 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Improving Deep Active Learning with Formal Verification
Dec 16, 2025Deep Active Learning (DAL) aims to reduce labeling costs in neural-network training by prioritizing the most informative unlabeled samples for annotation. Beyond selecting which samples to label, several DAL approaches further enhance data efficiency by augmenting the training set with synthetic inputs that do not require additional manual labeling. In this work, we investigate how augmenting the training data with adversarial inputs that violate robustness constraints can improve DAL performance. We show that adversarial examples generated via formal verification contribute substantially more than those produced by standard, gradient-based attacks. We apply this extension to multiple modern DAL techniques, as well as to a new technique that we propose, and show that it yields significant improvements in model generalization across standard benchmarks.
What makes an Ensemble (Un) Interpretable?
Jun 09, 2025Ensemble models are widely recognized in the ML community for their limited interpretability. For instance, while a single decision tree is considered interpretable, ensembles of trees (e.g., boosted trees) are often treated as black-boxes. Despite this folklore recognition, there remains a lack of rigorous mathematical understanding of what particularly makes an ensemble (un)-interpretable, including how fundamental factors like the (1) *number*, (2) *size*, and (3) *type* of base models influence its interpretability. In this work, we seek to bridge this gap by applying concepts from computational complexity theory to study the challenges of generating explanations for various ensemble configurations. Our analysis uncovers nuanced complexity patterns influenced by various factors. For example, we demonstrate that under standard complexity assumptions like P$\neq$NP, interpreting ensembles remains intractable even when base models are of constant size. Surprisingly, the complexity changes drastically with the number of base models: small ensembles of decision trees are efficiently interpretable, whereas interpreting ensembles with even a constant number of linear models remains intractable. We believe that our findings provide a more robust foundation for understanding the interpretability of ensembles, emphasizing the benefits of examining it through a computational complexity lens.
Hard to Explain: On the Computational Hardness of In-Distribution Model Interpretation
Aug 07, 2024

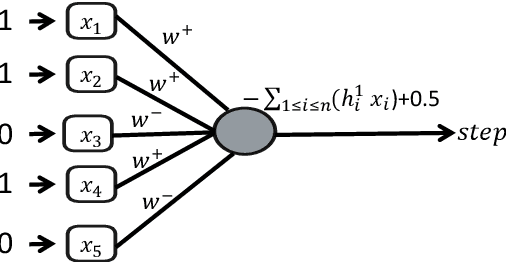

The ability to interpret Machine Learning (ML) models is becoming increasingly essential. However, despite significant progress in the field, there remains a lack of rigorous characterization regarding the innate interpretability of different models. In an attempt to bridge this gap, recent work has demonstrated that it is possible to formally assess interpretability by studying the computational complexity of explaining the decisions of various models. In this setting, if explanations for a particular model can be obtained efficiently, the model is considered interpretable (since it can be explained ``easily''). However, if generating explanations over an ML model is computationally intractable, it is considered uninterpretable. Prior research identified two key factors that influence the complexity of interpreting an ML model: (i) the type of the model (e.g., neural networks, decision trees, etc.); and (ii) the form of explanation (e.g., contrastive explanations, Shapley values, etc.). In this work, we claim that a third, important factor must also be considered for this analysis -- the underlying distribution over which the explanation is obtained. Considering the underlying distribution is key in avoiding explanations that are socially misaligned, i.e., convey information that is biased and unhelpful to users. We demonstrate the significant influence of the underlying distribution on the resulting overall interpretation complexity, in two settings: (i) prediction models paired with an external out-of-distribution (OOD) detector; and (ii) prediction models designed to inherently generate socially aligned explanations. Our findings prove that the expressiveness of the distribution can significantly influence the overall complexity of interpretation, and identify essential prerequisites that a model must possess to generate socially aligned explanations.
Safe and Reliable Training of Learning-Based Aerospace Controllers
Jul 09, 2024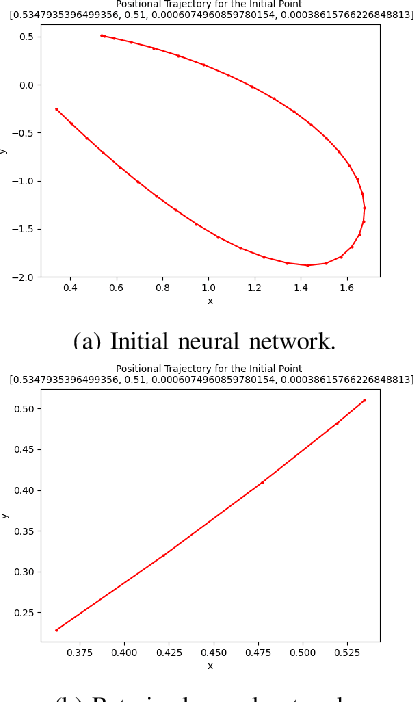


