 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBellman Value Decomposition for Task Logic in Safe Optimal Control
Feb 23, 2026Real-world tasks involve nuanced combinations of goal and safety specifications. In high dimensions, the challenge is exacerbated: formal automata become cumbersome, and the combination of sparse rewards tends to require laborious tuning. In this work, we consider the innate structure of the Bellman Value as a means to naturally organize the problem for improved automatic performance. Namely, we prove the Bellman Value for a complex task defined in temporal logic can be decomposed into a graph of Bellman Values, connected by a set of well-known Bellman equations (BEs): the Reach-Avoid BE, the Avoid BE, and a novel type, the Reach-Avoid-Loop BE. To solve the Value and optimal policy, we propose VDPPO, which embeds the decomposed Value graph into a two-layer neural net, bootstrapping the implicit dependencies. We conduct a variety of simulated and hardware experiments to test our method on complex, high-dimensional tasks involving heterogeneous teams and nonlinear dynamics. Ultimately, we find this approach greatly improves performance over existing baselines, balancing safety and liveness automatically.
Safe Stochastic Explorer: Enabling Safe Goal Driven Exploration in Stochastic Environments and Safe Interaction with Unknown Objects
Jan 31, 2026Autonomous robots operating in unstructured, safety-critical environments, from planetary exploration to warehouses and homes, must learn to safely navigate and interact with their surroundings despite limited prior knowledge. Current methods for safe control, such as Hamilton-Jacobi Reachability and Control Barrier Functions, assume known system dynamics. Meanwhile existing safe exploration techniques often fail to account for the unavoidable stochasticity inherent when operating in unknown real world environments, such as an exploratory rover skidding over an unseen surface or a household robot pushing around unmapped objects in a pantry. To address this critical gap, we propose Safe Stochastic Explorer (S.S.Explorer) a novel framework for safe, goal-driven exploration under stochastic dynamics. Our approach strategically balances safety and information gathering to reduce uncertainty about safety in the unknown environment. We employ Gaussian Processes to learn the unknown safety function online, leveraging their predictive uncertainty to guide information-gathering actions and provide probabilistic bounds on safety violations. We first present our method for discrete state space environments and then introduce a scalable relaxation to effectively extend this approach to continuous state spaces. Finally we demonstrate how this framework can be naturally applied to ensure safe physical interaction with multiple unknown objects. Extensive validation in simulation and demonstrative hardware experiments showcase the efficacy of our method, representing a step forward toward enabling reliable widespread robot autonomy in complex, uncertain environments.
Learning to Nudge: A Scalable Barrier Function Framework for Safe Robot Interaction in Dense Clutter
Jan 06, 2026Robots operating in everyday environments must navigate and manipulate within densely cluttered spaces, where physical contact with surrounding objects is unavoidable. Traditional safety frameworks treat contact as unsafe, restricting robots to collision avoidance and limiting their ability to function in dense, everyday settings. As the number of objects grows, model-based approaches for safe manipulation become computationally intractable; meanwhile, learned methods typically tie safety to the task at hand, making them hard to transfer to new tasks without retraining. In this work we introduce Dense Contact Barrier Functions(DCBF). Our approach bypasses the computational complexity of explicitly modeling multi-object dynamics by instead learning a composable, object-centric function that implicitly captures the safety constraints arising from physical interactions. Trained offline on interactions with a few objects, the learned DCBFcomposes across arbitrary object sets at runtime, producing a single global safety filter that scales linearly and transfers across tasks without retraining. We validate our approach through simulated experiments in dense clutter, demonstrating its ability to enable collision-free navigation and safe, contact-rich interaction in suitable settings.
