 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveriFIRE: an Industrial Case Study in Verifying Consistency Properties for a DNN-Based Wildfire Detection System
Jun 02, 2026We present our ongoing work on the veriFIRE project: a collaboration between industry and academia, aimed at applying verification to increase the reliability of a real-world, safety-critical system. Specifically, we target an airborne platform for wildfire detection, which incorporates two deep neural networks. We present an end-to-end methodology for verifying \textit{consistency properties} in this system. Our approach encodes application-grounded requirements into solver-compatible queries for existing neural network verifiers. We study properties of interest over critical operational scenarios: (i) monotonicity of detector confidence as target intensity increases; and (ii) bounded detector response under physically plausible blur over the sensor. We instantiate these encodings using state-of-the-art neural network verification backends and evaluate them at scale on real background samples. For the first property, all verification queries are solved in under five minutes. For the second property, verification is substantially harder, highlighting key scalability challenges for richer, higher-dimensional specifications. Overall, the results demonstrate that meaningful, domain-specific guarantees can be obtained for industrial systems.
Neural Network Verification using Partial Multi-Neuron Relaxation
May 28, 2026The increasing integration of deep neural networks in critical systems has spawned a theoretical and practical interest in formally guaranteeing safety properties about their behavior. To achieve this, contemporary verification algorithms rely on computing linear relaxations for a network's non-linear activation functions. Existing approaches for linear relaxations typically fall into one of two categories: single-neuron relaxation, in which each activation neuron is bounded in terms of its sources; and multi-neuron relaxation, in which linear bounds involving multiple activation neurons and their sources are calculated. However, existing methods might fail to balance tightness and scalability, as single-neuron bounds might not derive sufficiently tight bounds necessary for verification to complete, whereas generating multi-neuron relaxation for all activation neurons is computationally expensive. In this paper, we present a middle-ground approach featuring partial multi-neuron relaxation, in which we generate multi-neuron bounds for only a small, heuristically selected subset of neurons. To achieve this, we build upon existing branching heuristics for selecting neurons and for optimizing bounding hyper-planes for multi-neuron bounds. We integrated our proposed method within the Marabou verifier, and obtained favorable results in comparison to existing bound tightening methods. Our experiments showcase the potential of our technique for neural network verification.
Verified SHAP: Provable Bounds for Exact Shapley Values of Neural Networks
May 22, 2026Shapley additive explanations (SHAP) are widely recognised as computationally intractable for neural networks, since they induce an exponential search space over the input features. In this work, we take a first step towards scaling exact SHAP computation to larger search spaces by introducing an algorithm that leverages recent advances in neural network verification to compute arbitrarily tight exact lower and upper bounds on SHAP values for neural networks, ultimately recovering the exact SHAP values. We demonstrate that our approach scales to orders of magnitude larger search spaces than state-of-the-art exact methods. This provides an important first step towards exact SHAP computation and establishes a principled cornerstone for evaluating statistical approximation methods on larger search spaces.
Not All Invariants Are Equal: Curating Training Data to Accelerate Program Verification with SLMs
Mar 16, 2026The synthesis of inductive loop invariants is a critical bottleneck in automated program verification. While Large Language Models (LLMs) show promise in mitigating this issue, they often fail on hard instances, generating invariants that are invalid or computationally ineffective. While fine-tuning is a natural route to mitigate this limitation, obtaining high-quality training data for invariant generation remains an open challenge. We present a rigorous data curation pipeline designed to extract high-quality training signals from raw verifier-generated invariants. First, we formalize the properties required for a high-quality training invariant. Second, we propose Wonda, a pipeline that refines noisy data via AST-based normalization, followed by LLM-driven semantic rewriting and augmentation with provable quality guarantees. We demonstrate that fine-tuning Small Language Models (SLMs) on this curated dataset result in consistent and significant performance gain. In particular, a fine-tuned 4B parameter model matches the utility of a GPT-OSS-120B baseline and approaches the state-of-the-art GPT-5.2, without incurring reasoning-time overhead. On challenging instances from the recent InvBench evaluation suite, our approach doubles the invariant correctness and speedup rates of base models; and improves their Virtual Best Performance (VBP) rates on the verification task by up to 14.2%.
Incremental Neural Network Verification via Learned Conflicts
Mar 12, 2026Neural network verification is often used as a core component within larger analysis procedures, which generate sequences of closely related verification queries over the same network. In existing neural network verifiers, each query is typically solved independently, and information learned during previous runs is discarded, leading to repeated exploration of the same infeasible regions of the search space. In this work, we aim to expedite verification by reducing this redundancy. We propose an incremental verification technique that reuses learned conflicts across related verification queries. The technique can be added on top of any branch-and-bound-based neural network verifier. During verification, the verifier records conflicts corresponding to learned infeasible combinations of activation phases, and retains them across runs. We formalize a refinement relation between verification queries and show that conflicts learned for a query remain valid under refinement, enabling sound conflict inheritance. Inherited conflicts are handled using a SAT solver to perform consistency checks and propagation, allowing infeasible subproblems to be detected and pruned early during search. We implement the proposed technique in the Marabou verifier and evaluate it on three verification tasks: local robustness radius determination, verification with input splitting, and minimal sufficient feature set extraction. Our experiments show that incremental conflict reuse reduces verification effort and yields speedups of up to $1.9\times$ over a non-incremental baseline.
