 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 6th International Verification of Neural Networks Competition (VNN-COMP 2025): Summary and Results
Dec 22, 2025This report summarizes the 6th International Verification of Neural Networks Competition (VNN-COMP 2025), held as a part of the 8th International Symposium on AI Verification (SAIV), that was collocated with the 37th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2025 iteration, 8 teams participated on a diverse set of 16 regular and 9 extended benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
Combining LLMs with Logic-Based Framework to Explain MCTS
May 01, 2025

In response to the lack of trust in Artificial Intelligence (AI) for sequential planning, we design a Computational Tree Logic-guided large language model (LLM)-based natural language explanation framework designed for the Monte Carlo Tree Search (MCTS) algorithm. MCTS is often considered challenging to interpret due to the complexity of its search trees, but our framework is flexible enough to handle a wide range of free-form post-hoc queries and knowledge-based inquiries centered around MCTS and the Markov Decision Process (MDP) of the application domain. By transforming user queries into logic and variable statements, our framework ensures that the evidence obtained from the search tree remains factually consistent with the underlying environmental dynamics and any constraints in the actual stochastic control process. We evaluate the framework rigorously through quantitative assessments, where it demonstrates strong performance in terms of accuracy and factual consistency.
Blind Visible Watermark Removal with Morphological Dilation
Feb 04, 2025

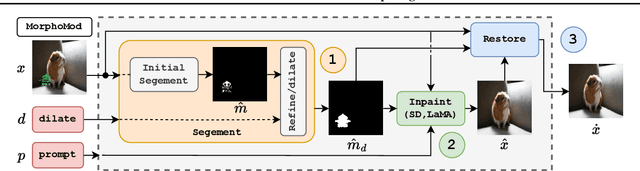

Visible watermarks pose significant challenges for image restoration techniques, especially when the target background is unknown. Toward this end, we present MorphoMod, a novel method for automated visible watermark removal that operates in a blind setting -- without requiring target images. Unlike existing methods, MorphoMod effectively removes opaque and transparent watermarks while preserving semantic content, making it well-suited for real-world applications. Evaluations on benchmark datasets, including the Colored Large-scale Watermark Dataset (CLWD), LOGO-series, and the newly introduced Alpha1 datasets, demonstrate that MorphoMod achieves up to a 50.8% improvement in watermark removal effectiveness compared to state-of-the-art methods. Ablation studies highlight the impact of prompts used for inpainting, pre-removal filling strategies, and inpainting model performance on watermark removal. Additionally, a case study on steganographic disorientation reveals broader applications for watermark removal in disrupting high-level hidden messages. MorphoMod offers a robust, adaptable solution for watermark removal and opens avenues for further advancements in image restoration and adversarial manipulation.
Neural Network Verification is a Programming Language Challenge
Jan 10, 2025
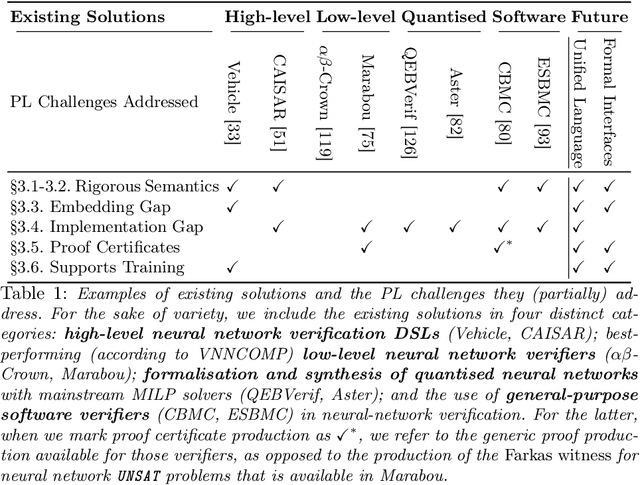


Neural network verification is a new and rapidly developing field of research. So far, the main priority has been establishing efficient verification algorithms and tools, while proper support from the programming language perspective has been considered secondary or unimportant. Yet, there is mounting evidence that insights from the programming language community may make a difference in the future development of this domain. In this paper, we formulate neural network verification challenges as programming language challenges and suggest possible future solutions.
* Accepted at ESOP 2025, European Symposium on Programming Languages
The Fifth International Verification of Neural Networks Competition (VNN-COMP 2024): Summary and Results
Dec 28, 2024

