 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Coding Agents Fail Their Users: A Large-Scale Analysis of Developer-Agent Misalignment in 20,574 Real-World Sessions
May 28, 2026AI coding agents increasingly act directly within software environments, yet existing analyses of their failures rely on benchmark trajectories that miss how developers actually experience misalignment. We present an observational study of 20,574 coding-agent sessions from 1,639 repositories across IDE and CLI workflows. We operationalize misalignment as a breakdown made visible through developer pushback, and annotate each episode along four axes: form, cause, cost, and resolution. We identify seven recurring forms, spanning how agents read projects, interpret developer intent, follow rules, bound their actions, implement and execute code, and report progress. 90.50\% of episodes impose effort and trust costs rather than irreversible system damage, yet 91.49\% of visible resolutions still require explicit user correction. Misalignment patterns also differ across IDE and CLI settings, persist across adjacent sessions, and shift over time: while overall rates decline, constraint violations and inaccurate self-reporting grow in share. Our findings inform the design of training, evaluation, and interfaces for keeping coding agents aligned with real developer workflows.
AI-Mediated Code Comment Improvement
May 13, 2025This paper describes an approach to improve code comments along different quality axes by rewriting those comments with customized Artificial Intelligence (AI)-based tools. We conduct an empirical study followed by grounded theory qualitative analysis to determine the quality axes to improve. Then we propose a procedure using a Large Language Model (LLM) to rewrite existing code comments along the quality axes. We implement our procedure using GPT-4o, then distil the results into a smaller model capable of being run in-house, so users can maintain data custody. We evaluate both our approach using GPT-4o and the distilled model versions. We show in an evaluation how our procedure improves code comments along the quality axes. We release all data and source code in an online repository for reproducibility.
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024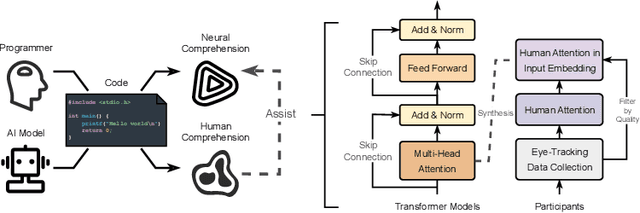
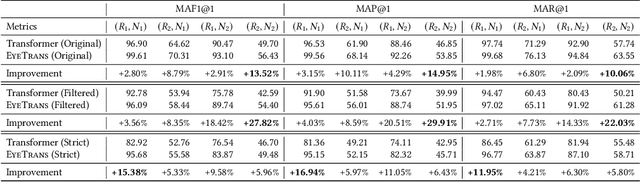
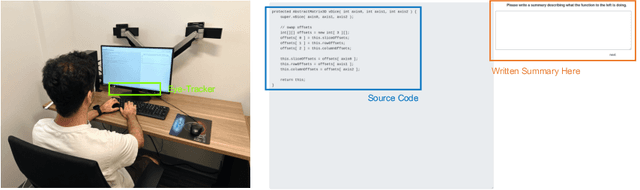
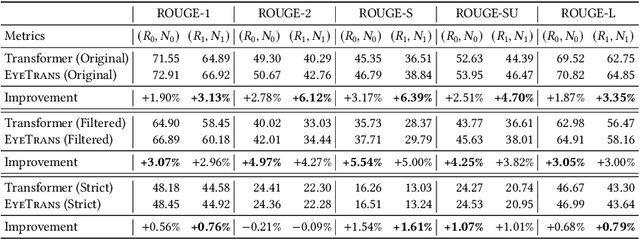
Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization
Feb 22, 2024Recent language models have demonstrated proficiency in summarizing source code. However, as in many other domains of machine learning, language models of code lack sufficient explainability. Informally, we lack a formulaic or intuitive understanding of what and how models learn from code. Explainability of language models can be partially provided if, as the models learn to produce higher-quality code summaries, they also align in deeming the same code parts important as those identified by human programmers. In this paper, we report negative results from our investigation of explainability of language models in code summarization through the lens of human comprehension. We measure human focus on code using eye-tracking metrics such as fixation counts and duration in code summarization tasks. To approximate language model focus, we employ a state-of-the-art model-agnostic, black-box, perturbation-based approach, SHAP (SHapley Additive exPlanations), to identify which code tokens influence that generation of summaries. Using these settings, we find no statistically significant relationship between language models' focus and human programmers' attention. Furthermore, alignment between model and human foci in this setting does not seem to dictate the quality of the LLM-generated summaries. Our study highlights an inability to align human focus with SHAP-based model focus measures. This result calls for future investigation of multiple open questions for explainable language models for code summarization and software engineering tasks in general, including the training mechanisms of language models for code, whether there is an alignment between human and model attention on code, whether human attention can improve the development of language models, and what other model focus measures are appropriate for improving explainability.