MADR: MPC-guided Adversarial DeepReach
Oct 21, 2025Hamilton-Jacobi (HJ) Reachability offers a framework for generating safe value functions and policies in the face of adversarial disturbance, but is limited by the curse of dimensionality. Physics-informed deep learning is able to overcome this infeasibility, but itself suffers from slow and inaccurate convergence, primarily due to weak PDE gradients and the complexity of self-supervised learning. A few works, recently, have demonstrated that enriching the self-supervision process with regular supervision (based on the nature of the optimal control problem), greatly accelerates convergence and solution quality, however, these have been limited to single player problems and simple games. In this work, we introduce MADR: MPC-guided Adversarial DeepReach, a general framework to robustly approximate the two-player, zero-sum differential game value function. In doing so, MADR yields the corresponding optimal strategies for both players in zero-sum games as well as safe policies for worst-case robustness. We test MADR on a multitude of high-dimensional simulated and real robotic agents with varying dynamics and games, finding that our approach significantly out-performs state-of-the-art baselines in simulation and produces impressive results in hardware.
Reachability Barrier Networks: Learning Hamilton-Jacobi Solutions for Smooth and Flexible Control Barrier Functions
May 16, 2025Recent developments in autonomous driving and robotics underscore the necessity of safety-critical controllers. Control barrier functions (CBFs) are a popular method for appending safety guarantees to a general control framework, but they are notoriously difficult to generate beyond low dimensions. Existing methods often yield non-differentiable or inaccurate approximations that lack integrity, and thus fail to ensure safety. In this work, we use physics-informed neural networks (PINNs) to generate smooth approximations of CBFs by computing Hamilton-Jacobi (HJ) optimal control solutions. These reachability barrier networks (RBNs) avoid traditional dimensionality constraints and support the tuning of their conservativeness post-training through a parameterized discount term. To ensure robustness of the discounted solutions, we leverage conformal prediction methods to derive probabilistic safety guarantees for RBNs. We demonstrate that RBNs are highly accurate in low dimensions, and safer than the standard neural CBF approach in high dimensions. Namely, we showcase the RBNs in a 9D multi-vehicle collision avoidance problem where it empirically proves to be 5.5x safer and 1.9x less conservative than the neural CBFs, offering a promising method to synthesize CBFs for general nonlinear autonomous systems.
Reach-Avoid-Stabilize Using Admissible Control Sets
May 14, 2025Hamilton-Jacobi Reachability (HJR) analysis has been successfully used in many robotics and control tasks, and is especially effective in computing reach-avoid sets and control laws that enable an agent to reach a goal while satisfying state constraints. However, the original HJR formulation provides no guarantees of safety after a) the prescribed time horizon, or b) goal satisfaction. The reach-avoid-stabilize (RAS) problem has therefore gained a lot of focus: find the set of initial states (the RAS set), such that the trajectory can reach the target, and stabilize to some point of interest (POI) while avoiding obstacles. Solving RAS problems using HJR usually requires defining a new value function, whose zero sub-level set is the RAS set. The existing methods do not consider the problem when there are a series of targets to reach and/or obstacles to avoid. We propose a method that uses the idea of admissible control sets; we guarantee that the system will reach each target while avoiding obstacles as prescribed by the given time series. Moreover, we guarantee that the trajectory ultimately stabilizes to the POI. The proposed method provides an under-approximation of the RAS set, guaranteeing safety. Numerical examples are provided to validate the theory.
Solving Reach- and Stabilize-Avoid Problems Using Discounted Reachability
May 14, 2025In this article, we consider the infinite-horizon reach-avoid (RA) and stabilize-avoid (SA) zero-sum game problems for general nonlinear continuous-time systems, where the goal is to find the set of states that can be controlled to reach or stabilize to a target set, without violating constraints even under the worst-case disturbance. Based on the Hamilton-Jacobi reachability method, we address the RA problem by designing a new Lipschitz continuous RA value function, whose zero sublevel set exactly characterizes the RA set. We establish that the associated Bellman backup operator is contractive and that the RA value function is the unique viscosity solution of a Hamilton-Jacobi variational inequality. Finally, we develop a two-step framework for the SA problem by integrating our RA strategies with a recently proposed Robust Control Lyapunov-Value Function, thereby ensuring both target reachability and long-term stability. We numerically verify our RA and SA frameworks on a 3D Dubins car system to demonstrate the efficacy of the proposed approach.
