 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning of Compositional Targets with Hierarchical Spectral Methods
Feb 11, 2026Why depth yields a genuine computational advantage over shallow methods remains a central open question in learning theory. We study this question in a controlled high-dimensional Gaussian setting, focusing on compositional target functions. We analyze their learnability using an explicit three-layer fitting model trained via layer-wise spectral estimators. Although the target is globally a high-degree polynomial, its compositional structure allows learning to proceed in stages: an intermediate representation reveals structure that is inaccessible at the input level. This reduces learning to simpler spectral estimation problems, well studied in the context of multi-index models, whereas any shallow estimator must resolve all components simultaneously. Our analysis relies on Gaussian universality, leading to sharp separations in sample complexity between two and three-layer learning strategies.
The Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient Descent
Feb 19, 2025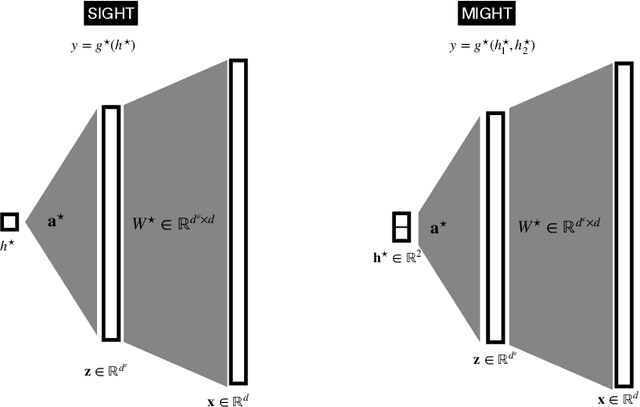
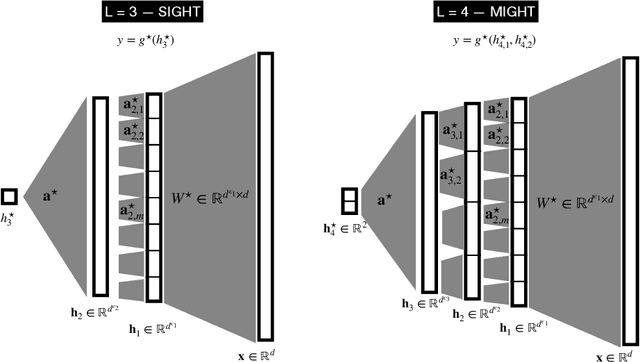
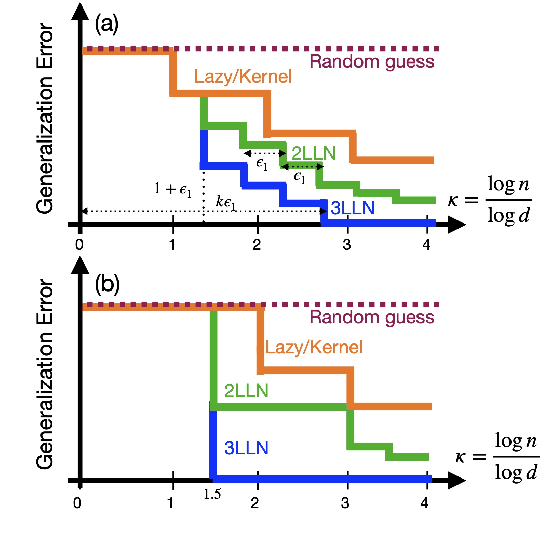
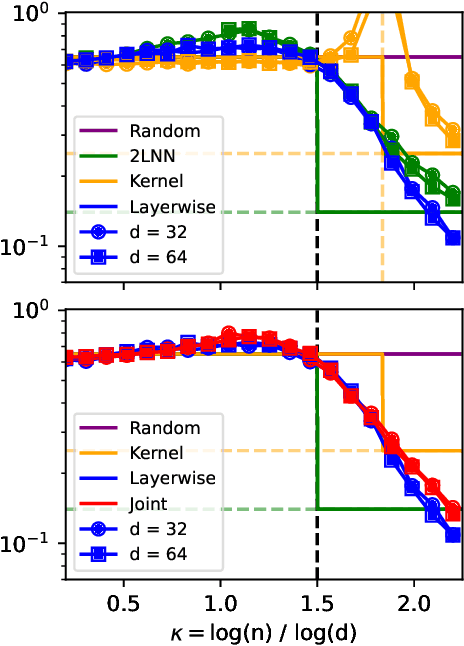
Understanding the advantages of deep neural networks trained by gradient descent (GD) compared to shallow models remains an open theoretical challenge. While the study of multi-index models with Gaussian data in high dimensions has provided analytical insights into the benefits of GD-trained neural networks over kernels, the role of depth in improving sample complexity and generalization in GD-trained networks remains poorly understood. In this paper, we introduce a class of target functions (single and multi-index Gaussian hierarchical targets) that incorporate a hierarchy of latent subspace dimensionalities. This framework enables us to analytically study the learning dynamics and generalization performance of deep networks compared to shallow ones in the high-dimensional limit. Specifically, our main theorem shows that feature learning with GD reduces the effective dimensionality, transforming a high-dimensional problem into a sequence of lower-dimensional ones. This enables learning the target function with drastically less samples than with shallow networks. While the results are proven in a controlled training setting, we also discuss more common training procedures and argue that they learn through the same mechanisms. These findings open the way to further quantitative studies of the crucial role of depth in learning hierarchical structures with deep networks.
