 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation models on the bridge: Semantic hazard detection and safety maneuvers for maritime autonomy with vision-language models
Dec 30, 2025The draft IMO MASS Code requires autonomous and remotely supervised maritime vessels to detect departures from their operational design domain, enter a predefined fallback that notifies the operator, permit immediate human override, and avoid changing the voyage plan without approval. Meeting these obligations in the alert-to-takeover gap calls for a short-horizon, human-overridable fallback maneuver. Classical maritime autonomy stacks struggle when the correct action depends on meaning (e.g., diver-down flag means people in the water, fire close by means hazard). We argue (i) that vision-language models (VLMs) provide semantic awareness for such out-of-distribution situations, and (ii) that a fast-slow anomaly pipeline with a short-horizon, human-overridable fallback maneuver makes this practical in the handover window. We introduce Semantic Lookout, a camera-only, candidate-constrained vision-language model (VLM) fallback maneuver selector that selects one cautious action (or station-keeping) from water-valid, world-anchored trajectories under continuous human authority. On 40 harbor scenes we measure per-call scene understanding and latency, alignment with human consensus (model majority-of-three voting), short-horizon risk-relief on fire hazard scenes, and an on-water alert->fallback maneuver->operator handover. Sub-10 s models retain most of the awareness of slower state-of-the-art models. The fallback maneuver selector outperforms geometry-only baselines and increases standoff distance on fire scenes. A field run verifies end-to-end operation. These results support VLMs as semantic fallback maneuver selectors compatible with the draft IMO MASS Code, within practical latency budgets, and motivate future work on domain-adapted, hybrid autonomy that pairs foundation-model semantics with multi-sensor bird's-eye-view perception and short-horizon replanning.
Real-Time Out-of-Distribution Failure Prevention via Multi-Modal Reasoning
May 15, 2025Foundation models can provide robust high-level reasoning on appropriate safety interventions in hazardous scenarios beyond a robot's training data, i.e. out-of-distribution (OOD) failures. However, due to the high inference latency of Large Vision and Language Models, current methods rely on manually defined intervention policies to enact fallbacks, thereby lacking the ability to plan generalizable, semantically safe motions. To overcome these challenges we present FORTRESS, a framework that generates and reasons about semantically safe fallback strategies in real time to prevent OOD failures. At a low frequency in nominal operations, FORTRESS uses multi-modal reasoners to identify goals and anticipate failure modes. When a runtime monitor triggers a fallback response, FORTRESS rapidly synthesizes plans to fallback goals while inferring and avoiding semantically unsafe regions in real time. By bridging open-world, multi-modal reasoning with dynamics-aware planning, we eliminate the need for hard-coded fallbacks and human safety interventions. FORTRESS outperforms on-the-fly prompting of slow reasoning models in safety classification accuracy on synthetic benchmarks and real-world ANYmal robot data, and further improves system safety and planning success in simulation and on quadrotor hardware for urban navigation.
Hamilton-Jacobi Reachability in Reinforcement Learning: A Survey
Jul 12, 2024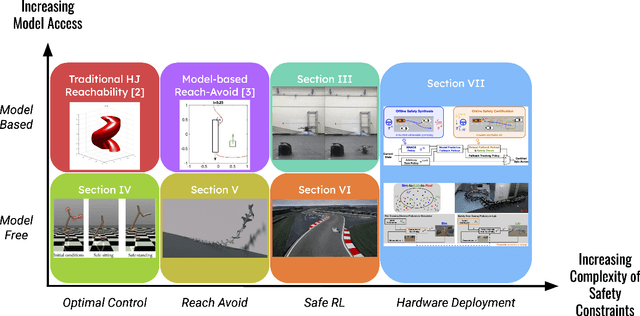


Recent literature has proposed approaches that learn control policies with high performance while maintaining safety guarantees. Synthesizing Hamilton-Jacobi (HJ) reachable sets has become an effective tool for verifying safety and supervising the training of reinforcement learning-based control policies for complex, high-dimensional systems. Previously, HJ reachability was limited to verifying low-dimensional dynamical systems -- this is because the computational complexity of the dynamic programming approach it relied on grows exponentially with the number of system states. To address this limitation, in recent years, there have been methods that compute the reachability value function simultaneously with learning control policies to scale HJ reachability analysis while still maintaining a reliable estimate of the true reachable set. These HJ reachability approximations are used to improve the safety, and even reward performance, of learned control policies and can solve challenging tasks such as those with dynamic obstacles and/or with lidar-based or vision-based observations. In this survey paper, we review the recent developments in the field of HJ reachability estimation in reinforcement learning that would provide a foundational basis for further research into reliability in high-dimensional systems.
