 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAP Meets Tensor Networks: Provably Tractable Explanations with Parallelism
Oct 24, 2025Although Shapley additive explanations (SHAP) can be computed in polynomial time for simple models like decision trees, they unfortunately become NP-hard to compute for more expressive black-box models like neural networks - where generating explanations is often most critical. In this work, we analyze the problem of computing SHAP explanations for *Tensor Networks (TNs)*, a broader and more expressive class of models than those for which current exact SHAP algorithms are known to hold, and which is widely used for neural network abstraction and compression. First, we introduce a general framework for computing provably exact SHAP explanations for general TNs with arbitrary structures. Interestingly, we show that, when TNs are restricted to a *Tensor Train (TT)* structure, SHAP computation can be performed in *poly-logarithmic* time using *parallel* computation. Thanks to the expressiveness power of TTs, this complexity result can be generalized to many other popular ML models such as decision trees, tree ensembles, linear models, and linear RNNs, therefore tightening previously reported complexity results for these families of models. Finally, by leveraging reductions of binarized neural networks to Tensor Network representations, we demonstrate that SHAP computation can become *efficiently tractable* when the network's *width* is fixed, while it remains computationally hard even with constant *depth*. This highlights an important insight: for this class of models, width - rather than depth - emerges as the primary computational bottleneck in SHAP computation.
On the Computational Tractability of the (Many) Shapley Values
Feb 17, 2025Recent studies have examined the computational complexity of computing Shapley additive explanations (also known as SHAP) across various models and distributions, revealing their tractability or intractability in different settings. However, these studies primarily focused on a specific variant called Conditional SHAP, though many other variants exist and address different limitations. In this work, we analyze the complexity of computing a much broader range of such variants, including Conditional, Interventional, and Baseline SHAP, while exploring both local and global computations. We show that both local and global Interventional and Baseline SHAP can be computed in polynomial time for various ML models under Hidden Markov Model distributions, extending popular algorithms such as TreeSHAP beyond empirical distributions. On the downside, we prove intractability results for these variants over a wide range of neural networks and tree ensembles. We believe that our results emphasize the intricate diversity of computing Shapley values, demonstrating how their complexity is substantially shaped by both the specific SHAP variant, the model type, and the distribution.
Marginal Inference queries in Hidden Markov Models under context-free grammar constraints
Jun 26, 2022The primary use of any probabilistic model involving a set of random variables is to run inference and sampling queries on it. Inference queries in classical probabilistic models is concerned by the computation of marginal or conditional probabilities of events given as an input. When the probabilistic model is sequential, more sophisticated marginal inference queries involving complex grammars may be of interest in fields such as computational linguistics and NLP. In this work, we address the question of computing the likelihood of context-free grammars (CFGs) in Hidden Markov Models (HMMs). We provide a dynamic algorithm for the exact computation of the likelihood for the class of unambiguous context-free grammars. We show that the problem is NP-Hard, even with the promise that the input CFG has a degree of ambiguity less than or equal to 2. We then propose a fully polynomial randomized approximation scheme (FPRAS) algorithm to approximate the likelihood for the case of polynomially-bounded ambiguous CFGs.
On Computability, Learnability and Extractability of Finite State Machines from Recurrent Neural Networks
Sep 10, 2020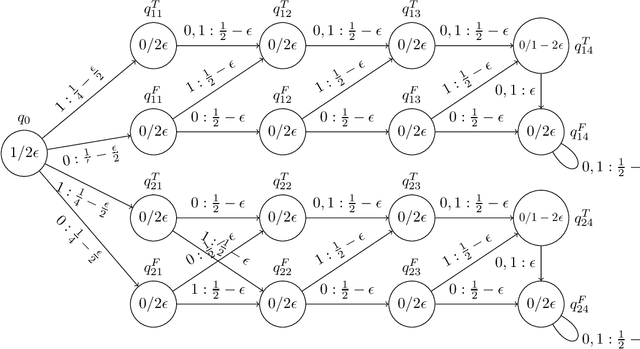

This work aims at shedding some light on connections between finite state machines (FSMs), and recurrent neural networks (RNNs). Examined connections in this master's thesis is threefold: the extractability of finite state machines from recurrent neural networks, learnability aspects and computationnal links. With respect to the former, the long-standing clustering hypothesis of RNN hidden state space when trained to recognize regular languages was explored, and new insights into this hypothesis through the lens of recent advances of the generalization theory of Deep Learning are provided. As for learnability, an extension of the active learning framework better suited to the problem of approximating RNNs with FSMs is proposed, with the aim of better formalizing the problem of RNN approximation by FSMs. Theoretical analysis of two possible scenarions in this framework were performed. With regard to computability, new computational results on the distance and the equivalence problem between RNNs trained as language models and different types of weighted finite state machines were given.
