 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeLayer: Integrating Human Attention Patterns into LLM-Based Code Summarization
Feb 25, 2026Code summarization is the task of generating natural language descriptions of source code, which is critical for software comprehension and maintenance. While large language models (LLMs) have achieved remarkable progress on this task, an open question remains: can human expertise in code understanding further guide and enhance these models? We propose EyeLayer, a lightweight attention-augmentation module that incorporates human eye-gaze patterns, as a proxy of human expertise, into LLM-based code summarization. EyeLayer models human attention during code reading via a Multimodal Gaussian Mixture, redistributing token embeddings based on learned parameters (μ_i, σ_i^2) that capture where and how intensively developers focus. This design enables learning generalizable attention priors from eye-tracking data and incorporating them into LLMs seamlessly, without disturbing existing representations. We evaluate EyeLayer across diverse model families (i.e., LLaMA-3.2, Qwen3, and CodeBERT) covering different scales and architectures. EyeLayer consistently outperforms strong fine-tuning baselines across standard metrics, achieving gains of up to 13.17% on BLEU-4. These results demonstrate that human gaze patterns encode complementary attention signals that enhance the semantic focus of LLMs and transfer effectively across diverse models for code summarization.
Enhancing Code LLM Training with Programmer Attention
Mar 19, 2025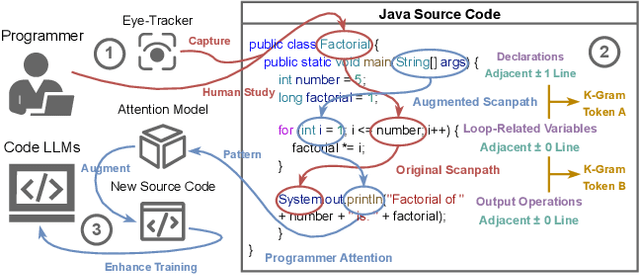
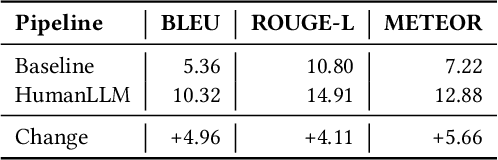
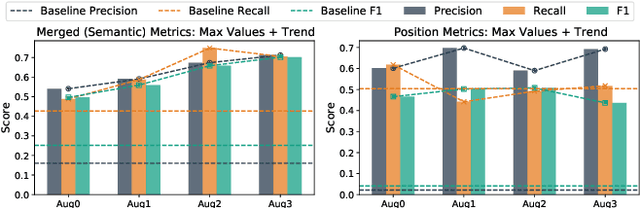
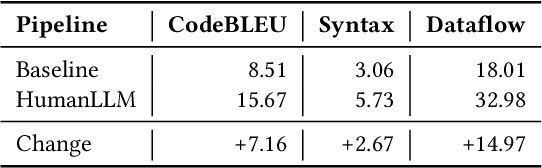
Human attention provides valuable yet underexploited signals for code LLM training, offering a perspective beyond purely machine-driven attention. Despite the complexity and cost of collecting eye-tracking data, there has also been limited progress in systematically using these signals for code LLM training. To address both issues, we propose a cohesive pipeline spanning augmentation and reward-based fine-tuning. Specifically, we introduce (1) an eye-tracking path augmentation method to expand programmer attention datasets, (2) a pattern abstraction step that refines raw fixations into learnable attention motifs, and (3) a reward-guided strategy for integrating these insights directly into a CodeT5 supervised fine-tuning process. Our experiments yield +7.16 in CodeBLEU on the CodeXGlue benchmark for code summarization, underscoring how uniting human and machine attention can boost code intelligence. We hope this work encourages broader exploration of human-centric methods in next-generation AI4SE.
