 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random Matrix Theory Perspective on the Spectrum of Learned Features and Asymptotic Generalization Capabilities
Paper and Code
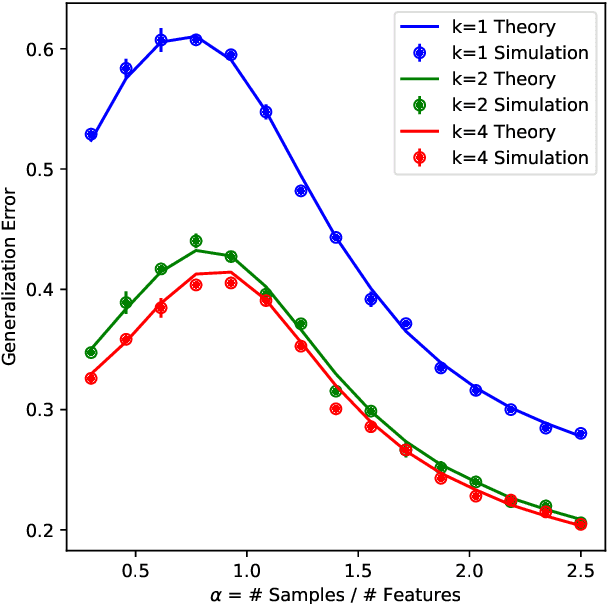
Oct 24, 2024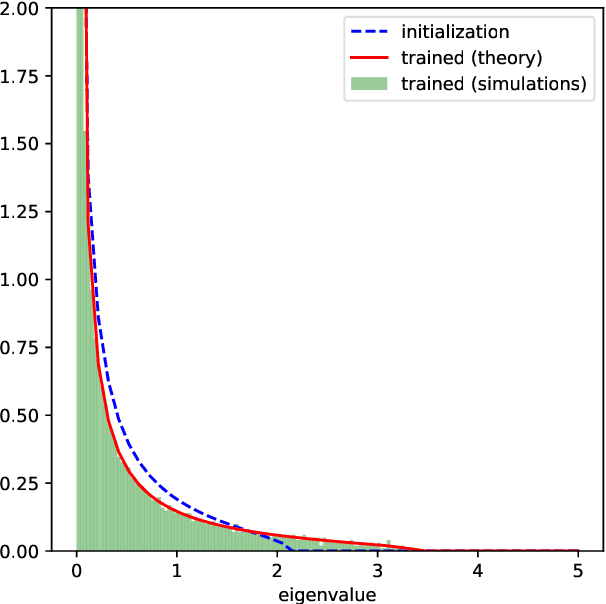
A key property of neural networks is their capacity of adapting to data during training. Yet, our current mathematical understanding of feature learning and its relationship to generalization remain limited. In this work, we provide a random matrix analysis of how fully-connected two-layer neural networks adapt to the target function after a single, but aggressive, gradient descent step. We rigorously establish the equivalence between the updated features and an isotropic spiked random feature model, in the limit of large batch size. For the latter model, we derive a deterministic equivalent description of the feature empirical covariance matrix in terms of certain low-dimensional operators. This allows us to sharply characterize the impact of training in the asymptotic feature spectrum, and in particular, provides a theoretical grounding for how the tails of the feature spectrum modify with training. The deterministic equivalent further yields the exact asymptotic generalization error, shedding light on the mechanisms behind its improvement in the presence of feature learning. Our result goes beyond standard random matrix ensembles, and therefore we believe it is of independent technical interest. Different from previous work, our result holds in the challenging maximal learning rate regime, is fully rigorous and allows for finitely supported second layer initialization, which turns out to be crucial for studying the functional expressivity of the learned features. This provides a sharp description of the impact of feature learning in the generalization of two-layer neural networks, beyond the random features and lazy training regimes.