 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient Descent
Paper and Code
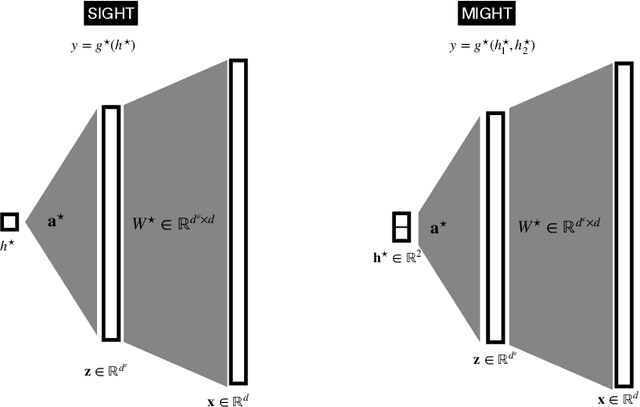
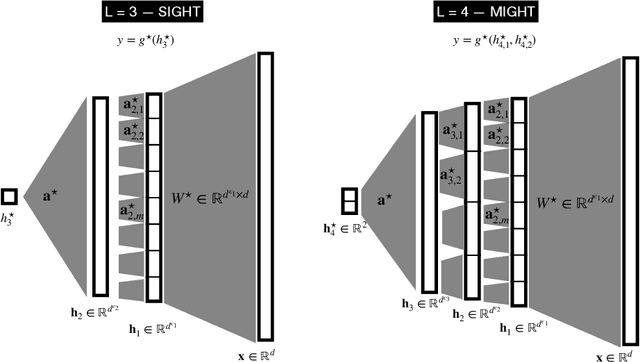
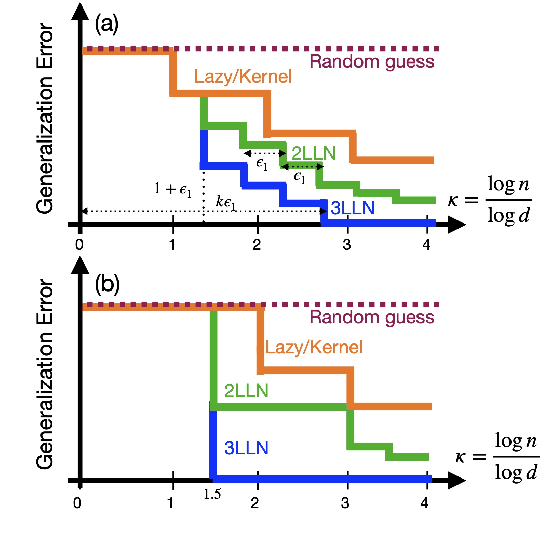
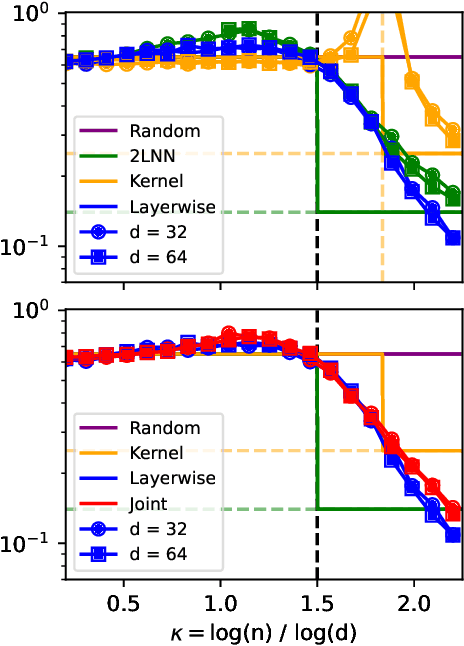
Understanding the advantages of deep neural networks trained by gradient descent (GD) compared to shallow models remains an open theoretical challenge. While the study of multi-index models with Gaussian data in high dimensions has provided analytical insights into the benefits of GD-trained neural networks over kernels, the role of depth in improving sample complexity and generalization in GD-trained networks remains poorly understood. In this paper, we introduce a class of target functions (single and multi-index Gaussian hierarchical targets) that incorporate a hierarchy of latent subspace dimensionalities. This framework enables us to analytically study the learning dynamics and generalization performance of deep networks compared to shallow ones in the high-dimensional limit. Specifically, our main theorem shows that feature learning with GD reduces the effective dimensionality, transforming a high-dimensional problem into a sequence of lower-dimensional ones. This enables learning the target function with drastically less samples than with shallow networks. While the results are proven in a controlled training setting, we also discuss more common training procedures and argue that they learn through the same mechanisms. These findings open the way to further quantitative studies of the crucial role of depth in learning hierarchical structures with deep networks.