Optimizing Code Runtime Performance through Context-Aware Retrieval-Augmented Generation
Jan 29, 2025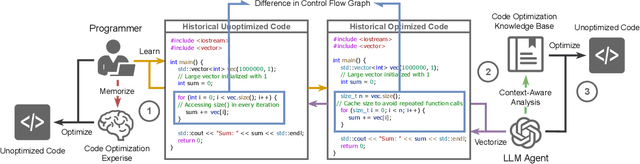
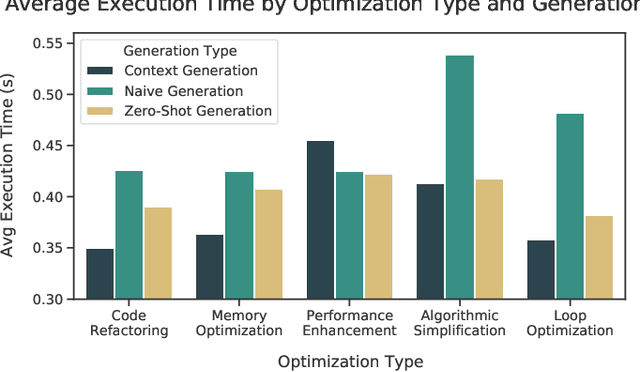

Optimizing software performance through automated code refinement offers a promising avenue for enhancing execution speed and efficiency. Despite recent advancements in LLMs, a significant gap remains in their ability to perform in-depth program analysis. This study introduces AUTOPATCH, an in-context learning approach designed to bridge this gap by enabling LLMs to automatically generate optimized code. Inspired by how programmers learn and apply knowledge to optimize software, AUTOPATCH incorporates three key components: (1) an analogy-driven framework to align LLM optimization with human cognitive processes, (2) a unified approach that integrates historical code examples and CFG analysis for context-aware learning, and (3) an automated pipeline for generating optimized code through in-context prompting. Experimental results demonstrate that AUTOPATCH achieves a 7.3% improvement in execution efficiency over GPT-4o across common generated executable code, highlighting its potential to advance automated program runtime optimization.
Label Errors in the Tobacco3482 Dataset
Dec 17, 2024



Tobacco3482 is a widely used document classification benchmark dataset. However, our manual inspection of the entire dataset uncovers widespread ontological issues, especially large amounts of annotation label problems in the dataset. We establish data label guidelines and find that 11.7% of the dataset is improperly annotated and should either have an unknown label or a corrected label, and 16.7% of samples in the dataset have multiple valid labels. We then analyze the mistakes of a top-performing model and find that 35% of the model's mistakes can be directly attributed to these label issues, highlighting the inherent problems with using a noisily labeled dataset as a benchmark. Supplementary material, including dataset annotations and code, is available at https://github.com/gordon-lim/tobacco3482-mistakes/.
PBP: Post-training Backdoor Purification for Malware Classifiers
Dec 05, 2024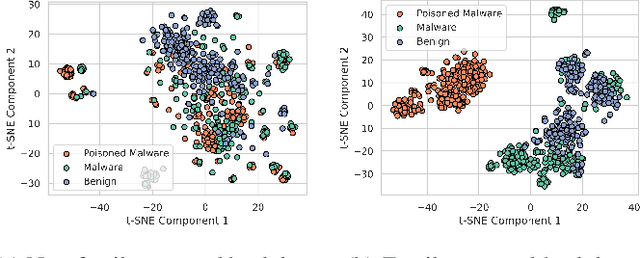
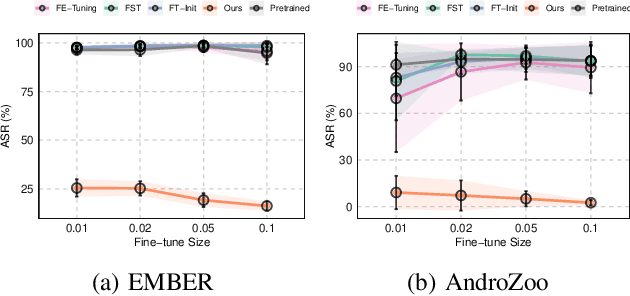
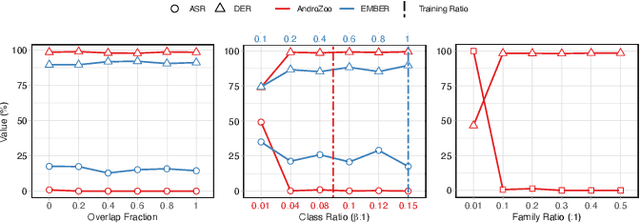
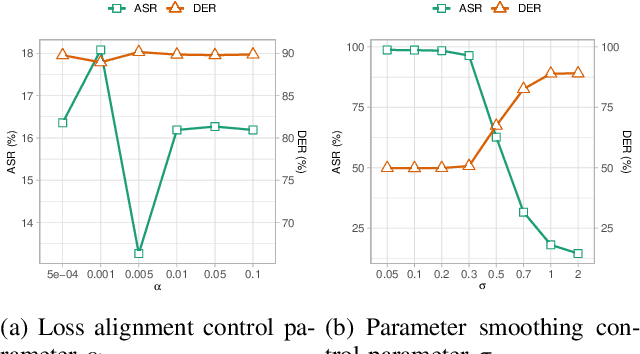