Back to Base: Towards Hands-Off Learning via Safe Resets with Reach-Avoid Safety Filters
Jan 05, 2025Designing controllers that accomplish tasks while guaranteeing safety constraints remains a significant challenge. We often want an agent to perform well in a nominal task, such as environment exploration, while ensuring it can avoid unsafe states and return to a desired target by a specific time. In particular we are motivated by the setting of safe, efficient, hands-off training for reinforcement learning in the real world. By enabling a robot to safely and autonomously reset to a desired region (e.g., charging stations) without human intervention, we can enhance efficiency and facilitate training. Safety filters, such as those based on control barrier functions, decouple safety from nominal control objectives and rigorously guarantee safety. Despite their success, constructing these functions for general nonlinear systems with control constraints and system uncertainties remains an open problem. This paper introduces a safety filter obtained from the value function associated with the reach-avoid problem. The proposed safety filter minimally modifies the nominal controller while avoiding unsafe regions and guiding the system back to the desired target set. By preserving policy performance while allowing safe resetting, we enable efficient hands-off reinforcement learning and advance the feasibility of safe training for real world robots. We demonstrate our approach using a modified version of soft actor-critic to safely train a swing-up task on a modified cartpole stabilization problem.
Hamilton-Jacobi Reachability in Reinforcement Learning: A Survey
Jul 12, 2024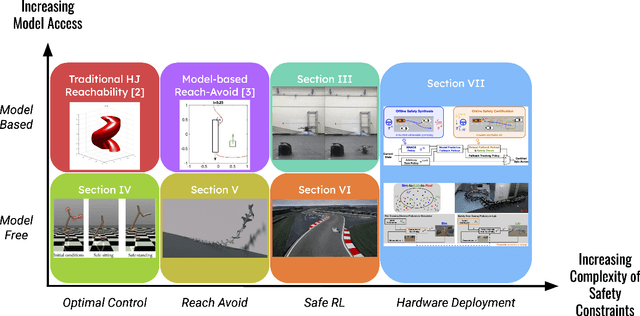


Recent literature has proposed approaches that learn control policies with high performance while maintaining safety guarantees. Synthesizing Hamilton-Jacobi (HJ) reachable sets has become an effective tool for verifying safety and supervising the training of reinforcement learning-based control policies for complex, high-dimensional systems. Previously, HJ reachability was limited to verifying low-dimensional dynamical systems -- this is because the computational complexity of the dynamic programming approach it relied on grows exponentially with the number of system states. To address this limitation, in recent years, there have been methods that compute the reachability value function simultaneously with learning control policies to scale HJ reachability analysis while still maintaining a reliable estimate of the true reachable set. These HJ reachability approximations are used to improve the safety, and even reward performance, of learned control policies and can solve challenging tasks such as those with dynamic obstacles and/or with lidar-based or vision-based observations. In this survey paper, we review the recent developments in the field of HJ reachability estimation in reinforcement learning that would provide a foundational basis for further research into reliability in high-dimensional systems.
Sensor-Based Distributionally Robust Control for Safe Robot Navigation in Dynamic Environments
May 28, 2024We introduce a novel method for safe mobile robot navigation in dynamic, unknown environments, utilizing onboard sensing to impose safety constraints without the need for accurate map reconstruction. Traditional methods typically rely on detailed map information to synthesize safe stabilizing controls for mobile robots, which can be computationally demanding and less effective, particularly in dynamic operational conditions. By leveraging recent advances in distributionally robust optimization, we develop a distributionally robust control barrier function (DR-CBF) constraint that directly processes range sensor data to impose safety constraints. Coupling this with a control Lyapunov function (CLF) for path tracking, we demonstrate that our CLF-DR-CBF control synthesis method achieves safe, efficient, and robust navigation in uncertain dynamic environments. We demonstrate the effectiveness of our approach in simulated and real autonomous robot navigation experiments, marking a substantial advancement in real-time safety guarantees for mobile robots.