 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Code LLM Training with Programmer Attention
Mar 19, 2025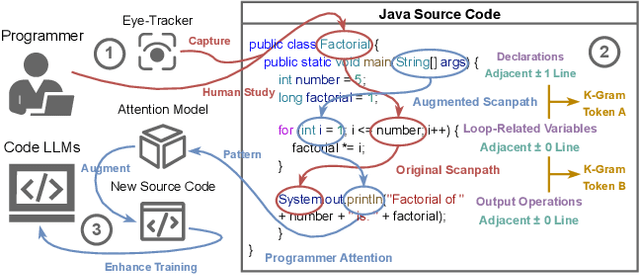
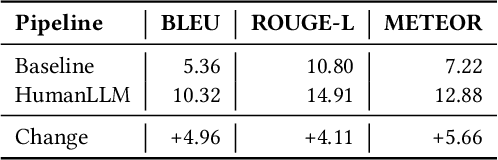
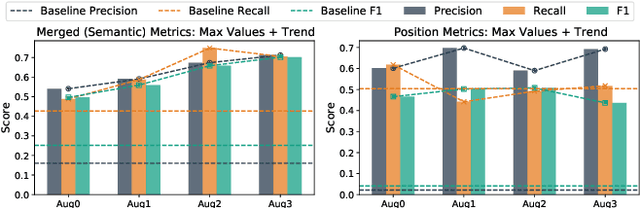
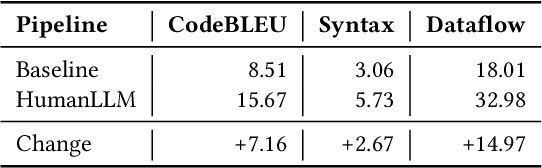
Human attention provides valuable yet underexploited signals for code LLM training, offering a perspective beyond purely machine-driven attention. Despite the complexity and cost of collecting eye-tracking data, there has also been limited progress in systematically using these signals for code LLM training. To address both issues, we propose a cohesive pipeline spanning augmentation and reward-based fine-tuning. Specifically, we introduce (1) an eye-tracking path augmentation method to expand programmer attention datasets, (2) a pattern abstraction step that refines raw fixations into learnable attention motifs, and (3) a reward-guided strategy for integrating these insights directly into a CodeT5 supervised fine-tuning process. Our experiments yield +7.16 in CodeBLEU on the CodeXGlue benchmark for code summarization, underscoring how uniting human and machine attention can boost code intelligence. We hope this work encourages broader exploration of human-centric methods in next-generation AI4SE.
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024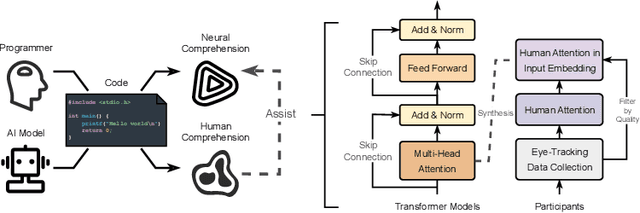
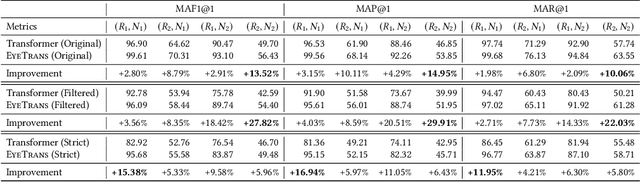
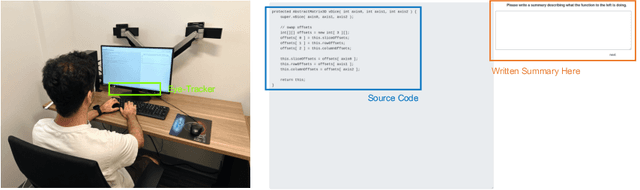
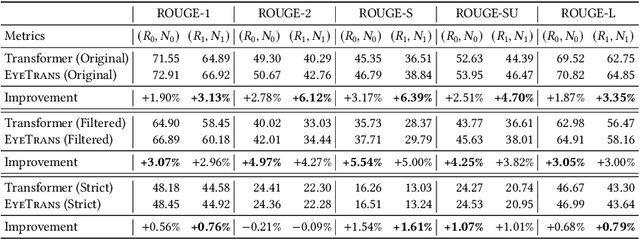
Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization
Feb 22, 2024Recent language models have demonstrated proficiency in summarizing source code. However, as in many other domains of machine learning, language models of code lack sufficient explainability. Informally, we lack a formulaic or intuitive understanding of what and how models learn from code. Explainability of language models can be partially provided if, as the models learn to produce higher-quality code summaries, they also align in deeming the same code parts important as those identified by human programmers. In this paper, we report negative results from our investigation of explainability of language models in code summarization through the lens of human comprehension. We measure human focus on code using eye-tracking metrics such as fixation counts and duration in code summarization tasks. To approximate language model focus, we employ a state-of-the-art model-agnostic, black-box, perturbation-based approach, SHAP (SHapley Additive exPlanations), to identify which code tokens influence that generation of summaries. Using these settings, we find no statistically significant relationship between language models' focus and human programmers' attention. Furthermore, alignment between model and human foci in this setting does not seem to dictate the quality of the LLM-generated summaries. Our study highlights an inability to align human focus with SHAP-based model focus measures. This result calls for future investigation of multiple open questions for explainable language models for code summarization and software engineering tasks in general, including the training mechanisms of language models for code, whether there is an alignment between human and model attention on code, whether human attention can improve the development of language models, and what other model focus measures are appropriate for improving explainability.