In recent years, the rise of machine learning (ML) in cybersecurity has brought new challenges, including the increasing threat of backdoor poisoning attacks on ML malware classifiers. For instance, adversaries could inject malicious samples into public malware repositories, contaminating the training data and potentially misclassifying malware by the ML model. Current countermeasures predominantly focus on detecting poisoned samples by leveraging disagreements within the outputs of a diverse set of ensemble models on training data points. However, these methods are not suitable for scenarios where Machine Learning-as-a-Service (MLaaS) is used or when users aim to remove backdoors from a model after it has been trained. Addressing this scenario, we introduce PBP, a post-training defense for malware classifiers that mitigates various types of backdoor embeddings without assuming any specific backdoor embedding mechanism. Our method exploits the influence of backdoor attacks on the activation distribution of neural networks, independent of the trigger-embedding method. In the presence of a backdoor attack, the activation distribution of each layer is distorted into a mixture of distributions. By regulating the statistics of the batch normalization layers, we can guide a backdoored model to perform similarly to a clean one. Our method demonstrates substantial advantages over several state-of-the-art methods, as evidenced by experiments on two datasets, two types of backdoor methods, and various attack configurations. Notably, our approach requires only a small portion of the training data -- only 1\% -- to purify the backdoor and reduce the attack success rate from 100\% to almost 0\%, a 100-fold improvement over the baseline methods. Our code is available at \url{https://github.com/judydnguyen/pbp-backdoor-purification-official}.
Robust Testing for Deep Learning using Human Label Noise
Nov 29, 2024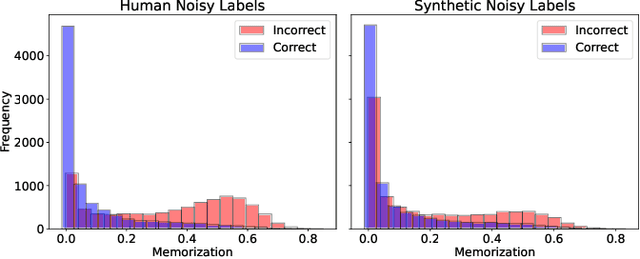
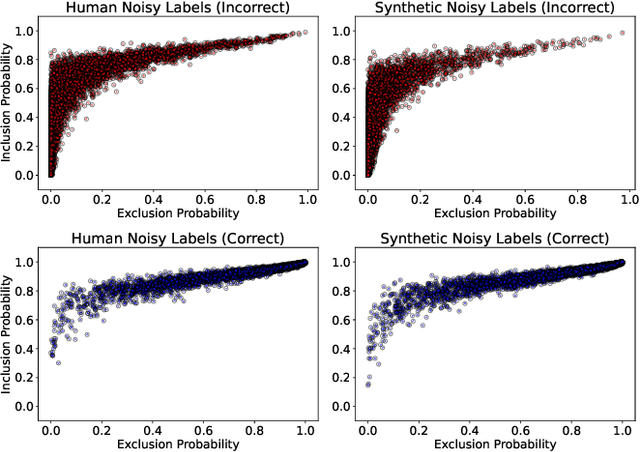
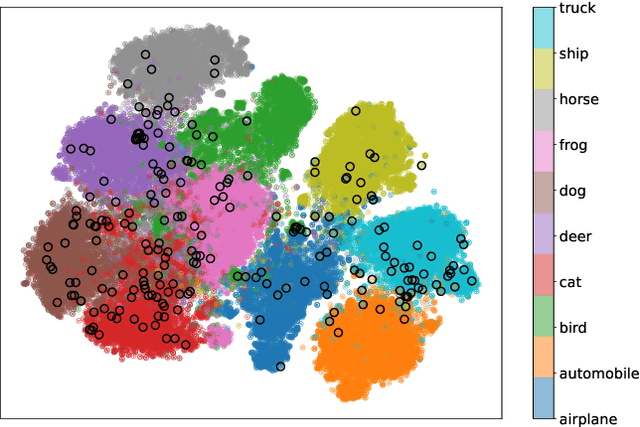

In deep learning (DL) systems, label noise in training datasets often degrades model performance, as models may learn incorrect patterns from mislabeled data. The area of Learning with Noisy Labels (LNL) has introduced methods to effectively train DL models in the presence of noisily-labeled datasets. Traditionally, these methods are tested using synthetic label noise, where ground truth labels are randomly (and automatically) flipped. However, recent findings highlight that models perform substantially worse under human label noise than synthetic label noise, indicating a need for more realistic test scenarios that reflect noise introduced due to imperfect human labeling. This underscores the need for generating realistic noisy labels that simulate human label noise, enabling rigorous testing of deep neural networks without the need to collect