 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully 3D-Printed Wideband Metasurface Folded Reflectarray Antenna
Mar 18, 2026This article presents a fully 3D-printed wideband metasurface folded reflectarray antenna (MFRA) operating in the millimeter-wave n257 band. The proposed MFRA integrates a novel polarization-rotating reflective metasurface (RMS), a compact embedded horn feed, and a polarization-selective metasurface polarization grid (MPG), all fabricated using a low-cost in-house 3D-printed method. Unlike conventional PCB-based FRAs constrained to planar unit-cell geometries, the proposed anisotropic meta-element design exploits full three-dimensional dielectric control by tailoring varying unit-cell heights. This volumetric tuning, combined with the spatial distribution of the meta-elements, enables phase compensation exceeding $400^{\circ}$ across the aperture, supporting robust wideband performance. An MFRA prototype is in-house fabricated and experimentally validated. Measured results agree well with simulations, achieving a $-10$ dB impedance bandwidth of 20.7\% (26--32 GHz) and a peak realized gain of 31.1 dBi at 28.2 GHz. The antenna exhibits sidelobe levels below $-20$ dB, cross-polarization below $-30$ dB, and a compact height-to-diameter ratio of 0.20. Stable pencil beams with an average HPBW of $3.7^{\circ}$ are maintained across the operating band. To further validate the robustness of the proposed in-house designed MFRA, a commercially manufactured RMS was also obtained, whose measured performance shows excellent agreement with the in-house 3D-printed version, confirming a cost-effective rapid-prototyping antenna solution. The proposed MFRA is a cost-effective solution for beyond 5G and 6G high-gain point-to-point mmWave wireless applications, such as fixed wireless access, near field communication, and beam focusing.
Analysis of Frequency-Diverse and Dispersion Effects in Dynamic Metasurface Antenna for Holographic Sensing and Imaging
Oct 23, 2025Dynamic metasurface antennas (DMAs) represent a novel approach to programmable and affordable electromagnetic wave manipulation for enhanced wireless communications, sensing, and imaging applications. Nevertheless, current DMA designs and models are usually quasi-narrowband, neglecting the versatile frequency-diverse manifestation and its utilization. This work demonstrates the frequency-diversity and dispersion operations of a representative DMA structure at the millimeter-wave band. We demonstrate flexible dispersion manipulation through dynamic holographic reconfigurability of the meta-atoms in a DMA. This effect can create distinct radiation patterns across the operating frequency band, achieving flexible frequency diversity with enhanced scanning range within a compact, reconfigurable platform. It eliminates the need for wideband systems or complex phase-shifting networks while offering an alternative to frequency-scanned static beams of traditional leaky-wave antennas. The results establish fundamental insights into modelling and utilization of dispersive effects of DMAs in next-generation near-field and far-field holographic sensing and computational holographic imaging applications.
AI-Mediated Code Comment Improvement
May 13, 2025This paper describes an approach to improve code comments along different quality axes by rewriting those comments with customized Artificial Intelligence (AI)-based tools. We conduct an empirical study followed by grounded theory qualitative analysis to determine the quality axes to improve. Then we propose a procedure using a Large Language Model (LLM) to rewrite existing code comments along the quality axes. We implement our procedure using GPT-4o, then distil the results into a smaller model capable of being run in-house, so users can maintain data custody. We evaluate both our approach using GPT-4o and the distilled model versions. We show in an evaluation how our procedure improves code comments along the quality axes. We release all data and source code in an online repository for reproducibility.