Safe and Reliable Training of Learning-Based Aerospace Controllers
Jul 09, 2024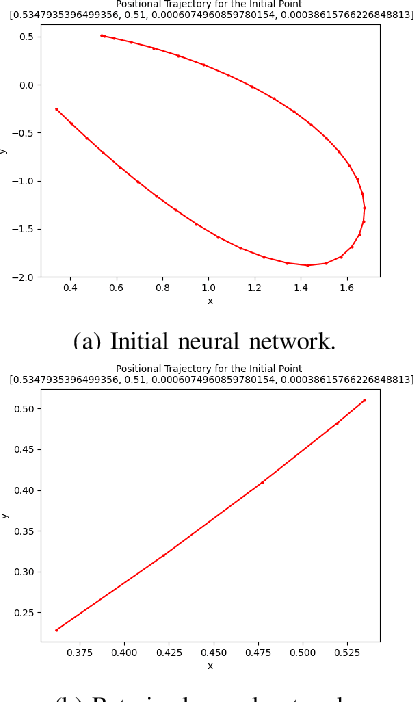


In recent years, deep reinforcement learning (DRL) approaches have generated highly successful controllers for a myriad of complex domains. However, the opaque nature of these models limits their applicability in aerospace systems and safety-critical domains, in which a single mistake can have dire consequences. In this paper, we present novel advancements in both the training and verification of DRL controllers, which can help ensure their safe behavior. We showcase a design-for-verification approach utilizing k-induction and demonstrate its use in verifying liveness properties. In addition, we also give a brief overview of neural Lyapunov Barrier certificates and summarize their capabilities on a case study. Finally, we describe several other novel reachability-based approaches which, despite failing to provide guarantees of interest, could be effective for verification of other DRL systems, and could be of further interest to the community.
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
May 22, 2024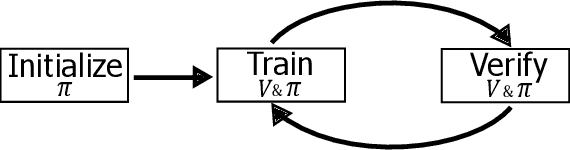
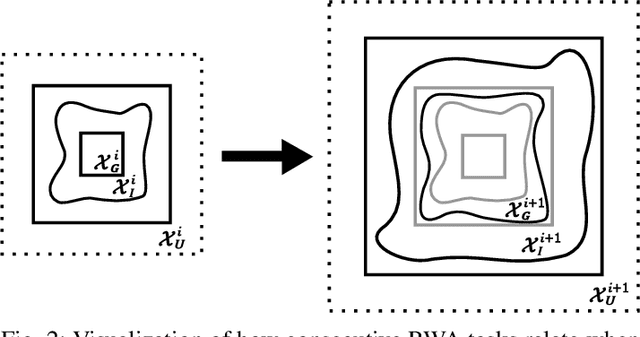
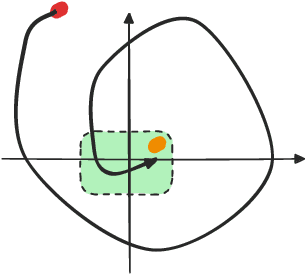
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the "black box" nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
Iterative Reachability Estimation for Safe Reinforcement Learning
Sep 24, 2023
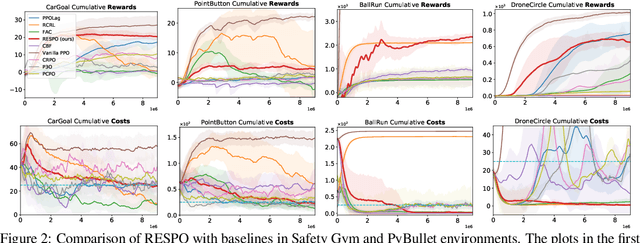
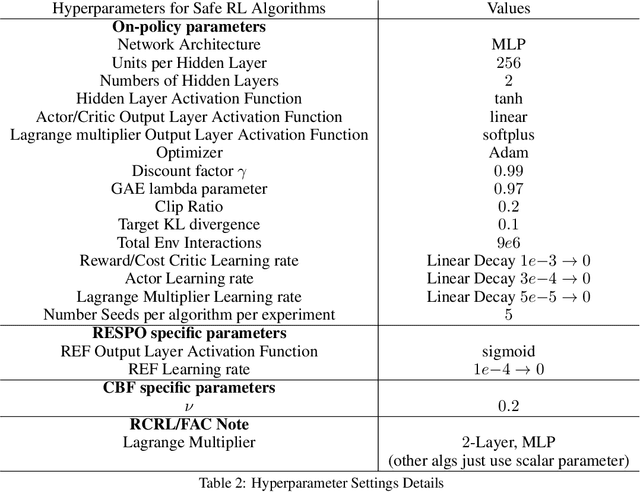

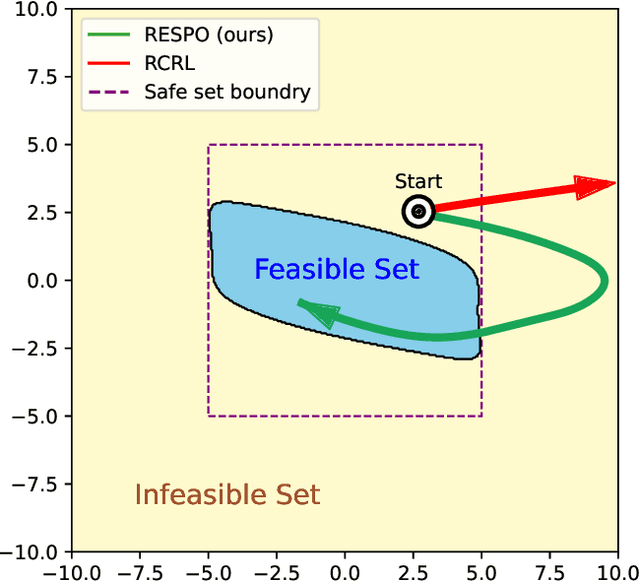
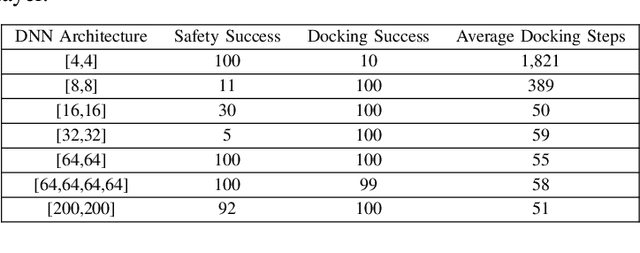
Ensuring safety is important for the practical deployment of reinforcement learning (RL). Various challenges must be addressed, such as handling stochasticity in the environments, providing rigorous guarantees of persistent state-wise safety satisfaction, and avoiding overly conservative behaviors that sacrifice performance. We propose a new framework, Reachability Estimation for Safe Policy Optimization (RESPO), for safety-constrained RL in general stochastic settings. In the feasible set where there exist violation-free policies, we optimize for rewards while maintaining persistent safety. Outside this feasible set, our optimization produces the safest behavior by guaranteeing entrance into the feasible set whenever possible with the least cumulative discounted violations. We introduce a class of algorithms using our novel reachability estimation function to optimize in our proposed framework and in similar frameworks such as those concurrently handling multiple hard and soft constraints. We theoretically establish that our algorithms almost surely converge to locally optimal policies of our safe optimization framework. We evaluate the proposed methods on a diverse suite of safe RL environments from Safety Gym, PyBullet, and MuJoCo, and show the benefits in improving both reward performance and safety compared with state-of-the-art baselines.