Revisiting File Context for Source Code Summarization
Sep 05, 2023Source code summarization is the task of writing natural language descriptions of source code. A typical use case is generating short summaries of subroutines for use in API documentation. The heart of almost all current research into code summarization is the encoder-decoder neural architecture, and the encoder input is almost always a single subroutine or other short code snippet. The problem with this setup is that the information needed to describe the code is often not present in the code itself -- that information often resides in other nearby code. In this paper, we revisit the idea of ``file context'' for code summarization. File context is the idea of encoding select information from other subroutines in the same file. We propose a novel modification of the Transformer architecture that is purpose-built to encode file context and demonstrate its improvement over several baselines. We find that file context helps on a subset of challenging examples where traditional approaches struggle.
Distilled GPT for Source Code Summarization
Aug 28, 2023A code summary is a brief natural language description of source code. Summaries are usually only a single sentence long, and yet form the backbone of developer documentation. A short descriptions such as "changes all visible polygons to the color blue" can give a programmer a high-level idea of what code does without the effort of reading the code itself. Recently, products based on Large Language Models such as ChatGPT have demonstrated a strong ability to write these descriptions automatically. However, to use these tools, programmers must send their code to untrusted third parties for processing (e.g., via an API call). This loss of custody is not acceptable to many organizations. In this paper, we present an alternative: we train an open source model using sample output generated by GPT-3.5 in a process related to knowledge distillation. Our model is small enough (350m parameters) to be run on a single 16gb GPU, yet we show in our evaluation that it is large enough to mimic GPT-3.5 on this task.
Semantic Similarity Loss for Neural Source Code Summarization
Aug 14, 2023This paper presents an improved loss function for neural source code summarization. Code summarization is the task of writing natural language descriptions of source code. Neural code summarization refers to automated techniques for generating these descriptions using neural networks. Almost all current approaches involve neural networks as either standalone models or as part of a pretrained large language models e.g., GPT, Codex, LLaMA. Yet almost all also use a categorical cross-entropy (CCE) loss function for network optimization. Two problems with CCE are that 1) it computes loss over each word prediction one-at-a-time, rather than evaluating a whole sentence, and 2) it requires a perfect prediction, leaving no room for partial credit for synonyms. We propose and evaluate a loss function to alleviate this problem. In essence, we propose to use a semantic similarity metric to calculate loss over the whole output sentence prediction per training batch, rather than just loss for each word. We also propose to combine our loss with traditional CCE for each word, which streamlines the training process compared to baselines. We evaluate our approach over several baselines and report an improvement in the vast majority of conditions.
Statement-based Memory for Neural Source Code Summarization
Jul 21, 2023Source code summarization is the task of writing natural language descriptions of source code behavior. Code summarization underpins software documentation for programmers. Short descriptions of code help programmers understand the program quickly without having to read the code itself. Lately, neural source code summarization has emerged as the frontier of research into automated code summarization techniques. By far the most popular targets for summarization are program subroutines. The idea, in a nutshell, is to train an encoder-decoder neural architecture using large sets of examples of subroutines extracted from code repositories. The encoder represents the code and the decoder represents the summary. However, most current approaches attempt to treat the subroutine as a single unit. For example, by taking the entire subroutine as input to a Transformer or RNN-based encoder. But code behavior tends to depend on the flow from statement to statement. Normally dynamic analysis may shed light on this flow, but dynamic analysis on hundreds of thousands of examples in large datasets is not practical. In this paper, we present a statement-based memory encoder that learns the important elements of flow during training, leading to a statement-based subroutine representation without the need for dynamic analysis. We implement our encoder for code summarization and demonstrate a significant improvement over the state-of-the-art.
Towards Modeling Human Attention from Eye Movements for Neural Source Code Summarization
May 16, 2023Neural source code summarization is the task of generating natural language descriptions of source code behavior using neural networks. A fundamental component of most neural models is an attention mechanism. The attention mechanism learns to connect features in source code to specific words to use when generating natural language descriptions. Humans also pay attention to some features in code more than others. This human attention reflects experience and high-level cognition well beyond the capability of any current neural model. In this paper, we use data from published eye-tracking experiments to create a model of this human attention. The model predicts which words in source code are the most important for code summarization. Next, we augment a baseline neural code summarization approach using our model of human attention. We observe an improvement in prediction performance of the augmented approach in line with other bio-inspired neural models.
A Language Model of Java Methods with Train/Test Deduplication
May 15, 2023This tool demonstration presents a research toolkit for a language model of Java source code. The target audience includes researchers studying problems at the granularity level of subroutines, statements, or variables in Java. In contrast to many existing language models, we prioritize features for researchers including an open and easily-searchable training set, a held out test set with different levels of deduplication from the training set, infrastructure for deduplicating new examples, and an implementation platform suitable for execution on equipment accessible to a relatively modest budget. Our model is a GPT2-like architecture with 350m parameters. Our training set includes 52m Java methods (9b tokens) and 13m StackOverflow threads (10.5b tokens). To improve accessibility of research to more members of the community, we limit local resource requirements to GPUs with 16GB video memory. We provide a test set of held out Java methods that include descriptive comments, including the entire Java projects for those methods. We also provide deduplication tools using precomputed hash tables at various similarity thresholds to help researchers ensure that their own test examples are not in the training set. We make all our tools and data open source and available via Huggingface and Github.