new human-labeled datasets. To address this gap, we present Cluster-Based Noise (CBN), a method for generating feature-dependent noise that simulates human-like label noise. Using insights from our case study of label memorization in the CIFAR-10N dataset, we design CBN to create more realistic tests for evaluating LNL methods. Our experiments demonstrate that current LNL methods perform worse when tested using CBN, highlighting its use as a rigorous approach to testing neural networks. Next, we propose Soft Neighbor Label Sampling (SNLS), a method designed to handle CBN, demonstrating its improvement over existing techniques in tackling this more challenging type of noise.
Formal Logic-guided Robust Federated Learning against Poisoning Attacks
Nov 05, 2024



Federated Learning (FL) offers a promising solution to the privacy concerns associated with centralized Machine Learning (ML) by enabling decentralized, collaborative learning. However, FL is vulnerable to various security threats, including poisoning attacks, where adversarial clients manipulate the training data or model updates to degrade overall model performance. Recognizing this threat, researchers have focused on developing defense mechanisms to counteract poisoning attacks in FL systems. However, existing robust FL methods predominantly focus on computer vision tasks, leaving a gap in addressing the unique challenges of FL with time series data. In this paper, we present FLORAL, a defense mechanism designed to mitigate poisoning attacks in federated learning for time-series tasks, even in scenarios with heterogeneous client data and a large number of adversarial participants. Unlike traditional model-centric defenses, FLORAL leverages logical reasoning to evaluate client trustworthiness by aligning their predictions with global time-series patterns, rather than relying solely on the similarity of client updates. Our approach extracts logical reasoning properties from clients, then hierarchically infers global properties, and uses these to verify client updates. Through formal logic verification, we assess the robustness of each client contribution, identifying deviations indicative of adversarial behavior. Experimental results on two datasets demonstrate the superior performance of our approach compared to existing baseline methods, highlighting its potential to enhance the robustness of FL to time series applications. Notably, FLORAL reduced the prediction error by 93.27\% in the best-case scenario compared to the second-best baseline. Our code is available at \url{https://anonymous.4open.science/r/FLORAL-Robust-FTS}.