FAME: Formal Abstract Minimal Explanation for Neural Networks
Mar 11, 2026We propose FAME (Formal Abstract Minimal Explanations), a new class of abductive explanations grounded in abstract interpretation. FAME is the first method to scale to large neural networks while reducing explanation size. Our main contribution is the design of dedicated perturbation domains that eliminate the need for traversal order. FAME progressively shrinks these domains and leverages LiRPA-based bounds to discard irrelevant features, ultimately converging to a formal abstract minimal explanation. To assess explanation quality, we introduce a procedure that measures the worst-case distance between an abstract minimal explanation and a true minimal explanation. This procedure combines adversarial attacks with an optional VERIX+ refinement step. We benchmark FAME against VERIX+ and demonstrate consistent gains in both explanation size and runtime on medium- to large-scale neural networks.
Provably Explaining Neural Additive Models
Feb 19, 2026Despite significant progress in post-hoc explanation methods for neural networks, many remain heuristic and lack provable guarantees. A key approach for obtaining explanations with provable guarantees is by identifying a cardinally-minimal subset of input features which by itself is provably sufficient to determine the prediction. However, for standard neural networks, this task is often computationally infeasible, as it demands a worst-case exponential number of verification queries in the number of input features, each of which is NP-hard. In this work, we show that for Neural Additive Models (NAMs), a recent and more interpretable neural network family, we can efficiently generate explanations with such guarantees. We present a new model-specific algorithm for NAMs that generates provably cardinally-minimal explanations using only a logarithmic number of verification queries in the number of input features, after a parallelized preprocessing step with logarithmic runtime in the required precision is applied to each small univariate NAM component. Our algorithm not only makes the task of obtaining cardinally-minimal explanations feasible, but even outperforms existing algorithms designed to find the relaxed variant of subset-minimal explanations - which may be larger and less informative but easier to compute - despite our algorithm solving a much more difficult task. Our experiments demonstrate that, compared to previous algorithms, our approach provides provably smaller explanations than existing works and substantially reduces the computation time. Moreover, we show that our generated provable explanations offer benefits that are unattainable by standard sampling-based techniques typically used to interpret NAMs.
Formal Mechanistic Interpretability: Automated Circuit Discovery with Provable Guarantees
Feb 18, 2026*Automated circuit discovery* is a central tool in mechanistic interpretability for identifying the internal components of neural networks responsible for specific behaviors. While prior methods have made significant progress, they typically depend on heuristics or approximations and do not offer provable guarantees over continuous input domains for the resulting circuits. In this work, we leverage recent advances in neural network verification to propose a suite of automated algorithms that yield circuits with *provable guarantees*. We focus on three types of guarantees: (1) *input domain robustness*, ensuring the circuit agrees with the model across a continuous input region; (2) *robust patching*, certifying circuit alignment under continuous patching perturbations; and (3) *minimality*, formalizing and capturing a wide array of various notions of succinctness. Interestingly, we uncover a diverse set of novel theoretical connections among these three families of guarantees, with critical implications for the convergence of our algorithms. Finally, we conduct experiments with state-of-the-art verifiers on various vision models, showing that our algorithms yield circuits with substantially stronger robustness guarantees than standard circuit discovery methods, establishing a principled foundation for provable circuit discovery.
Bridging Efficiency and Safety: Formal Verification of Neural Networks with Early Exits
Dec 23, 2025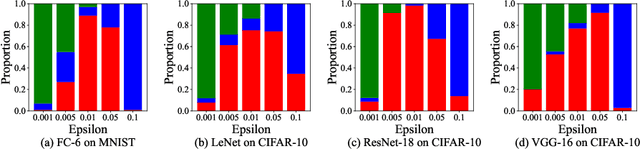
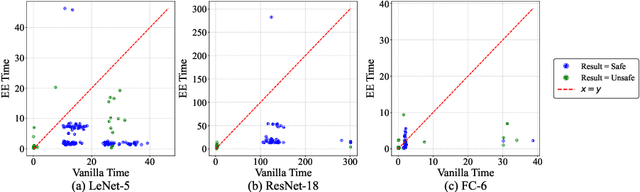


Ensuring the safety and efficiency of AI systems is a central goal of modern research. Formal verification provides guarantees of neural network robustness, while early exits improve inference efficiency by enabling intermediate predictions. Yet verifying networks with early exits introduces new challenges due to their conditional execution paths. In this work, we define a robustness property tailored to early exit architectures and show how off-the-shelf solvers can be used to assess it. We present a baseline algorithm, enhanced with an early stopping strategy and heuristic optimizations that maintain soundness and completeness. Experiments on multiple benchmarks validate our framework's effectiveness and demonstrate the performance gains of the improved algorithm. Alongside the natural inference acceleration provided by early exits, we show that they also enhance verifiability, enabling more queries to be solved in less time compared to standard networks. Together with a robustness analysis, we show how these metrics can help users navigate the inherent trade-off between accuracy and efficiency.
On Improving Deep Active Learning with Formal Verification
Dec 16, 2025Deep Active Learning (DAL) aims to reduce labeling costs in neural-network training by prioritizing the most informative unlabeled samples for annotation. Beyond selecting which samples to label, several DAL approaches further enhance data efficiency by augmenting the training set with synthetic inputs that do not require additional manual labeling. In this work, we investigate how augmenting the training data with adversarial inputs that violate robustness constraints can improve DAL performance. We show that adversarial examples generated via formal verification contribute substantially more than those produced by standard, gradient-based attacks. We apply this extension to multiple modern DAL techniques, as well as to a new technique that we propose, and show that it yields significant improvements in model generalization across standard benchmarks.