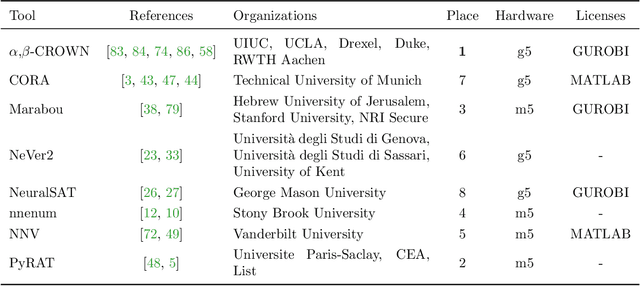

This report summarizes the 5th International Verification of Neural Networks Competition (VNN-COMP 2024), held as a part of the 7th International Symposium on AI Verification (SAIV), that was collocated with the 36th International Conference on Computer-Aided Verification (CAV). VNN-COMP is held annually to facilitate the fair and objective comparison of state-of-the-art neural network verification tools, encourage the standardization of tool interfaces, and bring together the neural network verification community. To this end, standardized formats for networks (ONNX) and specification (VNN-LIB) were defined, tools were evaluated on equal-cost hardware (using an automatic evaluation pipeline based on AWS instances), and tool parameters were chosen by the participants before the final test sets were made public. In the 2024 iteration, 8 teams participated on a diverse set of 12 regular and 8 extended benchmarks. This report summarizes the rules, benchmarks, participating tools, results, and lessons learned from this iteration of this competition.
PBP: Post-training Backdoor Purification for Malware Classifiers
Dec 05, 2024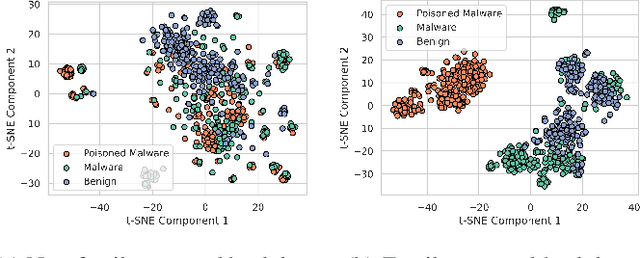
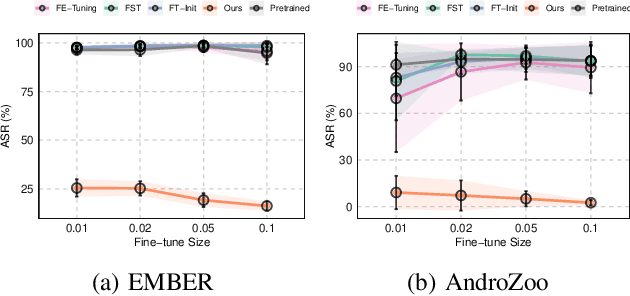
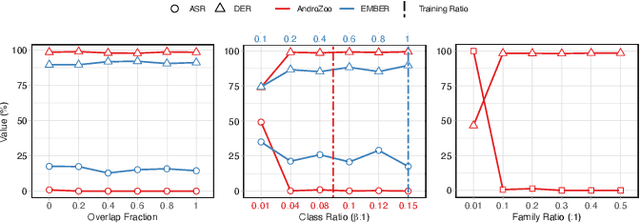
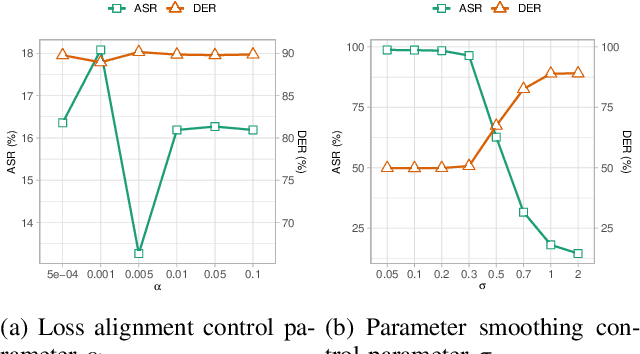
In recent years, the rise of machine learning (ML) in cybersecurity has brought new challenges, including the increasing threat of backdoor poisoning attacks on ML malware classifiers. For instance, adversaries could inject malicious samples into public malware repositories, contaminating the training data and potentially misclassifying malware by the ML model. Current countermeasures predominantly focus on detecting poisoned samples by leveraging disagreements within the outputs of a diverse set of ensemble models on training data points. However, these methods are not suitable for scenarios where Machine Learning-as-a-Service (MLaaS) is used or when users aim to remove backdoors from a model after it has been trained. Addressing this scenario, we introduce PBP, a post-training defense for malware classifiers that mitigates various types of backdoor embeddings without assuming any specific backdoor embedding mechanism. Our method exploits the influence of backdoor attacks on the activation distribution of neural networks, independent of the trigger-embedding method. In the presence of a backdoor attack, the activation distribution of each layer is distorted into a mixture of distributions. By regulating the statistics of the batch normalization layers, we can guide a backdoored model to perform similarly to a clean one. Our method demonstrates substantial advantages over several state-of-the-art methods, as evidenced by experiments on two datasets, two types of backdoor methods, and various attack configurations. Notably, our approach requires only a small portion of the training data -- only 1\% -- to purify the backdoor and reduce the attack success rate from 100\% to almost 0\%, a 100-fold improvement over the baseline methods. Our code is available at \url{https://github.com/judydnguyen/pbp-backdoor-purification-official}.
Verification of Behavior Trees with Contingency Monitors
Nov 21, 2024