A Random Matrix Theory Perspective on the Spectrum of Learned Features and Asymptotic Generalization Capabilities
Oct 24, 2024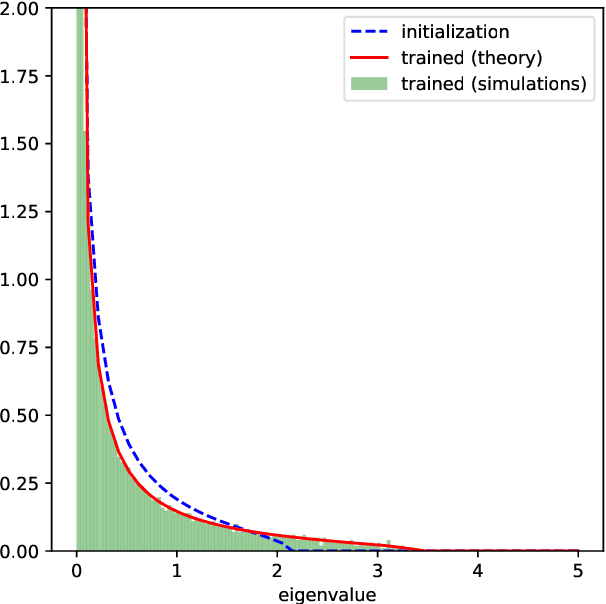
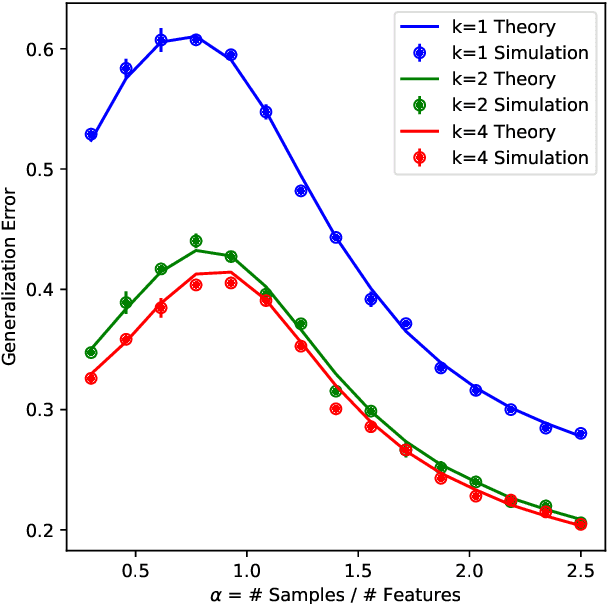
A key property of neural networks is their capacity of adapting to data during training. Yet, our current mathematical understanding of feature learning and its relationship to generalization remain limited. In this work, we provide a random matrix analysis of how fully-connected two-layer neural networks adapt to the target function after a single, but aggressive, gradient descent step. We rigorously establish the equivalence between the updated features and an isotropic spiked random feature model, in the limit of large batch size. For the latter model, we derive a deterministic equivalent description of the feature empirical covariance matrix in terms of certain low-dimensional operators. This allows us to sharply characterize the impact of training in the asymptotic feature spectrum, and in particular, provides a theoretical grounding for how the tails of the feature spectrum modify with training. The deterministic equivalent further yields the exact asymptotic generalization error, shedding light on the mechanisms behind its improvement in the presence of feature learning. Our result goes beyond standard random matrix ensembles, and therefore we believe it is of independent technical interest. Different from previous work, our result holds in the challenging maximal learning rate regime, is fully rigorous and allows for finitely supported second layer initialization, which turns out to be crucial for studying the functional expressivity of the learned features. This provides a sharp description of the impact of feature learning in the generalization of two-layer neural networks, beyond the random features and lazy training regimes.