In recent years, deep reinforcement learning (DRL) approaches have generated highly successful controllers for a myriad of complex domains. However, the opaque nature of these models limits their applicability in aerospace systems and safety-critical domains, in which a single mistake can have dire consequences. In this paper, we present novel advancements in both the training and verification of DRL controllers, which can help ensure their safe behavior. We showcase a design-for-verification approach utilizing k-induction and demonstrate its use in verifying liveness properties. In addition, we also give a brief overview of neural Lyapunov Barrier certificates and summarize their capabilities on a case study. Finally, we describe several other novel reachability-based approaches which, despite failing to provide guarantees of interest, could be effective for verification of other DRL systems, and could be of further interest to the community.
Verification-Guided Shielding for Deep Reinforcement Learning
Jun 10, 2024



In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, which limits their deployment in safety-critical domains. As a result, various methods have been put forth to address this issue by providing formal safety guarantees. Two main approaches include shielding and verification. While shielding ensures the safe behavior of the policy by employing an external online component (i.e., a ``shield'') that overruns potentially dangerous actions, this approach has a significant computational cost as the shield must be invoked at runtime to validate every decision. On the other hand, verification is an offline process that can identify policies that are unsafe, prior to their deployment, yet, without providing alternative actions when such a policy is deemed unsafe. In this work, we present verification-guided shielding -- a novel approach that bridges the DRL reliability gap by integrating these two methods. Our approach combines both formal and probabilistic verification tools to partition the input domain into safe and unsafe regions. In addition, we employ clustering and symbolic representation procedures that compress the unsafe regions into a compact representation. This, in turn, allows to temporarily activate the shield solely in (potentially) unsafe regions, in an efficient manner. Our novel approach allows to significantly reduce runtime overhead while still preserving formal safety guarantees. We extensively evaluate our approach on two benchmarks from the robotic navigation domain, as well as provide an in-depth analysis of its scalability and completeness.
Local vs. Global Interpretability: A Computational Complexity Perspective
Jun 07, 2024
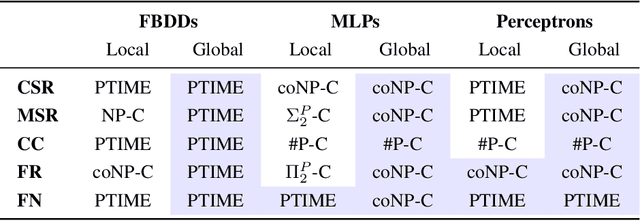
The local and global interpretability of various ML models has been studied extensively in recent years. However, despite significant progress in the field, many known results remain informal or lack sufficient mathematical rigor. We propose a framework for bridging this gap, by using computational complexity theory to assess local and global perspectives of interpreting ML models. We begin by proposing proofs for two novel insights that are essential for our analysis: (1) a duality between local and global forms of explanations; and (2) the inherent uniqueness of certain global explanation forms. We then use these insights to evaluate the complexity of computing explanations, across three model types representing the extremes of the interpretability spectrum: (1) linear models; (2) decision trees; and (3) neural networks. Our findings offer insights into both the local and global interpretability of these models. For instance, under standard complexity assumptions such as P != NP, we prove that selecting global sufficient subsets in linear models is computationally harder than selecting local subsets. Interestingly, with neural networks and decision trees, the opposite is true: it is harder to carry out this task locally than globally. We believe that our findings demonstrate how examining explainability through a computational complexity lens can help us develop a more rigorous grasp of the inherent interpretability of ML models.
Shield Synthesis for LTL Modulo Theories
Jun 06, 2024



In recent years, Machine Learning (ML) models have achieved remarkable success in various domains. However, these models also tend to demonstrate unsafe behaviors, precluding their deployment in safety-critical systems. To cope with this issue, ample research focuses on developing methods that guarantee the safe behaviour of a given ML model. A prominent example is shielding which incorporates an external component (a "shield") that blocks unwanted behavior. Despite significant progress, shielding suffers from a main setback: it is currently geared towards properties encoded solely in propositional logics (e.g., LTL) and is unsuitable for richer logics. This, in turn, limits the widespread applicability of shielding in many real-world systems. In this work, we address this gap, and extend shielding to LTL modulo theories, by building upon recent advances in reactive synthesis modulo theories. This allowed us to develop a novel approach for generating shields conforming to complex safety specifications in these more expressive, logics. We evaluated our shields and demonstrate their ability to handle rich data with temporal dynamics. To the best of our knowledge, this is the first approach for synthesizing shields for such expressivity.
Verifying the Generalization of Deep Learning to Out-of-Distribution Domains
Jun 04, 2024



