 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Code Summarization via a Graph Neural Network
Apr 07, 2020
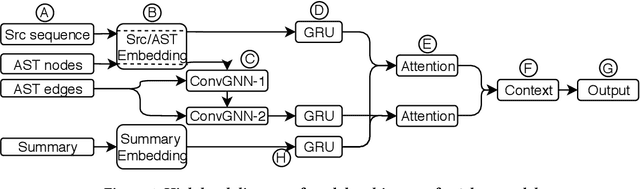
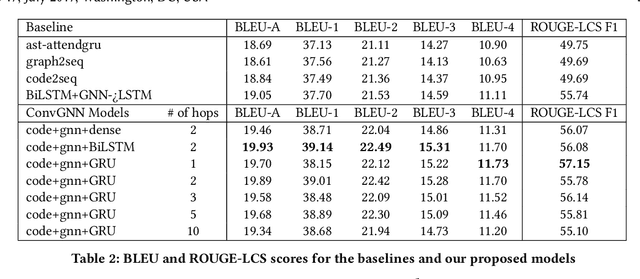
Automatic source code summarization is the task of generating natural language descriptions for source code. Automatic code summarization is a rapidly expanding research area, especially as the community has taken greater advantage of advances in neural network and AI technologies. In general, source code summarization techniques use the source code as input and outputs a natural language description. Yet a strong consensus is developing that using structural information as input leads to improved performance. The first approaches to use structural information flattened the AST into a sequence. Recently, more complex approaches based on random AST paths or graph neural networks have improved on the models using flattened ASTs. However, the literature still does not describe the using a graph neural network together with source code sequence as separate inputs to a model. Therefore, in this paper, we present an approach that uses a graph-based neural architecture that better matches the default structure of the AST to generate these summaries. We evaluate our technique using a data set of 2.1 million Java method-comment pairs and show improvement over four baseline techniques, two from the software engineering literature, and two from machine learning literature.
Recommendations for Datasets for Source Code Summarization
Apr 04, 2019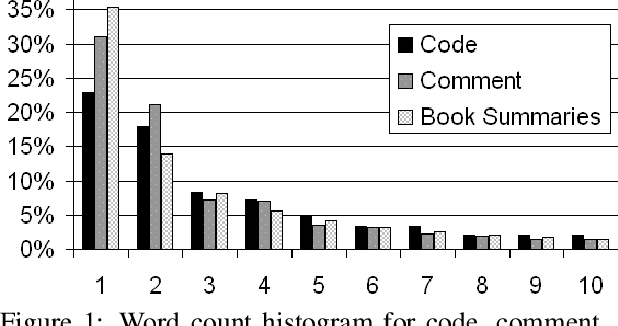
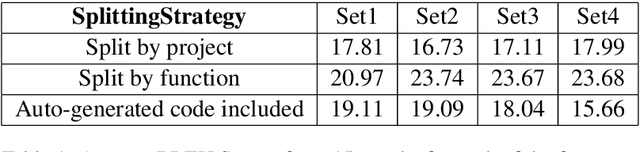


Source Code Summarization is the task of writing short, natural language descriptions of source code. The main use for these descriptions is in software documentation e.g. the one-sentence Java method descriptions in JavaDocs. Code summarization is rapidly becoming a popular research problem, but progress is restrained due to a lack of suitable datasets. In addition, a lack of community standards for creating datasets leads to confusing and unreproducible research results -- we observe swings in performance of more than 33% due only to changes in dataset design. In this paper, we make recommendations for these standards from experimental results. We release a dataset based on prior work of over 2.1m pairs of Java methods and one sentence method descriptions from over 28k Java projects. We describe the dataset and point out key differences from natural language data, to guide and support future researchers.
Adapting Neural Text Classification for Improved Software Categorization
Jun 15, 2018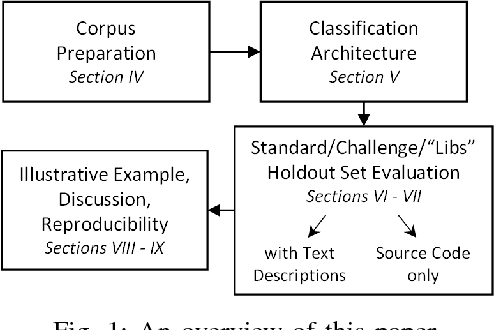

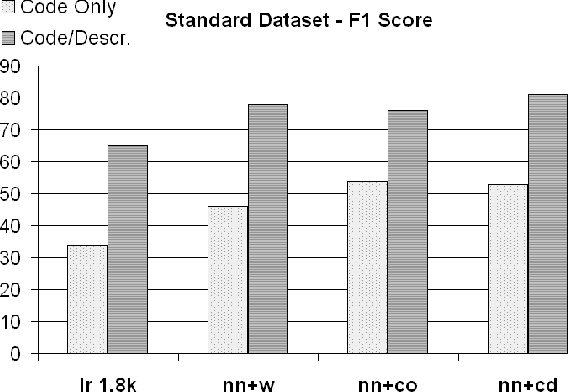
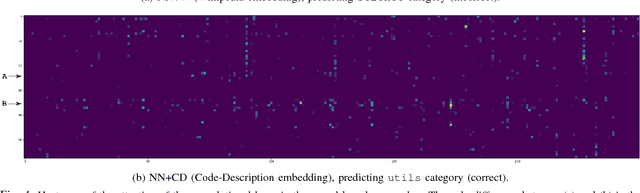
Software Categorization is the task of organizing software into groups that broadly describe the behavior of the software, such as "editors" or "science." Categorization plays an important role in several maintenance tasks, such as repository navigation and feature elicitation. Current approaches attempt to cast the problem as text classification, to make use of the rich body of literature from the NLP domain. However, as we will show in this paper, text classification algorithms are generally not applicable off-the-shelf to source code; we found that they work well when high-level project descriptions are available, but suffer very large performance penalties when classifying source code and comments only. We propose a set of adaptations to a state-of-the-art neural classification algorithm and perform two evaluations: one with reference data from Debian end-user programs, and one with a set of C/C++ libraries that we hired professional programmers to annotate. We show that our proposed approach achieves performance exceeding that of previous software classification techniques as well as a state-of-the-art neural text classification technique.