FISC: Federated Domain Generalization via Interpolative Style Transfer and Contrastive Learning
Oct 30, 2024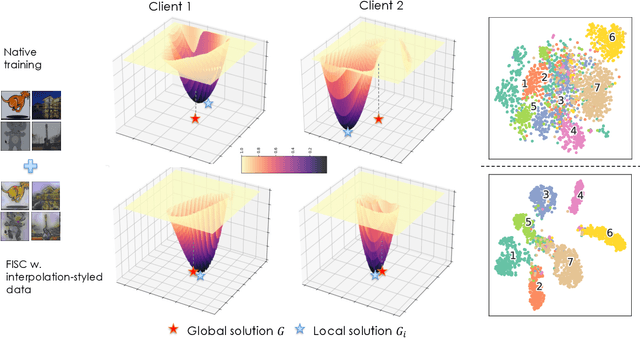
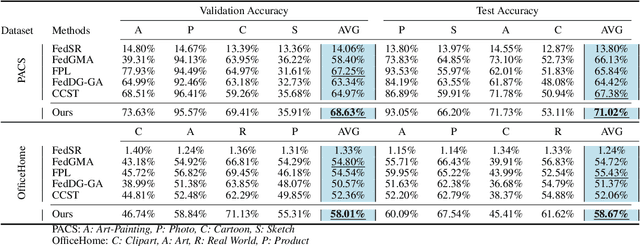
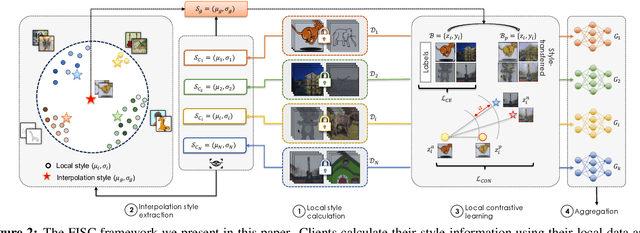
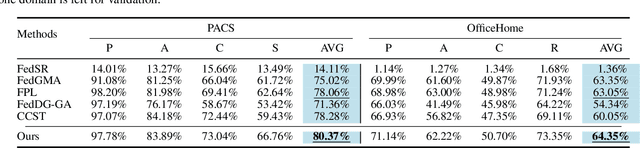
Federated Learning (FL) shows promise in preserving privacy and enabling collaborative learning. However, most current solutions focus on private data collected from a single domain. A significant challenge arises when client data comes from diverse domains (i.e., domain shift), leading to poor performance on unseen domains. Existing Federated Domain Generalization approaches address this problem but assume each client holds data for an entire domain, limiting their practicality in real-world scenarios with domain-based heterogeneity and client sampling. To overcome this, we introduce FISC, a novel FL domain generalization paradigm that handles more complex domain distributions across clients. FISC enables learning across domains by extracting an interpolative style from local styles and employing contrastive learning. This strategy gives clients multi-domain representations and unbiased convergent targets. Empirical results on multiple datasets, including PACS, Office-Home, and IWildCam, show FISC outperforms state-of-the-art (SOTA) methods. Our method achieves accuracy improvements ranging from 3.64% to 57.22% on unseen domains. Our code is available at https://anonymous.4open.science/r/FISC-AAAI-16107.
Document Type Classification using File Names
Oct 02, 2024Rapid document classification is critical in several time-sensitive applications like digital forensics and large-scale media classification. Traditional approaches that rely on heavy-duty deep learning models fall short due to high inference times over vast input datasets and computational resources associated with analyzing whole documents. In this paper, we present a method using lightweight supervised learning models, combined with a TF-IDF feature extraction-based tokenization method, to accurately and efficiently classify documents based solely on file names that substantially reduces inference time. This approach can distinguish ambiguous file names from the indicative file names through confidence scores and through using a negative class representing ambiguous file names. Our results indicate that file name classifiers can process more than 80% of the in-scope data with 96.7% accuracy when tested on a dataset with a large portion of out-of-scope data with respect to the training dataset while being 442.43x faster than more complex models such as DiT. Our method offers a crucial solution for efficiently processing vast datasets in critical scenarios, enabling fast, more reliable document classification.
