 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Clarifying Questions for Query Refinement in Source Code Search
Jan 24, 2022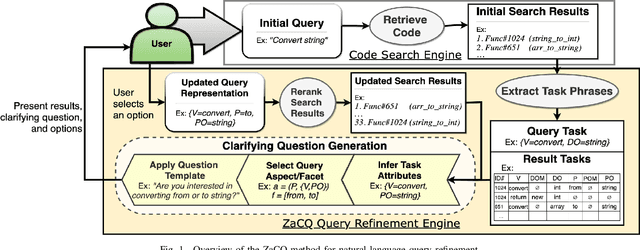
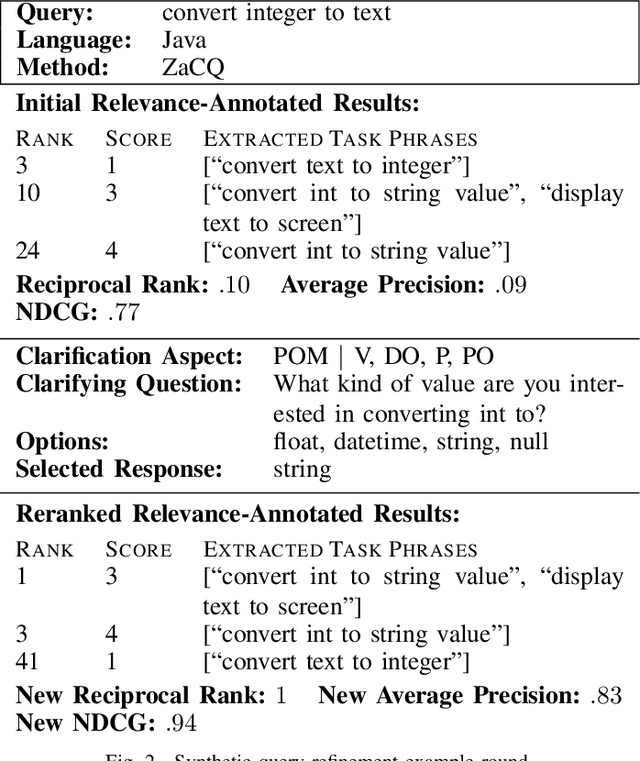
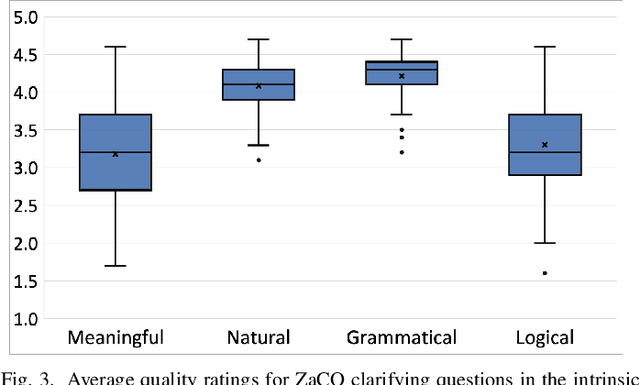
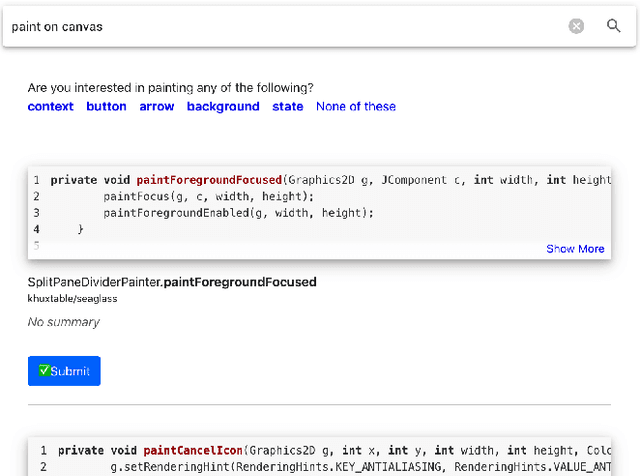
In source code search, a common information-seeking strategy involves providing a short initial query with a broad meaning, and then iteratively refining the query using terms gleaned from the results of subsequent searches. This strategy requires programmers to spend time reading search results that are irrelevant to their development needs. In contrast, when programmers seek information from other humans, they typically refine queries by asking and answering clarifying questions. Clarifying questions have been shown to benefit general-purpose search engines, but have not been examined in the context of code search. We present a method for generating natural-sounding clarifying questions using information extracted from function names and comments. Our method outperformed a keyword-based method for single-turn refinement in synthetic studies, and was associated with shorter search duration in human studies.