Online Learning and Information Exponents: On The Importance of Batch size, and Time/Complexity Tradeoffs
Jun 04, 2024We study the impact of the batch size $n_b$ on the iteration time $T$ of training two-layer neural networks with one-pass stochastic gradient descent (SGD) on multi-index target functions of isotropic covariates. We characterize the optimal batch size minimizing the iteration time as a function of the hardness of the target, as characterized by the information exponents. We show that performing gradient updates with large batches $n_b \lesssim d^{\frac{\ell}{2}}$ minimizes the training time without changing the total sample complexity, where $\ell$ is the information exponent of the target to be learned \citep{arous2021online} and $d$ is the input dimension. However, larger batch sizes than $n_b \gg d^{\frac{\ell}{2}}$ are detrimental for improving the time complexity of SGD. We provably overcome this fundamental limitation via a different training protocol, \textit{Correlation loss SGD}, which suppresses the auto-correlation terms in the loss function. We show that one can track the training progress by a system of low-dimensional ordinary differential equations (ODEs). Finally, we validate our theoretical results with numerical experiments.
Repetita Iuvant: Data Repetition Allows SGD to Learn High-Dimensional Multi-Index Functions
May 24, 2024Neural networks can identify low-dimensional relevant structures within high-dimensional noisy data, yet our mathematical understanding of how they do so remains scarce. Here, we investigate the training dynamics of two-layer shallow neural networks trained with gradient-based algorithms, and discuss how they learn pertinent features in multi-index models, that is target functions with low-dimensional relevant directions. In the high-dimensional regime, where the input dimension $d$ diverges, we show that a simple modification of the idealized single-pass gradient descent training scenario, where data can now be repeated or iterated upon twice, drastically improves its computational efficiency. In particular, it surpasses the limitations previously believed to be dictated by the Information and Leap exponents associated with the target function to be learned. Our results highlight the ability of networks to learn relevant structures from data alone without any pre-processing. More precisely, we show that (almost) all directions are learned with at most $O(d \log d)$ steps. Among the exceptions is a set of hard functions that includes sparse parities. In the presence of coupling between directions, however, these can be learned sequentially through a hierarchical mechanism that generalizes the notion of staircase functions. Our results are proven by a rigorous study of the evolution of the relevant statistics for high-dimensional dynamics.
Asymptotics of feature learning in two-layer networks after one gradient-step
Feb 07, 2024In this manuscript we investigate the problem of how two-layer neural networks learn features from data, and improve over the kernel regime, after being trained with a single gradient descent step. Leveraging a connection from (Ba et al., 2022) with a non-linear spiked matrix model and recent progress on Gaussian universality (Dandi et al., 2023), we provide an exact asymptotic description of the generalization error in the high-dimensional limit where the number of samples $n$, the width $p$ and the input dimension $d$ grow at a proportional rate. We characterize exactly how adapting to the data is crucial for the network to efficiently learn non-linear functions in the direction of the gradient -- where at initialization it can only express linear functions in this regime. To our knowledge, our results provides the first tight description of the impact of feature learning in the generalization of two-layer neural networks in the large learning rate regime $\eta=\Theta_{d}(d)$, beyond perturbative finite width corrections of the conjugate and neural tangent kernels.
The Benefits of Reusing Batches for Gradient Descent in Two-Layer Networks: Breaking the Curse of Information and Leap Exponents
Feb 05, 2024

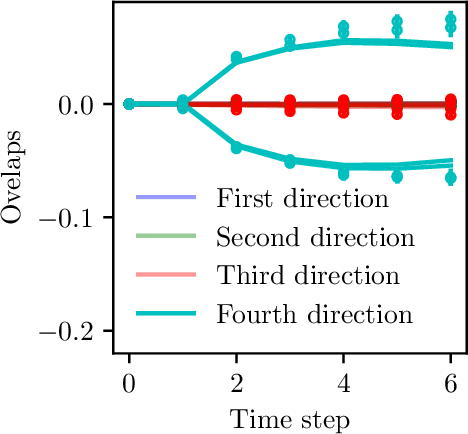
We investigate the training dynamics of two-layer neural networks when learning multi-index target functions. We focus on multi-pass gradient descent (GD) that reuses the batches multiple times and show that it significantly changes the conclusion about which functions are learnable compared to single-pass gradient descent. In particular, multi-pass GD with finite stepsize is found to overcome the limitations of gradient flow and single-pass GD given by the information exponent (Ben Arous et al., 2021) and leap exponent (Abbe et al., 2023) of the target function. We show that upon re-using batches, the network achieves in just two time steps an overlap with the target subspace even for functions not satisfying the staircase property (Abbe et al., 2021). We characterize the (broad) class of functions efficiently learned in finite time. The proof of our results is based on the analysis of the Dynamical Mean-Field Theory (DMFT). We further provide a closed-form description of the dynamical process of the low-dimensional projections of the weights, and numerical experiments illustrating the theory.
