 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Reliable Training of Learning-Based Aerospace Controllers
Jul 09, 2024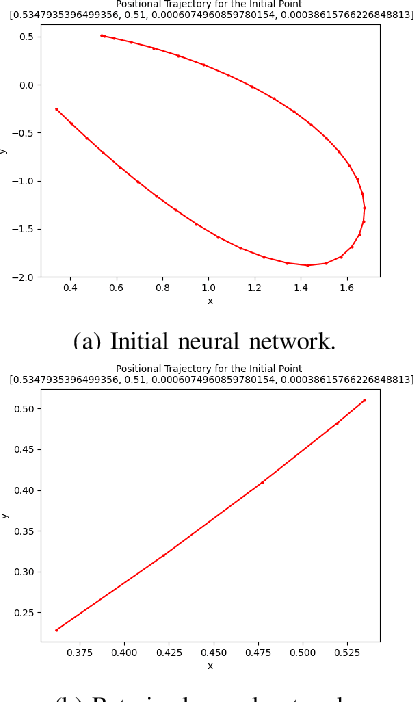


In recent years, deep reinforcement learning (DRL) approaches have generated highly successful controllers for a myriad of complex domains. However, the opaque nature of these models limits their applicability in aerospace systems and safety-critical domains, in which a single mistake can have dire consequences. In this paper, we present novel advancements in both the training and verification of DRL controllers, which can help ensure their safe behavior. We showcase a design-for-verification approach utilizing k-induction and demonstrate its use in verifying liveness properties. In addition, we also give a brief overview of neural Lyapunov Barrier certificates and summarize their capabilities on a case study. Finally, we describe several other novel reachability-based approaches which, despite failing to provide guarantees of interest, could be effective for verification of other DRL systems, and could be of further interest to the community.
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
May 22, 2024
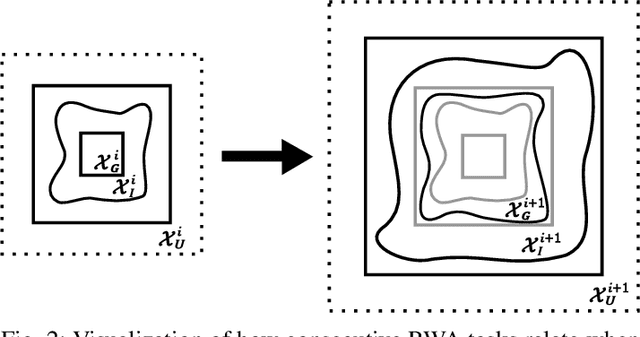
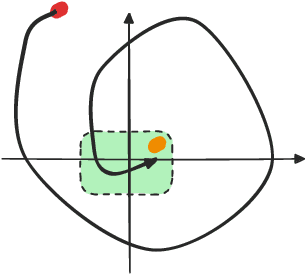
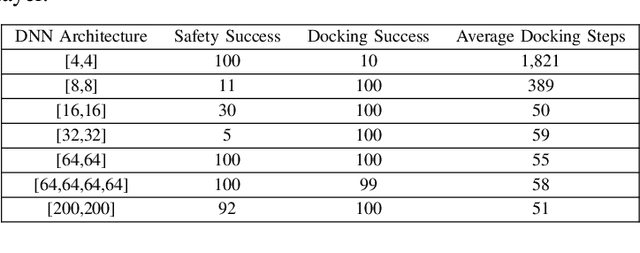
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the "black box" nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
Sep 22, 2023



Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
Automating UAV Flight Readiness Approval using Goal-Directed Answer Set Programming
Aug 25, 2022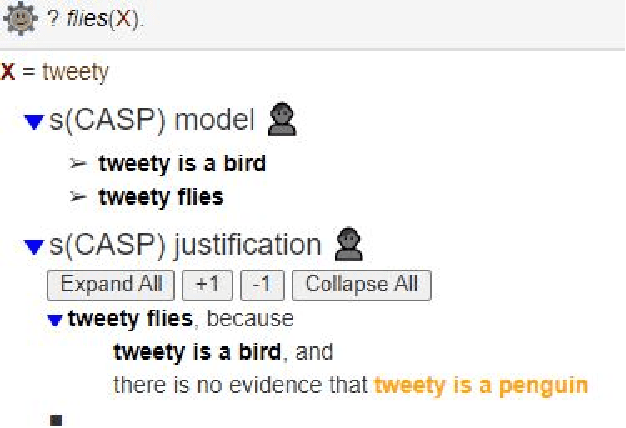
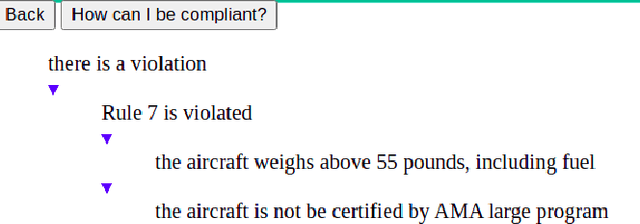
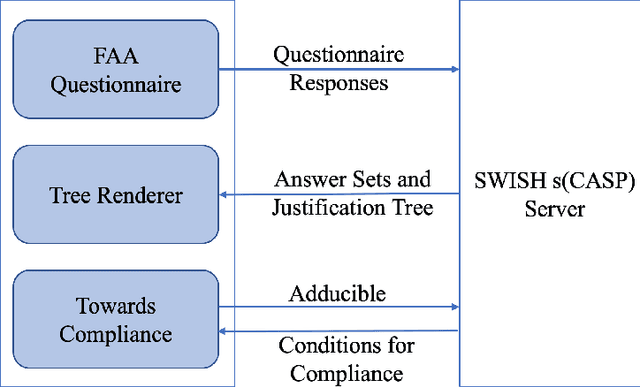
We present a novel application of Goal-Directed Answer Set Programming that digitizes the model aircraft operator's compliance verification against the Academy of Model Aircrafts (AMA) safety code. The AMA safety code regulates how AMA flyers operate Unmanned Aerial Vehicles (UAVs) for limited recreational purposes. Flying drones and their operators are subject to various rules before and after the operation of the aircraft to ensure safe flights. In this paper, we leverage Answer Set Programming to encode the AMA safety code and automate compliance checks. To check compliance, we use the s(CASP) which is a goal-directed ASP engine. By using s(CASP) the operators can easily check for violations and obtain a justification tree explaining the cause of the violations in human-readable natural language. Further, we implement an algorithm to help the operators obtain the minimal set of conditions that need to be satisfied in order to pass the compliance check. We develop a front-end questionnaire interface that accepts various conditions and use the backend s(CASP) engine to evaluate whether the conditions adhere to the regulations. We also leverage s(CASP) implemented in SWI-Prolog, where SWI-Prolog exposes the reasoning capabilities of s(CASP) as a REST service. To the best of our knowledge, this is the first application of ASP in the AMA and Avionics Compliance and Certification space.