Generating Hard-Negative Out-of-Scope Data with ChatGPT for Intent Classification
Mar 08, 2024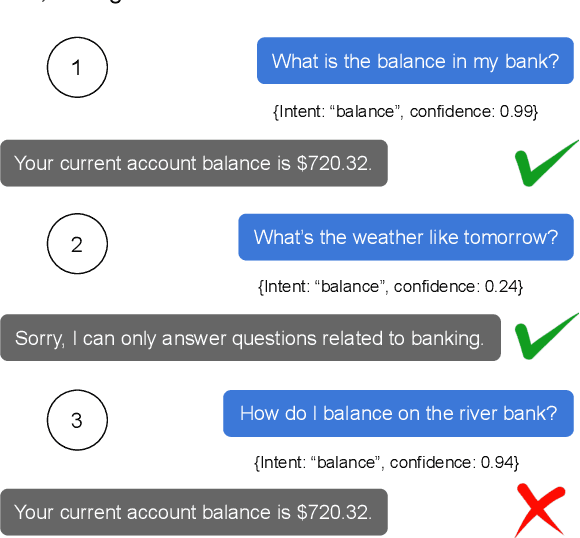
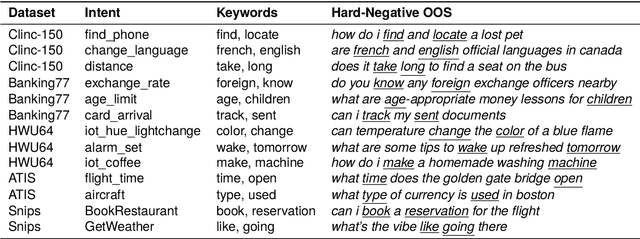
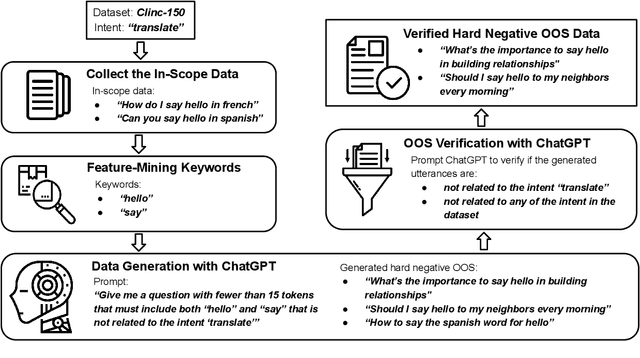
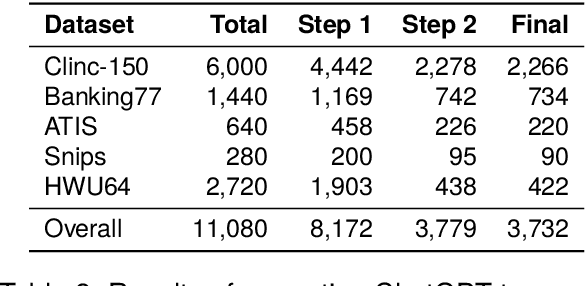
Intent classifiers must be able to distinguish when a user's utterance does not belong to any supported intent to avoid producing incorrect and unrelated system responses. Although out-of-scope (OOS) detection for intent classifiers has been studied, previous work has not yet studied changes in classifier performance against hard-negative out-of-scope utterances (i.e., inputs that share common features with in-scope data, but are actually out-of-scope). We present an automated technique to generate hard-negative OOS data using ChatGPT. We use our technique to build five new hard-negative OOS datasets, and evaluate each against three benchmark intent classifiers. We show that classifiers struggle to correctly identify hard-negative OOS utterances more than general OOS utterances. Finally, we show that incorporating hard-negative OOS data for training improves model robustness when detecting hard-negative OOS data and general OOS data. Our technique, datasets, and evaluation address an important void in the field, offering a straightforward and inexpensive way to collect hard-negative OOS data and improve intent classifiers' robustness.