 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Maximum Entropy Misleads Policy Optimization
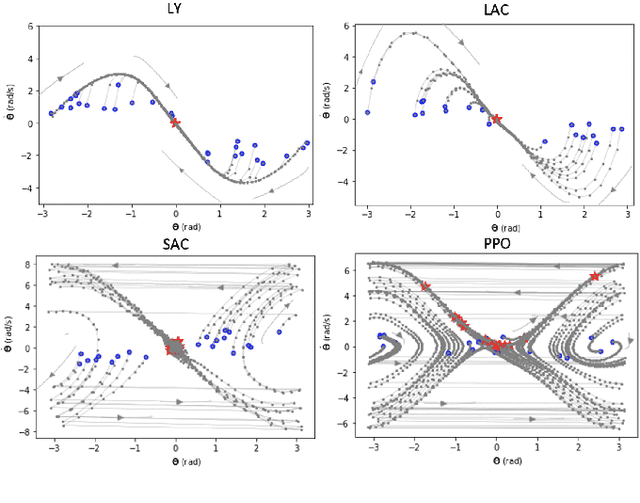
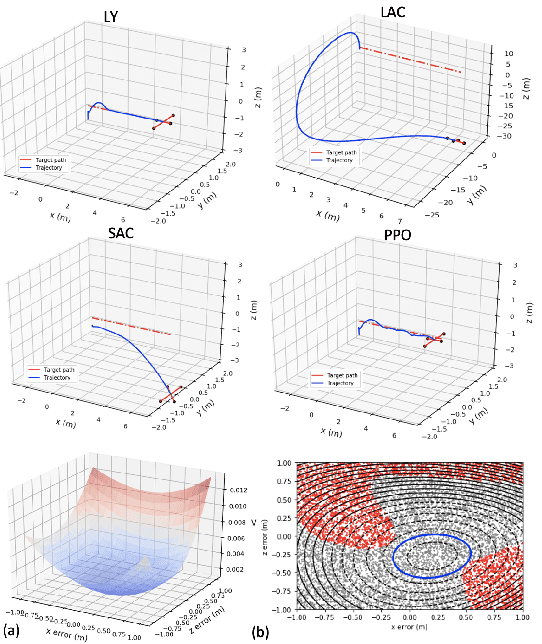
Jun 05, 2025The Maximum Entropy Reinforcement Learning (MaxEnt RL) framework is a leading approach for achieving efficient learning and robust performance across many RL tasks. However, MaxEnt methods have also been shown to struggle with performance-critical control problems in practice, where non-MaxEnt algorithms can successfully learn. In this work, we analyze how the trade-off between robustness and optimality affects the performance of MaxEnt algorithms in complex control tasks: while entropy maximization enhances exploration and robustness, it can also mislead policy optimization, leading to failure in tasks that require precise, low-entropy policies. Through experiments on a variety of control problems, we concretely demonstrate this misleading effect. Our analysis leads to better understanding of how to balance reward design and entropy maximization in challenging control problems.
Extremum-Seeking Action Selection for Accelerating Policy Optimization
Apr 02, 2024Reinforcement learning for control over continuous spaces typically uses high-entropy stochastic policies, such as Gaussian distributions, for local exploration and estimating policy gradient to optimize performance. Many robotic control problems deal with complex unstable dynamics, where applying actions that are off the feasible control manifolds can quickly lead to undesirable divergence. In such cases, most samples taken from the ambient action space generate low-value trajectories that hardly contribute to policy improvement, resulting in slow or failed learning. We propose to improve action selection in this model-free RL setting by introducing additional adaptive control steps based on Extremum-Seeking Control (ESC). On each action sampled from stochastic policies, we apply sinusoidal perturbations and query for estimated Q-values as the response signal. Based on ESC, we then dynamically improve the sampled actions to be closer to nearby optima before applying them to the environment. Our methods can be easily added in standard policy optimization to improve learning efficiency, which we demonstrate in various control learning environments.
