Bridging the Embedding Gap in the Verification of Neuro-Symbolic Programs
Jan 12, 2024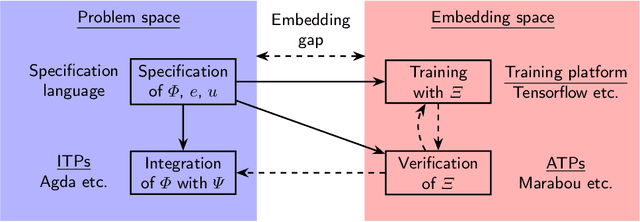
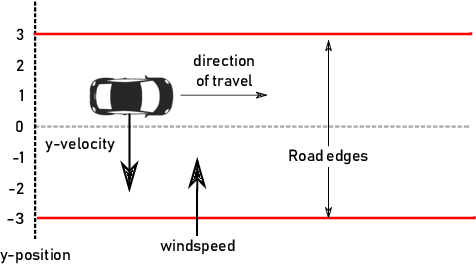


Neuro-symbolic programs -- programs containing both machine learning components and traditional symbolic code -- are becoming increasingly widespread. However, we believe that there is still a lack of a general methodology for verifying these programs whose correctness depends on the behaviour of the machine learning components. In this paper, we identify the ``embedding gap'' -- the lack of techniques for linking semantically-meaningful ``problem-space'' properties to equivalent ``embedding-space'' properties -- as one of the key issues, and describe Vehicle, a tool designed to facilitate the end-to-end verification of neural-symbolic programs in a modular fashion. Vehicle provides a convenient language for specifying ``problem-space'' properties of neural networks and declaring their relationship to the ``embedding-space", and a powerful compiler that automates interpretation of these properties in the language of a chosen machine-learning training environment, neural network verifier, and interactive theorem prover. We demonstrate Vehicle's utility by using it to formally verify the safety of a simple autonomous car equipped with a neural network controller.
Escaping mediocrity: how two-layer networks learn hard single-index models with SGD
May 29, 2023This study explores the sample complexity for two-layer neural networks to learn a single-index target function under Stochastic Gradient Descent (SGD), focusing on the challenging regime where many flat directions are present at initialization. It is well-established that in this scenario $n=O(d\log{d})$ samples are typically needed. However, we provide precise results concerning the pre-factors in high-dimensional contexts and for varying widths. Notably, our findings suggest that overparameterization can only enhance convergence by a constant factor within this problem class. These insights are grounded in the reduction of SGD dynamics to a stochastic process in lower dimensions, where escaping mediocrity equates to calculating an exit time. Yet, we demonstrate that a deterministic approximation of this process adequately represents the escape time, implying that the role of stochasticity may be minimal in this scenario.
ANTONIO: Towards a Systematic Method of Generating NLP Benchmarks for Verification
May 06, 2023



Verification of machine learning models used in Natural Language Processing (NLP) is known to be a hard problem. In particular, many known neural network verification methods that work for computer vision and other numeric datasets do not work for NLP. Here, we study technical reasons that underlie this problem. Based on this analysis, we propose practical methods and heuristics for preparing NLP datasets and models in a way that renders them amenable to known verification methods based on abstract interpretation. We implement these methods as a Python library called ANTONIO that links to the neural network verifiers ERAN and Marabou. We perform evaluation of the tool using an NLP dataset R-U-A-Robot suggested as a benchmark for verifying legally critical NLP applications. We hope that, thanks to its general applicability, this work will open novel possibilities for including NLP verification problems into neural network verification competitions, and will popularise NLP problems within this community.
From high-dimensional & mean-field dynamics to dimensionless ODEs: A unifying approach to SGD in two-layers networks
Feb 12, 2023This manuscript investigates the one-pass stochastic gradient descent (SGD) dynamics of a two-layer neural network trained on Gaussian data and labels generated by a similar, though not necessarily identical, target function. We rigorously analyse the limiting dynamics via a deterministic and low-dimensional description in terms of the sufficient statistics for the population risk. Our unifying analysis bridges different regimes of interest, such as the classical gradient-flow regime of vanishing learning rate, the high-dimensional regime of large input dimension, and the overparameterised "mean-field" regime of large network width, covering as well the intermediate regimes where the limiting dynamics is determined by the interplay between these behaviours. In particular, in the high-dimensional limit, the infinite-width dynamics is found to remain close to a low-dimensional subspace spanned by the target principal directions. Our results therefore provide a unifying picture of the limiting SGD dynamics with synthetic data.
Why Robust Natural Language Understanding is a Challenge
Jun 21, 2022
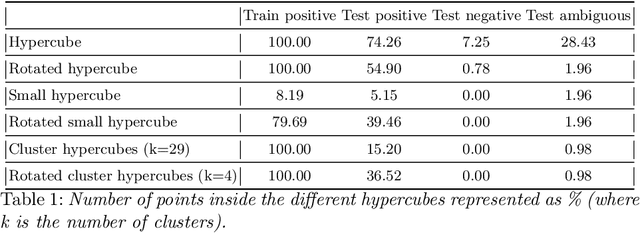

With the proliferation of Deep Machine Learning into real-life applications, a particular property of this technology has been brought to attention: Neural Networks notoriously present low robustness and can be highly sensitive to small input perturbations. Recently, many methods for verifying networks' general properties of robustness have been proposed, but they are mostly applied in Computer Vision. In this paper we propose a Verification method for Natural Language Understanding classification based on larger regions of interest, and we discuss the challenges of such task. We observe that, although the data is almost linearly separable, the verifier does not output positive results and we explain the problems and implications.