 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
May 21, 2025AI agents have the potential to significantly alter the cybersecurity landscape. To help us understand this change, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a specific vulnerability), and Patch (patching a specific vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \$10 to \$30,485, and cover 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a specific vulnerability. We evaluate 5 agents: Claude Code, OpenAI Codex CLI, and custom agents with GPT-4.1, Gemini 2.5 Pro Preview, and Claude 3.7 Sonnet Thinking. Given up to three attempts, the top-performing agents are Claude Code (5% on Detect, mapping to \$1,350), Custom Agent with Claude 3.7 Sonnet Thinking (5% on Detect, mapping to \$1,025; 67.5% on Exploit), and OpenAI Codex CLI (5% on Detect, mapping to \$2,400; 90% on Patch, mapping to \$14,422). OpenAI Codex CLI and Claude Code are more capable at defense, achieving higher Patch scores of 90% and 87.5%, compared to Exploit scores of 32.5% and 57.5% respectively; in contrast, the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 40-67.5% and Patch scores of 45-60%.
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024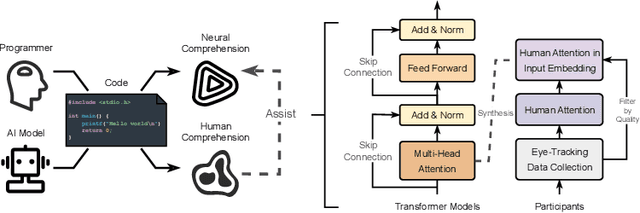
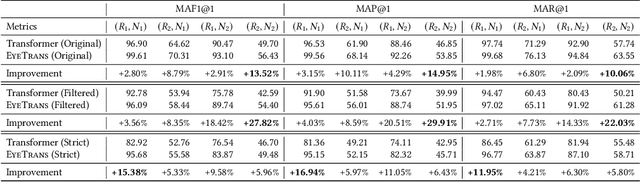
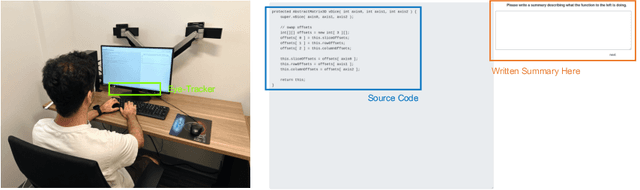
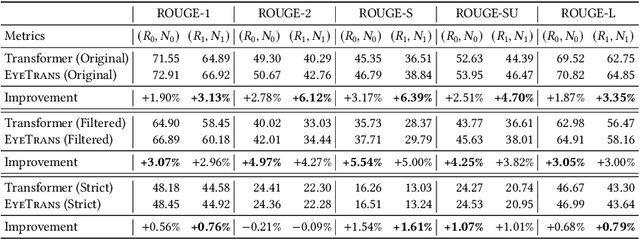
Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization
Feb 22, 2024Recent language models have demonstrated proficiency in summarizing source code. However, as in many other domains of machine learning, language models of code lack sufficient explainability. Informally, we lack a formulaic or intuitive understanding of what and how models learn from code. Explainability of language models can be partially provided if, as the models learn to produce higher-quality code summaries, they also align in deeming the same code parts important as those identified by human programmers. In this paper, we report negative results from our investigation of explainability of language models in code summarization through the lens of human comprehension. We measure human focus on code using eye-tracking metrics such as fixation counts and duration in code summarization tasks. To approximate language model focus, we employ a state-of-the-art model-agnostic, black-box, perturbation-based approach, SHAP (SHapley Additive exPlanations), to identify which code tokens influence that generation of summaries. Using these settings, we find no statistically significant relationship between language models' focus and human programmers' attention. Furthermore, alignment between model and human foci in this setting does not seem to dictate the quality of the LLM-generated summaries. Our study highlights an inability to align human focus with SHAP-based model focus measures. This result calls for future investigation of multiple open questions for explainable language models for code summarization and software engineering tasks in general, including the training mechanisms of language models for code, whether there is an alignment between human and model attention on code, whether human attention can improve the development of language models, and what other model focus measures are appropriate for improving explainability.
Continuous Temporal Graph Networks for Event-Based Graph Data
May 31, 2022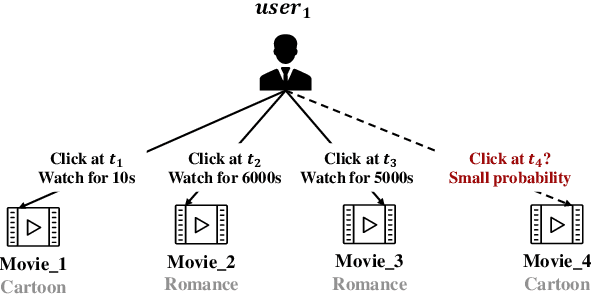
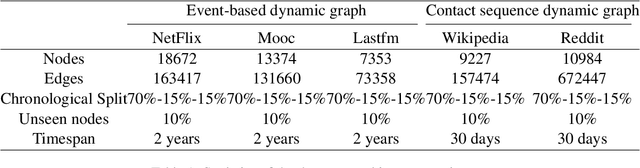
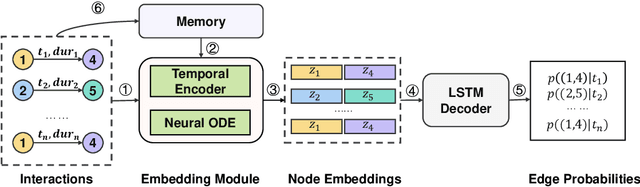
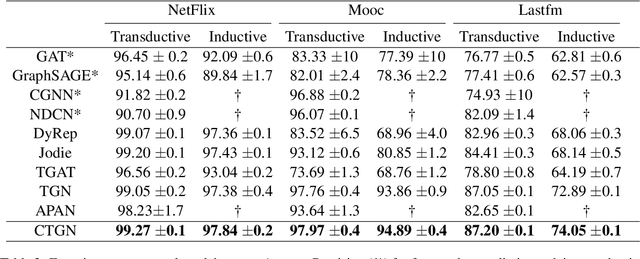
There has been an increasing interest in modeling continuous-time dynamics of temporal graph data. Previous methods encode time-evolving relational information into a low-dimensional representation by specifying discrete layers of neural networks, while real-world dynamic graphs often vary continuously over time. Hence, we propose Continuous Temporal Graph Networks (CTGNs) to capture the continuous dynamics of temporal graph data. We use both the link starting timestamps and link duration as evolving information to model the continuous dynamics of nodes. The key idea is to use neural ordinary differential equations (ODE) to characterize the continuous dynamics of node representations over dynamic graphs. We parameterize ordinary differential equations using a novel graph neural network. The existing dynamic graph networks can be considered as a specific discretization of CTGNs. Experiment results on both transductive and inductive tasks demonstrate the effectiveness of our proposed approach over competitive baselines.