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024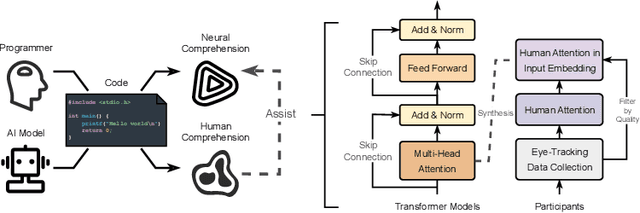
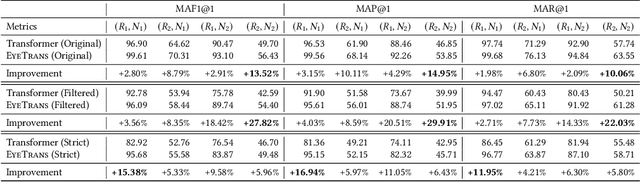
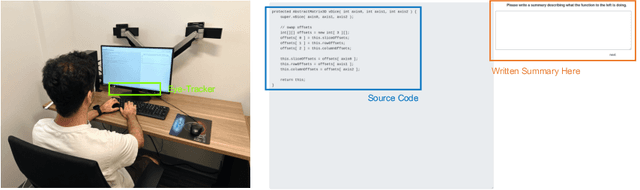
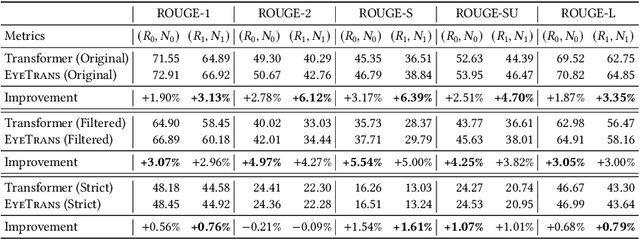
Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Revisiting File Context for Source Code Summarization
Sep 05, 2023Source code summarization is the task of writing natural language descriptions of source code. A typical use case is generating short summaries of subroutines for use in API documentation. The heart of almost all current research into code summarization is the encoder-decoder neural architecture, and the encoder input is almost always a single subroutine or other short code snippet. The problem with this setup is that the information needed to describe the code is often not present in the code itself -- that information often resides in other nearby code. In this paper, we revisit the idea of ``file context'' for code summarization. File context is the idea of encoding select information from other subroutines in the same file. We propose a novel modification of the Transformer architecture that is purpose-built to encode file context and demonstrate its improvement over several baselines. We find that file context helps on a subset of challenging examples where traditional approaches struggle.
Statement-based Memory for Neural Source Code Summarization
Jul 21, 2023Source code summarization is the task of writing natural language descriptions of source code behavior. Code summarization underpins software documentation for programmers. Short descriptions of code help programmers understand the program quickly without having to read the code itself. Lately, neural source code summarization has emerged as the frontier of research into automated code summarization techniques. By far the most popular targets for summarization are program subroutines. The idea, in a nutshell, is to train an encoder-decoder neural architecture using large sets of examples of subroutines extracted from code repositories. The encoder represents the code and the decoder represents the summary. However, most current approaches attempt to treat the subroutine as a single unit. For example, by taking the entire subroutine as input to a Transformer or RNN-based encoder. But code behavior tends to depend on the flow from statement to statement. Normally dynamic analysis may shed light on this flow, but dynamic analysis on hundreds of thousands of examples in large datasets is not practical. In this paper, we present a statement-based memory encoder that learns the important elements of flow during training, leading to a statement-based subroutine representation without the need for dynamic analysis. We implement our encoder for code summarization and demonstrate a significant improvement over the state-of-the-art.
Towards Modeling Human Attention from Eye Movements for Neural Source Code Summarization
May 16, 2023Neural source code summarization is the task of generating natural language descriptions of source code behavior using neural networks. A fundamental component of most neural models is an attention mechanism. The attention mechanism learns to connect features in source code to specific words to use when generating natural language descriptions. Humans also pay attention to some features in code more than others. This human attention reflects experience and high-level cognition well beyond the capability of any current neural model. In this paper, we use data from published eye-tracking experiments to create a model of this human attention. The model predicts which words in source code are the most important for code summarization. Next, we augment a baseline neural code summarization approach using our model of human attention. We observe an improvement in prediction performance of the augmented approach in line with other bio-inspired neural models.