Deep neural networks (DNNs) play a crucial role in the field of machine learning, demonstrating state-of-the-art performance across various application domains. However, despite their success, DNN-based models may occasionally exhibit challenges with generalization, i.e., may fail to handle inputs that were not encountered during training. This limitation is a significant challenge when it comes to deploying deep learning for safety-critical tasks, as well as in real-world settings characterized by substantial variability. We introduce a novel approach for harnessing DNN verification technology to identify DNN-driven decision rules that exhibit robust generalization to previously unencountered input domains. Our method assesses generalization within an input domain by measuring the level of agreement between independently trained deep neural networks for inputs in this domain. We also efficiently realize our approach by using off-the-shelf DNN verification engines, and extensively evaluate it on both supervised and unsupervised DNN benchmarks, including a deep reinforcement learning (DRL) system for Internet congestion control -- demonstrating the applicability of our approach for real-world settings. Moreover, our research introduces a fresh objective for formal verification, offering the prospect of mitigating the challenges linked to deploying DNN-driven systems in real-world scenarios.
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
May 22, 2024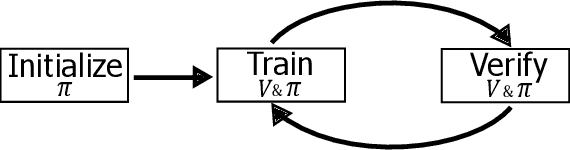
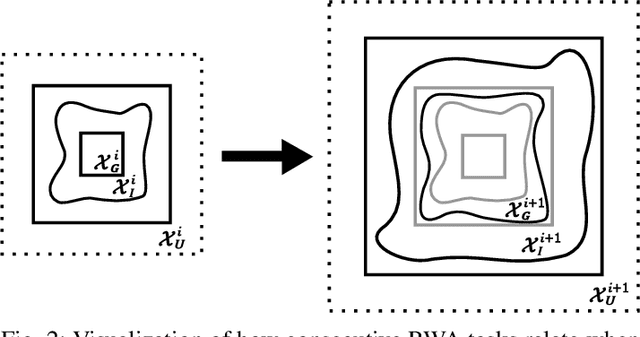
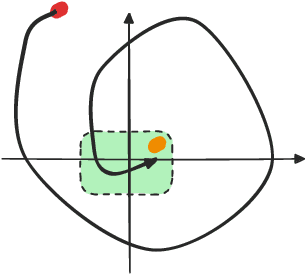
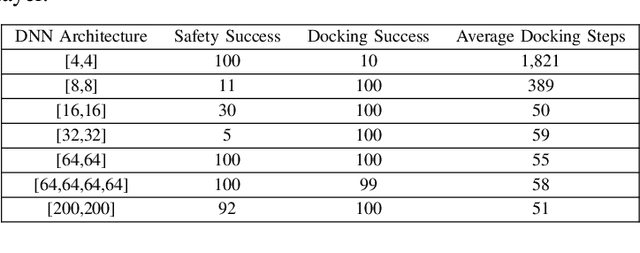
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the "black box" nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
Analyzing Adversarial Inputs in Deep Reinforcement Learning
Feb 07, 2024In recent years, Deep Reinforcement Learning (DRL) has become a popular paradigm in machine learning due to its successful applications to real-world and complex systems. However, even the state-of-the-art DRL models have been shown to suffer from reliability concerns -- for example, their susceptibility to adversarial inputs, i.e., small and abundant input perturbations that can fool the models into making unpredictable and potentially dangerous decisions. This drawback limits the deployment of DRL systems in safety-critical contexts, where even a small error cannot be tolerated. In this work, we present a comprehensive analysis of the characterization of adversarial inputs, through the lens of formal verification. Specifically, we introduce a novel metric, the Adversarial Rate, to classify models based on their susceptibility to such perturbations, and present a set of tools and algorithms for its computation. Our analysis empirically demonstrates how adversarial inputs can affect the safety of a given DRL system with respect to such perturbations. Moreover, we analyze the behavior of these configurations to suggest several useful practices and guidelines to help mitigate the vulnerability of trained DRL networks.