Learning Two-Layer Neural Networks, One Step at a Time
May 29, 2023We study the training dynamics of shallow neural networks, investigating the conditions under which a limited number of large batch gradient descent steps can facilitate feature learning beyond the kernel regime. We compare the influence of batch size and that of multiple (but finitely many) steps. Our analysis of a single-step process reveals that while a batch size of $n = O(d)$ enables feature learning, it is only adequate for learning a single direction, or a single-index model. In contrast, $n = O(d^2)$ is essential for learning multiple directions and specialization. Moreover, we demonstrate that ``hard'' directions, which lack the first $\ell$ Hermite coefficients, remain unobserved and require a batch size of $n = O(d^\ell)$ for being captured by gradient descent. Upon iterating a few steps, the scenario changes: a batch-size of $n = O(d)$ is enough to learn new target directions spanning the subspace linearly connected in the Hermite basis to the previously learned directions, thereby a staircase property. Our analysis utilizes a blend of techniques related to concentration, projection-based conditioning, and Gaussian equivalence that are of independent interest. By determining the conditions necessary for learning and specialization, our results highlight the interaction between batch size and number of iterations, and lead to a hierarchical depiction where learning performance exhibits a stairway to accuracy over time and batch size, shedding new light on feature learning in neural networks.
Are Gaussian data all you need? Extents and limits of universality in high-dimensional generalized linear estimation
Feb 17, 2023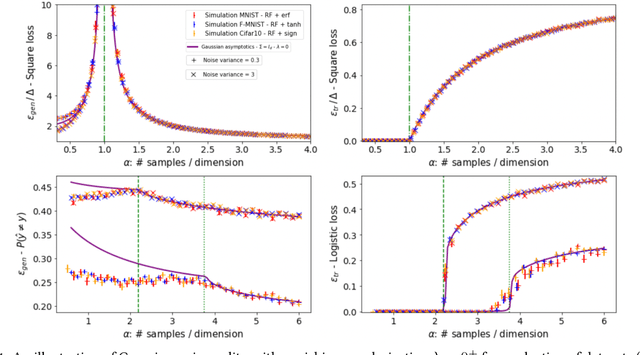
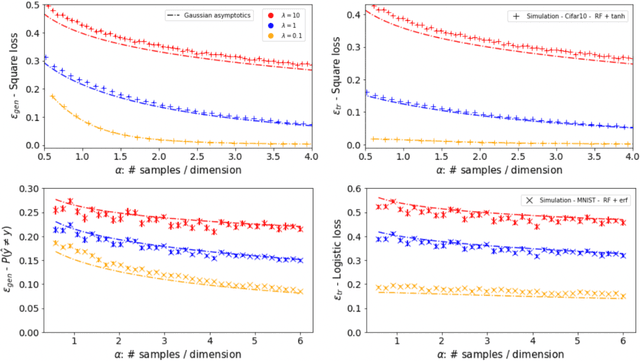
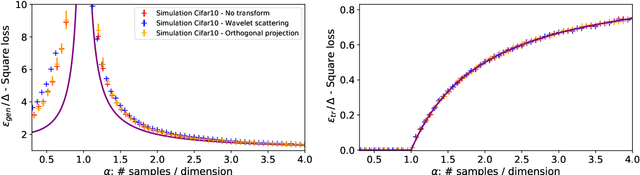
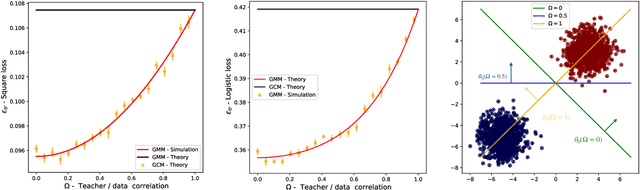
In this manuscript we consider the problem of generalized linear estimation on Gaussian mixture data with labels given by a single-index model. Our first result is a sharp asymptotic expression for the test and training errors in the high-dimensional regime. Motivated by the recent stream of results on the Gaussian universality of the test and training errors in generalized linear estimation, we ask ourselves the question: "when is a single Gaussian enough to characterize the error?". Our formula allow us to give sharp answers to this question, both in the positive and negative directions. More precisely, we show that the sufficient conditions for Gaussian universality (or lack of thereof) crucially depend on the alignment between the target weights and the means and covariances of the mixture clusters, which we precisely quantify. In the particular case of least-squares interpolation, we prove a strong universality property of the training error, and show it follows a simple, closed-form expression. Finally, we apply our results to real datasets, clarifying some recent discussion in the literature about Gaussian universality of the errors in this context.