A Language Model of Java Methods with Train/Test Deduplication
May 15, 2023This tool demonstration presents a research toolkit for a language model of Java source code. The target audience includes researchers studying problems at the granularity level of subroutines, statements, or variables in Java. In contrast to many existing language models, we prioritize features for researchers including an open and easily-searchable training set, a held out test set with different levels of deduplication from the training set, infrastructure for deduplicating new examples, and an implementation platform suitable for execution on equipment accessible to a relatively modest budget. Our model is a GPT2-like architecture with 350m parameters. Our training set includes 52m Java methods (9b tokens) and 13m StackOverflow threads (10.5b tokens). To improve accessibility of research to more members of the community, we limit local resource requirements to GPUs with 16GB video memory. We provide a test set of held out Java methods that include descriptive comments, including the entire Java projects for those methods. We also provide deduplication tools using precomputed hash tables at various similarity thresholds to help researchers ensure that their own test examples are not in the training set. We make all our tools and data open source and available via Huggingface and Github.
Project-Level Encoding for Neural Source Code Summarization of Subroutines
Mar 22, 2021
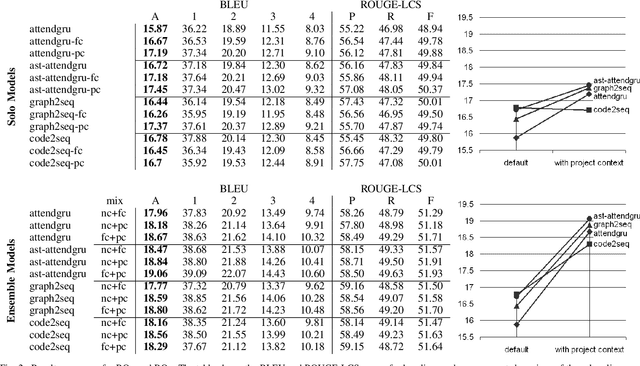
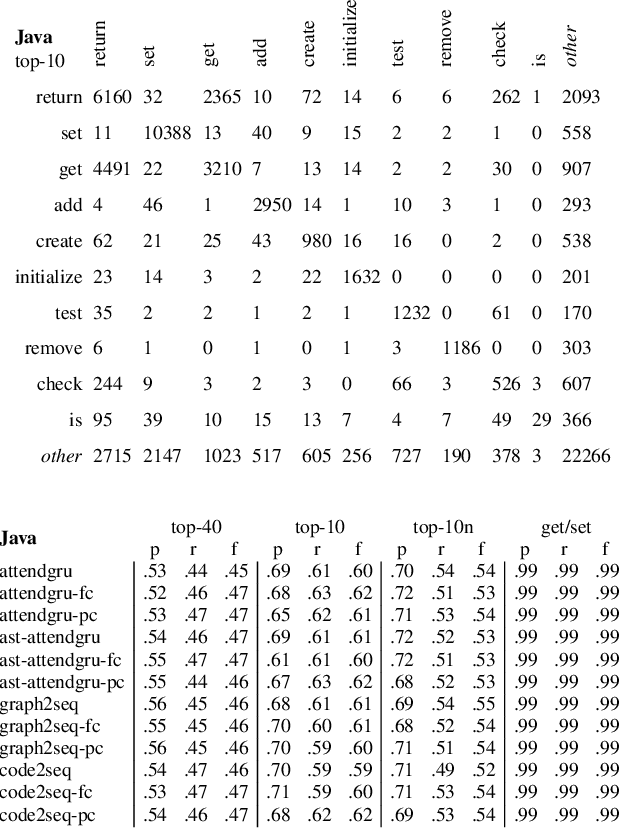
Source code summarization of a subroutine is the task of writing a short, natural language description of that subroutine. The description usually serves in documentation aimed at programmers, where even brief phrase (e.g. "compresses data to a zip file") can help readers rapidly comprehend what a subroutine does without resorting to reading the code itself. Techniques based on neural networks (and encoder-decoder model designs in particular) have established themselves as the state-of-the-art. Yet a problem widely recognized with these models is that they assume the information needed to create a summary is present within the code being summarized itself - an assumption which is at odds with program comprehension literature. Thus a current research frontier lies in the question of encoding source code context into neural models of summarization. In this paper, we present a project-level encoder to improve models of code summarization. By project-level, we mean that we create a vectorized representation of selected code files in a software project, and use that representation to augment the encoder of state-of-the-art neural code summarization techniques. We demonstrate how our encoder improves several existing models, and provide guidelines for maximizing improvement while controlling time and resource costs in model size.