Target-independent XLA optimization using Reinforcement Learning
Aug 28, 2023An important challenge in Machine Learning compilers like XLA is multi-pass optimization and analysis. There has been recent interest chiefly in XLA target-dependent optimization on the graph-level, subgraph-level, and kernel-level phases. We specifically focus on target-independent optimization XLA HLO pass ordering: our approach aims at finding the optimal sequence of compiler optimization passes, which is decoupled from target-dependent optimization. However, there is little domain specific study in pass ordering for XLA HLO. To this end, we propose introducing deep Reinforcement Learning (RL) based search for optimal XLA HLO pass ordering. We also propose enhancements to the deep RL algorithms to further improve optimal search performance and open the research direction for domain-specific guidance for RL. We create an XLA Gym experimentation framework as a tool to enable RL algorithms to interact with the compiler for passing optimizations and thereby train agents. Overall, in our experimentation we observe an average of $13.3\%$ improvement in operation count reduction on a benchmark of GPT-2 training graphs and $10.4\%$ improvement on a diverse benchmark including GPT-2, BERT, and ResNet graphs using the proposed approach over the compiler's default phase ordering.
Learning Stabilization Control from Observations by Learning Lyapunov-like Proxy Models
Mar 03, 2023



The deployment of Reinforcement Learning to robotics applications faces the difficulty of reward engineering. Therefore, approaches have focused on creating reward functions by Learning from Observations (LfO) which is the task of learning policies from expert trajectories that only contain state sequences. We propose new methods for LfO for the important class of continuous control problems of learning to stabilize, by introducing intermediate proxy models acting as reward functions between the expert and the agent policy based on Lyapunov stability theory. Our LfO training process consists of two steps. The first step attempts to learn a Lyapunov-like landscape proxy model from expert state sequences without access to any kinematics model, and the second step uses the learned landscape model to guide in training the learner's policy. We formulate novel learning objectives for the two steps that are important for overall training success. We evaluate our methods in real automobile robot environments and other simulated stabilization control problems in model-free settings, like Quadrotor control and maintaining upright positions of Hopper in MuJoCo. We compare with state-of-the-art approaches and show the proposed methods can learn efficiently with less expert observations.