Subspace clustering in high-dimensions: Phase transitions \& Statistical-to-Computational gap
May 26, 2022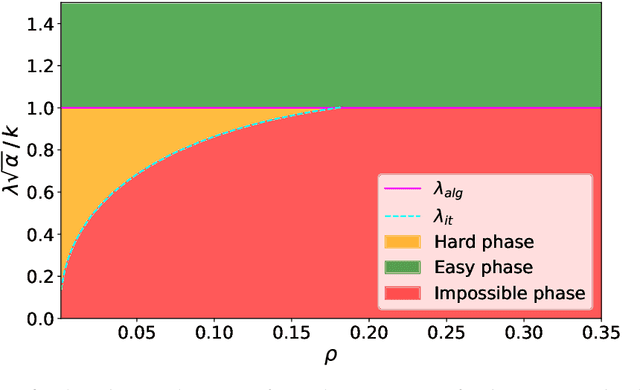
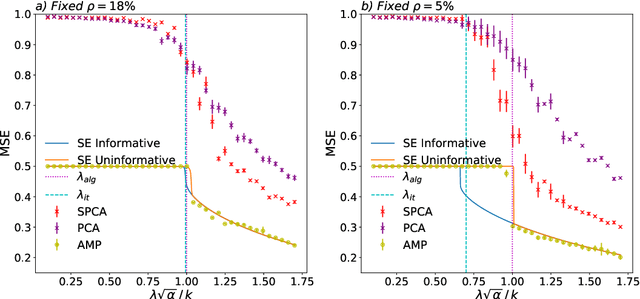
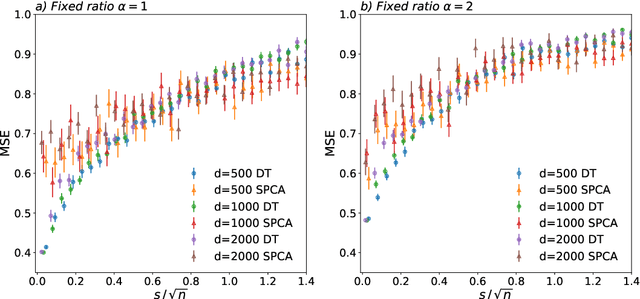
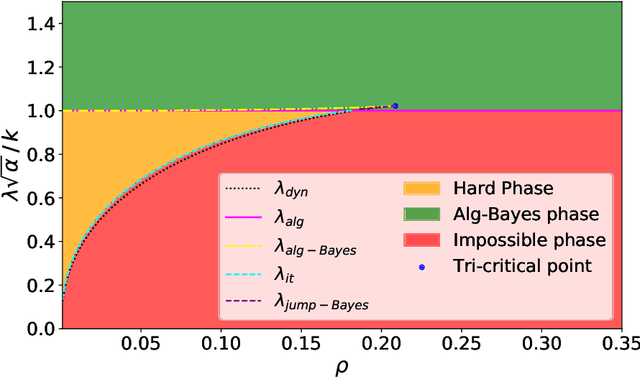
A simple model to study subspace clustering is the high-dimensional $k$-Gaussian mixture model where the cluster means are sparse vectors. Here we provide an exact asymptotic characterization of the statistically optimal reconstruction error in this model in the high-dimensional regime with extensive sparsity, i.e. when the fraction of non-zero components of the cluster means $\rho$, as well as the ratio $\alpha$ between the number of samples and the dimension are fixed, while the dimension diverges. We identify the information-theoretic threshold below which obtaining a positive correlation with the true cluster means is statistically impossible. Additionally, we investigate the performance of the approximate message passing (AMP) algorithm analyzed via its state evolution, which is conjectured to be optimal among polynomial algorithm for this task. We identify in particular the existence of a statistical-to-computational gap between the algorithm that require a signal-to-noise ratio $\lambda_{\text{alg}} \ge k / \sqrt{\alpha} $ to perform better than random, and the information theoretic threshold at $\lambda_{\text{it}} \approx \sqrt{-k \rho \log{\rho}} / \sqrt{\alpha}$. Finally, we discuss the case of sub-extensive sparsity $\rho$ by comparing the performance of the AMP with other sparsity-enhancing algorithms, such as sparse-PCA and diagonal thresholding.