A Neural Question Answering System for Basic Questions about Subroutines
Jan 11, 2021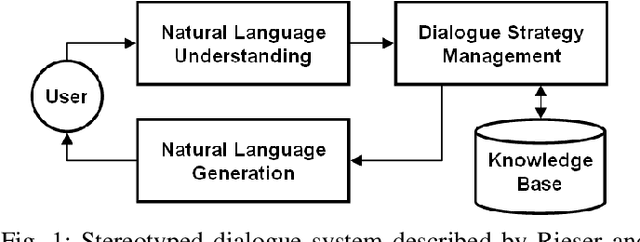
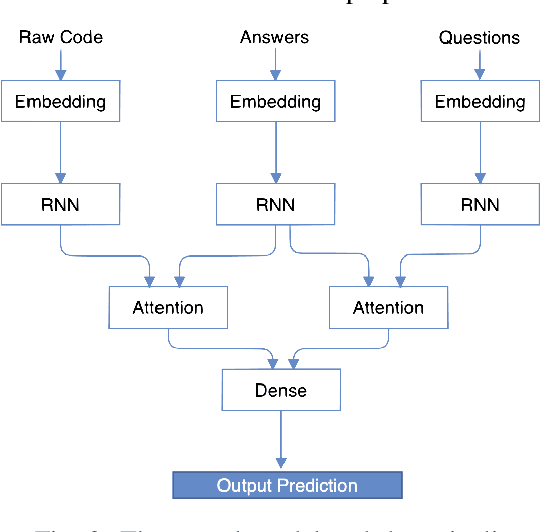
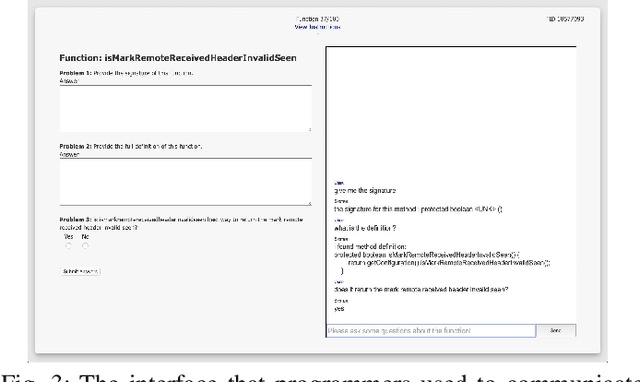
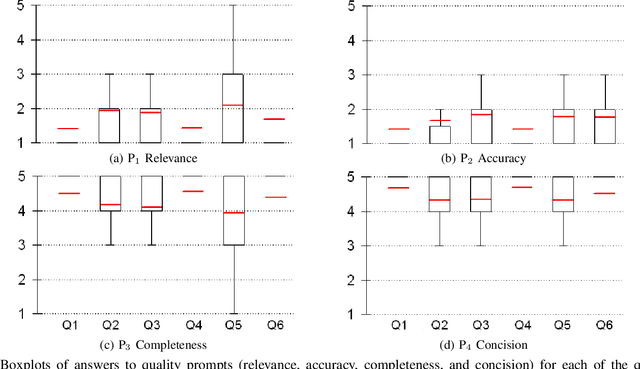
A question answering (QA) system is a type of conversational AI that generates natural language answers to questions posed by human users. QA systems often form the backbone of interactive dialogue systems, and have been studied extensively for a wide variety of tasks ranging from restaurant recommendations to medical diagnostics. Dramatic progress has been made in recent years, especially from the use of encoder-decoder neural architectures trained with big data input. In this paper, we take initial steps to bringing state-of-the-art neural QA technologies to Software Engineering applications by designing a context-based QA system for basic questions about subroutines. We curate a training dataset of 10.9 million question/context/answer tuples based on rules we extract from recent empirical studies. Then, we train a custom neural QA model with this dataset and evaluate the model in a study with professional programmers. We demonstrate the strengths and weaknesses of the system, and lay the groundwork for its use in eventual dialogue systems for software engineering.