A Neural Question Answering System for Basic Questions about Subroutines
Jan 11, 2021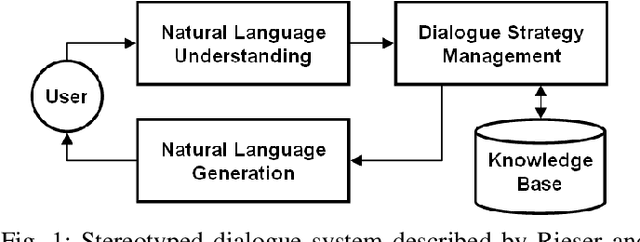
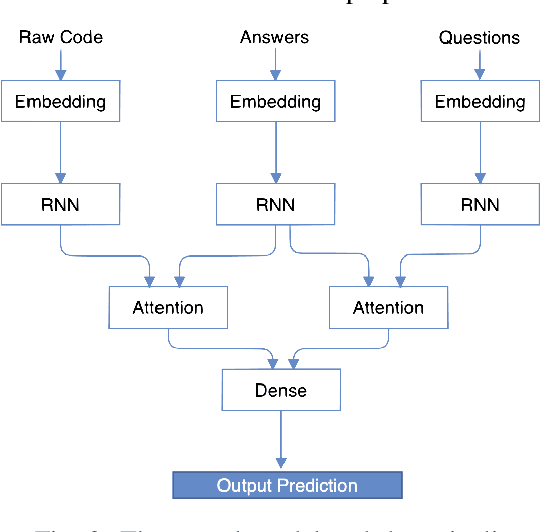
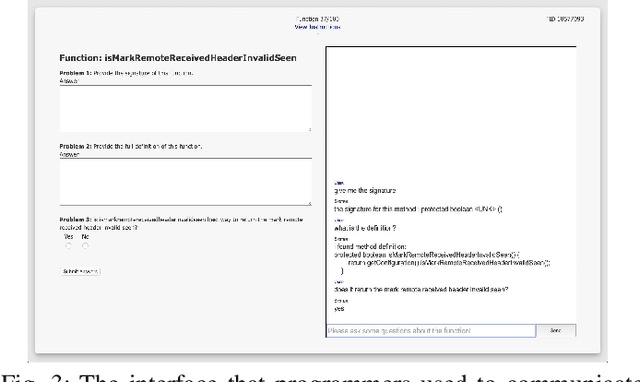
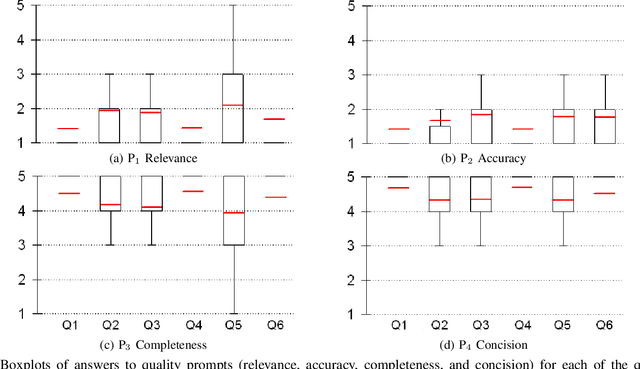
A question answering (QA) system is a type of conversational AI that generates natural language answers to questions posed by human users. QA systems often form the backbone of interactive dialogue systems, and have been studied extensively for a wide variety of tasks ranging from restaurant recommendations to medical diagnostics. Dramatic progress has been made in recent years, especially from the use of encoder-decoder neural architectures trained with big data input. In this paper, we take initial steps to bringing state-of-the-art neural QA technologies to Software Engineering applications by designing a context-based QA system for basic questions about subroutines. We curate a training dataset of 10.9 million question/context/answer tuples based on rules we extract from recent empirical studies. Then, we train a custom neural QA model with this dataset and evaluate the model in a study with professional programmers. We demonstrate the strengths and weaknesses of the system, and lay the groundwork for its use in eventual dialogue systems for software engineering.
Adapting Neural Text Classification for Improved Software Categorization
Jun 15, 2018

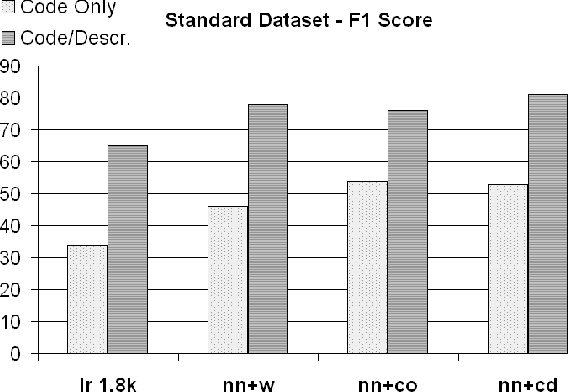
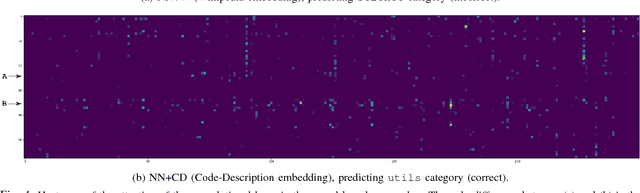
Software Categorization is the task of organizing software into groups that broadly describe the behavior of the software, such as "editors" or "science." Categorization plays an important role in several maintenance tasks, such as repository navigation and feature elicitation. Current approaches attempt to cast the problem as text classification, to make use of the rich body of literature from the NLP domain. However, as we will show in this paper, text classification algorithms are generally not applicable off-the-shelf to source code; we found that they work well when high-level project descriptions are available, but suffer very large performance penalties when classifying source code and comments only. We propose a set of adaptations to a state-of-the-art neural classification algorithm and perform two evaluations: one with reference data from Debian end-user programs, and one with a set of C/C++ libraries that we hired professional programmers to annotate. We show that our proposed approach achieves performance exceeding that of previous software classification techniques as well as a state-of-the-art neural text classification technique.