 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What to Say to Your VLA: Mostly Harmless Vision Language Action Model Steering
Jun 10, 2026Vision-Language-Action (VLA) models provide a natural language interface to robot control, but the mapping from language to behavior is often brittle and unintuitive: semantically similar instructions can induce drastically different behaviors, while some capabilities may not be elicitable through prompting alone. As a result, both human instructions and zero-shot language models can fail to reliably steer VLAs toward successful task execution. In this work, we propose a framework that interactively searches for language sequences that improve closed-loop VLA task performance, distills these sequences into a test-time language feedback policy (LFP), and learns an improvement head that predicts when language steering will improve performance. We conformalize this improvement head to prevent harmful steering interventions, where the LFP decreases task performance relative to the original instruction on out-of-distribution scenarios. Crucially, our approach operates on arbitrary frozen pre-trained VLAs, requiring neither access to the original training distribution nor fine-tuning of the underlying model. On seen environments, our conformalized LFP improves base VLA performance by 24.7% in simulation and 65.0% in hardware. On visual and semantic perturbations, our conformalized LFP has strong harmlessness guarantees, and produces recovery behaviors not observed with open-loop prompting.
Reachability Barrier Networks: Learning Hamilton-Jacobi Solutions for Smooth and Flexible Control Barrier Functions
May 16, 2025Recent developments in autonomous driving and robotics underscore the necessity of safety-critical controllers. Control barrier functions (CBFs) are a popular method for appending safety guarantees to a general control framework, but they are notoriously difficult to generate beyond low dimensions. Existing methods often yield non-differentiable or inaccurate approximations that lack integrity, and thus fail to ensure safety. In this work, we use physics-informed neural networks (PINNs) to generate smooth approximations of CBFs by computing Hamilton-Jacobi (HJ) optimal control solutions. These reachability barrier networks (RBNs) avoid traditional dimensionality constraints and support the tuning of their conservativeness post-training through a parameterized discount term. To ensure robustness of the discounted solutions, we leverage conformal prediction methods to derive probabilistic safety guarantees for RBNs. We demonstrate that RBNs are highly accurate in low dimensions, and safer than the standard neural CBF approach in high dimensions. Namely, we showcase the RBNs in a 9D multi-vehicle collision avoidance problem where it empirically proves to be 5.5x safer and 1.9x less conservative than the neural CBFs, offering a promising method to synthesize CBFs for general nonlinear autonomous systems.
Robots that Suggest Safe Alternatives
Sep 15, 2024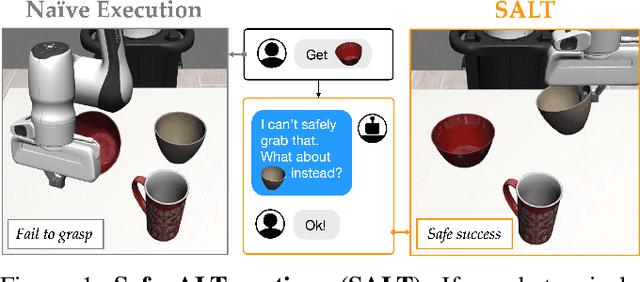
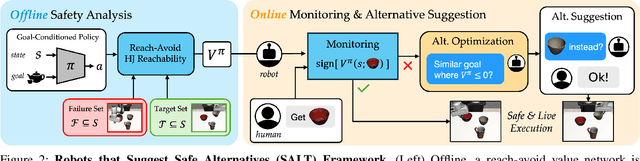
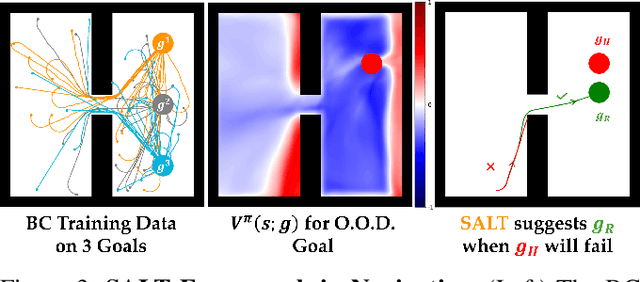
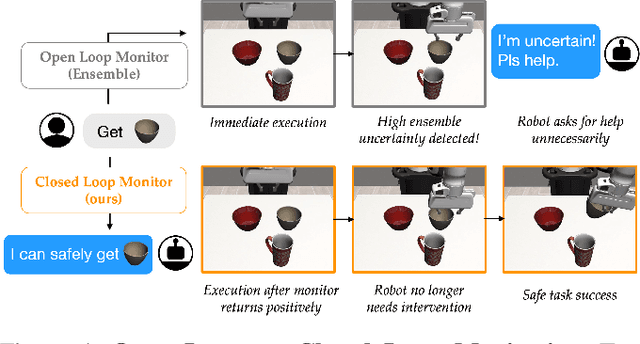
Goal-conditioned policies, such as those learned via imitation learning, provide an easy way for humans to influence what tasks robots accomplish. However, these robot policies are not guaranteed to execute safely or to succeed when faced with out-of-distribution requests. In this work, we enable robots to know when they can confidently execute a user's desired goal, and automatically suggest safe alternatives when they cannot. Our approach is inspired by control-theoretic safety filtering, wherein a safety filter minimally adjusts a robot's candidate action to be safe. Our key idea is to pose alternative suggestion as a safe control problem in goal space, rather than in action space. Offline, we use reachability analysis to compute a goal-parameterized reach-avoid value network which quantifies the safety and liveness of the robot's pre-trained policy. Online, our robot uses the reach-avoid value network as a safety filter, monitoring the human's given goal and actively suggesting alternatives that are similar but meet the safety specification. We demonstrate our Safe ALTernatives (SALT) framework in simulation experiments with indoor navigation and Franka Panda tabletop manipulation, and with both discrete and continuous goal representations. We find that SALT is able to learn to predict successful and failed closed-loop executions, is a less pessimistic monitor than open-loop uncertainty quantification, and proposes alternatives that consistently align with those people find acceptable.
Parameterized Fast and Safe Tracking (FaSTrack) using Deepreach
Apr 11, 2024Fast and Safe Tracking (FaSTrack) is a modular framework that provides safety guarantees while planning and executing trajectories in real time via value functions of Hamilton-Jacobi (HJ) reachability. These value functions are computed through dynamic programming, which is notorious for being computationally inefficient. Moreover, the resulting trajectory does not adapt online to the environment, such as sudden disturbances or obstacles. DeepReach is a scalable deep learning method to HJ reachability that allows parameterization of states, which opens up possibilities for online adaptation to various controls and disturbances. In this paper, we propose Parametric FaSTrack, which uses DeepReach to approximate a value function that parameterizes the control bounds of the planning model. The new framework can smoothly trade off between the navigation speed and the tracking error (therefore maneuverability) while guaranteeing obstacle avoidance in a priori unknown environments. We demonstrate our method through two examples and a benchmark comparison with existing methods, showing the safety, efficiency, and faster solution times of the framework.