Learning Stabilization Control from Observations by Learning Lyapunov-like Proxy Models
Mar 03, 2023



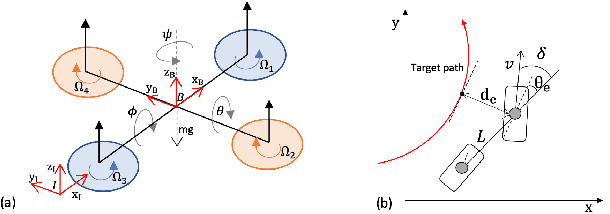
The deployment of Reinforcement Learning to robotics applications faces the difficulty of reward engineering. Therefore, approaches have focused on creating reward functions by Learning from Observations (LfO) which is the task of learning policies from expert trajectories that only contain state sequences. We propose new methods for LfO for the important class of continuous control problems of learning to stabilize, by introducing intermediate proxy models acting as reward functions between the expert and the agent policy based on Lyapunov stability theory. Our LfO training process consists of two steps. The first step attempts to learn a Lyapunov-like landscape proxy model from expert state sequences without access to any kinematics model, and the second step uses the learned landscape model to guide in training the learner's policy. We formulate novel learning objectives for the two steps that are important for overall training success. We evaluate our methods in real automobile robot environments and other simulated stabilization control problems in model-free settings, like Quadrotor control and maintaining upright positions of Hopper in MuJoCo. We compare with state-of-the-art approaches and show the proposed methods can learn efficiently with less expert observations.
Stabilizing Neural Control Using Self-Learned Almost Lyapunov Critics
Jul 11, 2021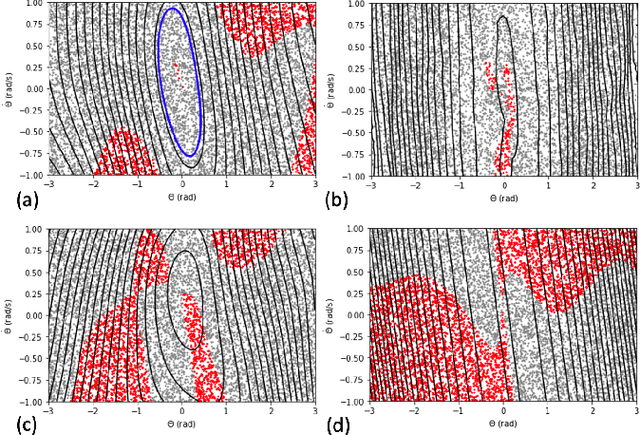
The lack of stability guarantee restricts the practical use of learning-based methods in core control problems in robotics. We develop new methods for learning neural control policies and neural Lyapunov critic functions in the model-free reinforcement learning (RL) setting. We use sample-based approaches and the Almost Lyapunov function conditions to estimate the region of attraction and invariance properties through the learned Lyapunov critic functions. The methods enhance stability of neural controllers for various nonlinear systems including automobile and quadrotor control.
Neural Lyapunov Control
May 20, 2020

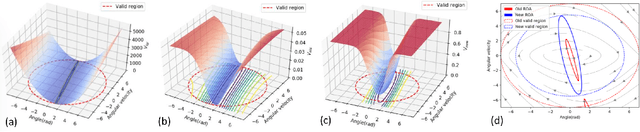
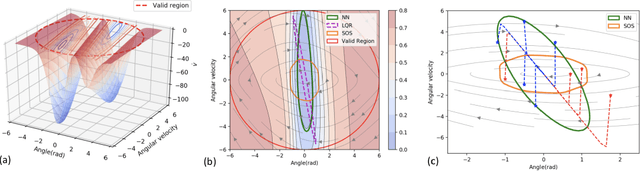
We propose new methods for learning control policies and neural network Lyapunov functions for nonlinear control problems, with provable guarantee of stability. The framework consists of a learner that attempts to find the control and Lyapunov functions, and a falsifier that finds counterexamples to quickly guide the learner towards solutions. The procedure terminates when no counterexample is found by the falsifier, in which case the controlled nonlinear system is provably stable. The approach significantly simplifies the process of Lyapunov control design, provides end-to-end correctness guarantee, and can obtain much larger regions of attraction than existing methods such as LQR and SOS/SDP. We show experiments on how the new methods obtain high-quality solutions for challenging control problems.