Distance and Equivalence between Finite State Machines and Recurrent Neural Networks: Computational results
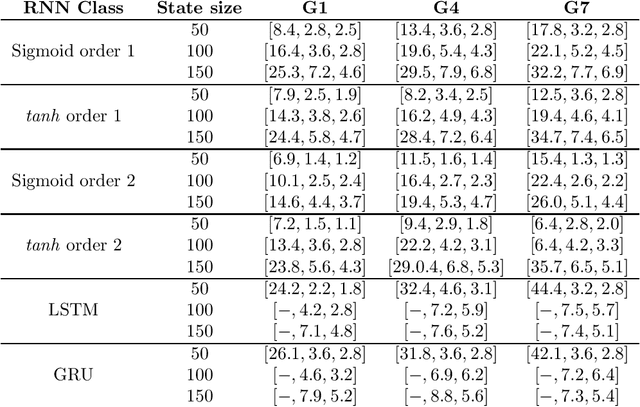
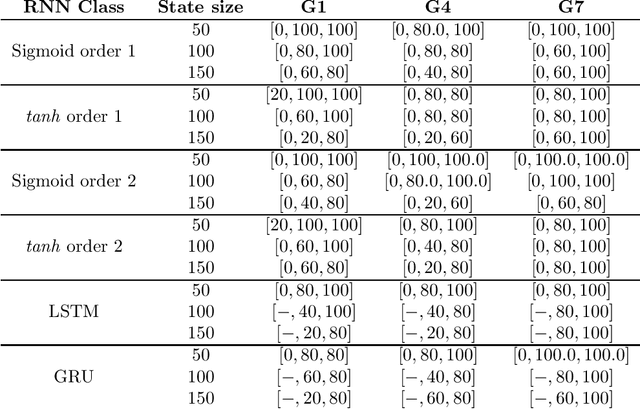
Apr 01, 2020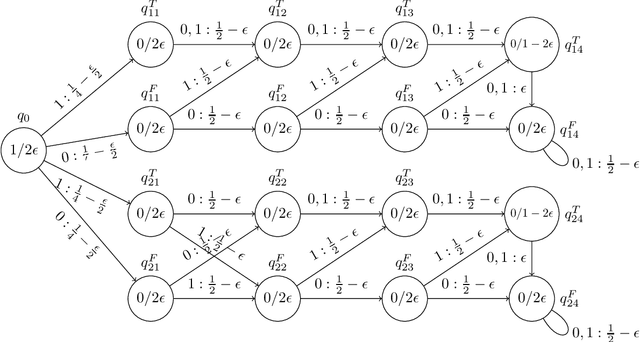
The need of interpreting Deep Learning (DL) models has led, during the past years, to a proliferation of works concerned by this issue. Among strategies which aim at shedding some light on how information is represented internally in DL models, one consists in extracting symbolic rule-based machines from connectionist models that are supposed to approximate well their behaviour. In order to better understand how reasonable these approximation strategies are, we need to know the computational complexity of measuring the quality of approximation. In this article, we will prove some computational results related to the problem of extracting Finite State Machine (FSM) based models from trained RNN Language models. More precisely, we'll show the following: (a) For general weighted RNN-LMs with a single hidden layer and a ReLu activation: - The equivalence problem of a PDFA/PFA/WFA and a weighted first-order RNN-LM is undecidable; - As a corollary, the distance problem between languages generated by PDFA/PFA/WFA and that of a weighted RNN-LM is not recursive; -The intersection between a DFA and the cut language of a weighted RNN-LM is undecidable; - The equivalence of a PDFA/PFA/WFA and weighted RNN-LM in a finite support is EXP-Hard; (b) For consistent weight RNN-LMs with any computable activation function: - The Tcheybechev distance approximation is decidable; - The Tcheybechev distance approximation in a finite support is NP-Hard. Moreover, our reduction technique from 3-SAT makes this latter fact easily generalizable to other RNN architectures (e.g. LSTMs/RNNs), and RNNs with finite precision.