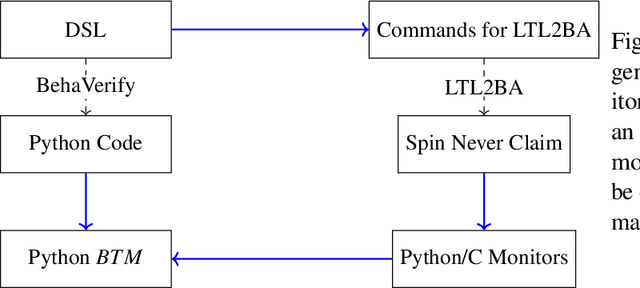

Behavior Trees (BTs) are high level controllers that have found use in a wide range of robotics tasks. As they grow in popularity and usage, it is crucial to ensure that the appropriate tools and methods are available for ensuring they work as intended. To that end, we created a new methodology by which to create Runtime Monitors for BTs. These monitors can be used by the BT to correct when undesirable behavior is detected and are capable of handling LTL specifications. We demonstrate that in terms of runtime, the generated monitors are on par with monitors generated by existing tools and highlight certain features that make our method more desirable in various situations. We note that our method allows for our monitors to be swapped out with alternate monitors with fairly minimal user effort. Finally, our method ties in with our existing tool, BehaVerify, allowing for the verification of BTs with monitors.
* In Proceedings FMAS2024, arXiv:2411.13215
Formalizing Stateful Behavior Trees
Nov 21, 2024
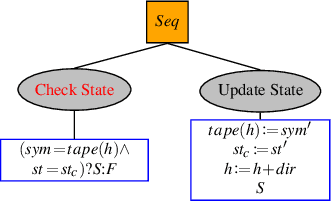


Behavior Trees (BTs) are high-level controllers that are useful in a variety of planning tasks and are gaining traction in robotic mission planning. As they gain popularity in safety-critical domains, it is important to formalize their syntax and semantics, as well as verify properties for them. In this paper, we formalize a class of BTs we call Stateful Behavior Trees (SBTs) that have auxiliary variables and operate in an environment that can change over time. SBTs have access to persistent shared memory (often known as a blackboard) that keeps track of these auxiliary variables. We demonstrate that SBTs are equivalent in computational power to Turing Machines when the blackboard can store mathematical (i.e., unbounded) integers. We further identify syntactic assumptions where SBTs have computational power equivalent to finite state automata, specifically where the auxiliary variables are of finitary types. We present a domain specific language (DSL) for writing SBTs and adapt the tool BehaVerify for use with this DSL. This new DSL in BehaVerify supports interfacing with popular BT libraries in Python, and also provides generation of Haskell code and nuXmv models, the latter of which is used for model checking temporal logic specifications for the SBTs. We include examples and scalability results where BehaVerify outperforms another verification tool by a factor of 100.
* In Proceedings FMAS2024, arXiv:2411.13215
Formal Logic-guided Robust Federated Learning against Poisoning Attacks
Nov 05, 2024



Federated Learning (FL) offers a promising solution to the privacy concerns associated with centralized Machine Learning (ML) by enabling decentralized, collaborative learning. However, FL is vulnerable to various security threats, including poisoning attacks, where adversarial clients manipulate the training data or model updates to degrade overall model performance. Recognizing this threat, researchers have focused on developing defense mechanisms to counteract poisoning attacks in FL systems. However, existing robust FL methods predominantly focus on computer vision tasks, leaving a gap in addressing the unique challenges of FL with time series data. In this paper, we present FLORAL, a defense mechanism designed to mitigate poisoning attacks in federated learning for time-series tasks, even in scenarios with heterogeneous client data and a large number of adversarial participants. Unlike traditional model-centric defenses, FLORAL leverages logical reasoning to evaluate client trustworthiness by aligning their predictions with global time-series patterns, rather than relying solely on the similarity of client updates. Our approach extracts logical reasoning properties from clients, then hierarchically infers global properties, and uses these to verify client updates. Through formal logic verification, we assess the robustness of each client contribution, identifying deviations indicative of adversarial behavior. Experimental results on two datasets demonstrate the superior performance of our approach compared to existing baseline methods, highlighting its potential to enhance the robustness of FL to time series applications. Notably, FLORAL reduced the prediction error by 93.27\% in the best-case scenario compared to the second-best baseline. Our code is available at \url{https://anonymous.4open.science/r/FLORAL-Robust-FTS}.
FISC: Federated Domain Generalization via Interpolative Style Transfer and Contrastive Learning
Oct 30, 2024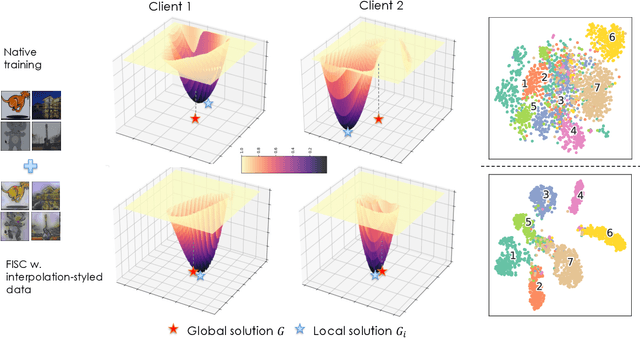
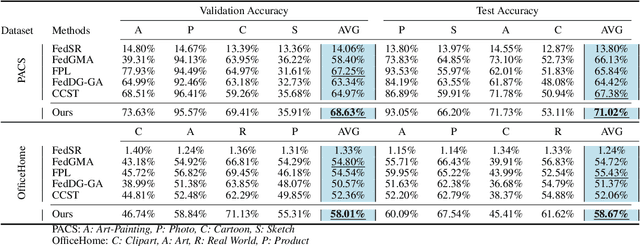
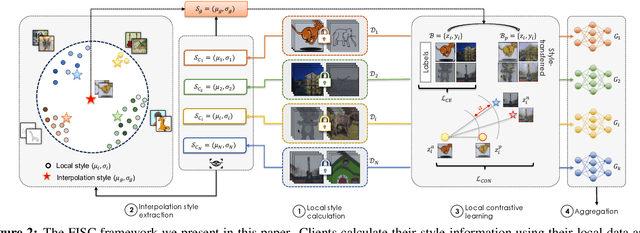
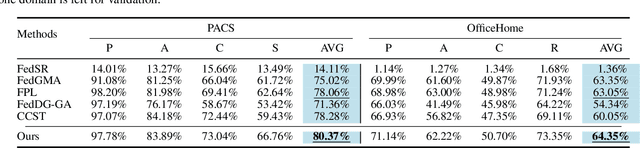
Federated Learning (FL) shows promise in preserving privacy and enabling collaborative learning. However, most current solutions focus on private data collected from a single domain. A significant challenge arises when client data comes from diverse domains (i.e., domain shift), leading to poor performance on unseen domains. Existing Federated Domain Generalization approaches address this problem but assume each client holds data for an entire domain, limiting their practicality in real-world scenarios with domain-based heterogeneity and client sampling. To overcome this, we introduce FISC, a novel FL domain generalization paradigm that handles more complex domain distributions across clients. FISC enables learning across domains by extracting an interpolative style from local styles and employing contrastive learning. This strategy gives clients multi-domain representations and unbiased convergent targets. Empirical results on multiple datasets, including PACS, Office-Home, and IWildCam, show FISC outperforms state-of-the-art (SOTA) methods. Our method achieves accuracy improvements ranging from 3.64% to 57.22% on unseen domains. Our code is available at https://anonymous.4open.science/r/FISC-AAAI-16107.