 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Code LLM Training with Programmer Attention
Mar 19, 2025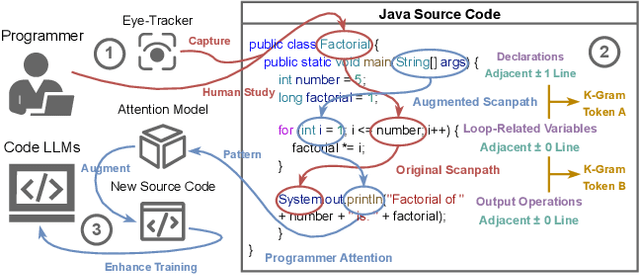
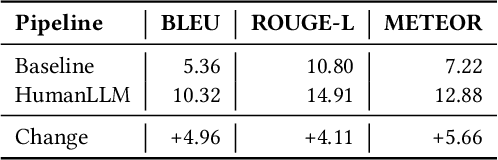
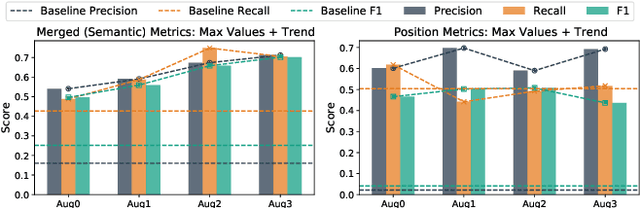
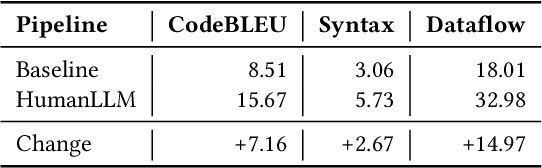
Human attention provides valuable yet underexploited signals for code LLM training, offering a perspective beyond purely machine-driven attention. Despite the complexity and cost of collecting eye-tracking data, there has also been limited progress in systematically using these signals for code LLM training. To address both issues, we propose a cohesive pipeline spanning augmentation and reward-based fine-tuning. Specifically, we introduce (1) an eye-tracking path augmentation method to expand programmer attention datasets, (2) a pattern abstraction step that refines raw fixations into learnable attention motifs, and (3) a reward-guided strategy for integrating these insights directly into a CodeT5 supervised fine-tuning process. Our experiments yield +7.16 in CodeBLEU on the CodeXGlue benchmark for code summarization, underscoring how uniting human and machine attention can boost code intelligence. We hope this work encourages broader exploration of human-centric methods in next-generation AI4SE.
PBP: Post-training Backdoor Purification for Malware Classifiers
Dec 05, 2024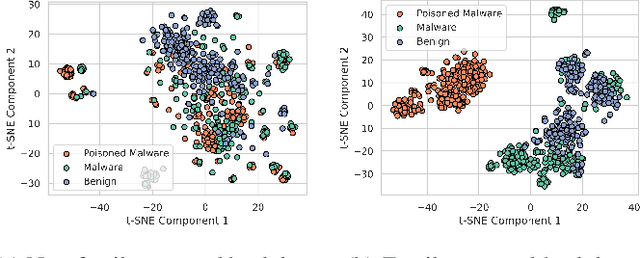
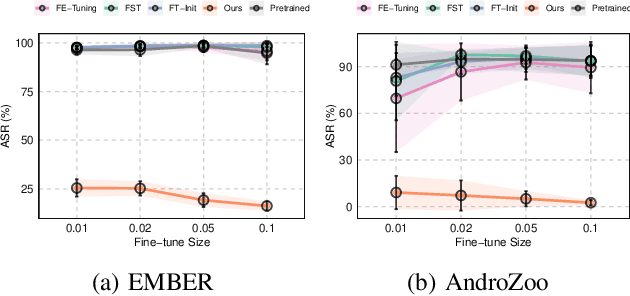
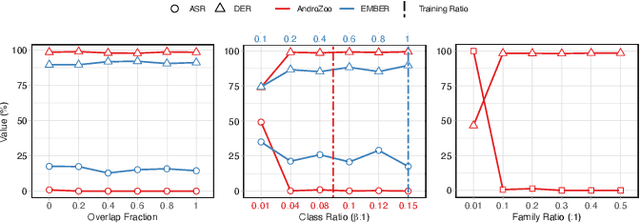
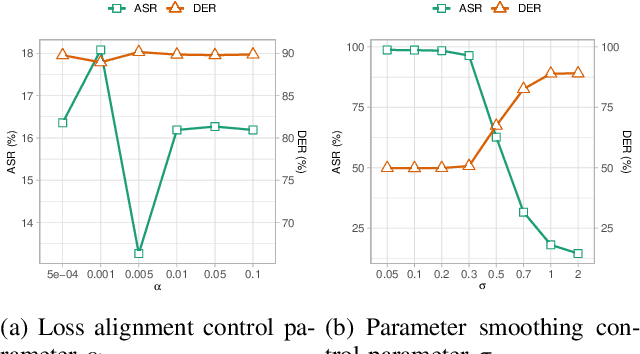
In recent years, the rise of machine learning (ML) in cybersecurity has brought new challenges, including the increasing threat of backdoor poisoning attacks on ML malware classifiers. For instance, adversaries could inject malicious samples into public malware repositories, contaminating the training data and potentially misclassifying malware by the ML model. Current countermeasures predominantly focus on detecting poisoned samples by leveraging disagreements within the outputs of a diverse set of ensemble models on training data points. However, these methods are not suitable for scenarios where Machine Learning-as-a-Service (MLaaS) is used or when users aim to remove backdoors from a model after it has been trained. Addressing this scenario, we introduce PBP, a post-training defense for malware classifiers that mitigates various types of backdoor embeddings without assuming any specific backdoor embedding mechanism. Our method exploits the influence of backdoor attacks on the activation distribution of neural networks, independent of the trigger-embedding method. In the presence of a backdoor attack, the activation distribution of each layer is distorted into a mixture of distributions. By regulating the statistics of the batch normalization layers, we can guide a backdoored model to perform similarly to a clean one. Our method demonstrates substantial advantages over several state-of-the-art methods, as evidenced by experiments on two datasets, two types of backdoor methods, and various attack configurations. Notably, our approach requires only a small portion of the training data -- only 1\% -- to purify the backdoor and reduce the attack success rate from 100\% to almost 0\%, a 100-fold improvement over the baseline methods. Our code is available at \url{https://github.com/judydnguyen/pbp-backdoor-purification-official}.
Formal Logic-guided Robust Federated Learning against Poisoning Attacks
Nov 05, 2024



Federated Learning (FL) offers a promising solution to the privacy concerns associated with centralized Machine Learning (ML) by enabling decentralized, collaborative learning. However, FL is vulnerable to various security threats, including poisoning attacks, where adversarial clients manipulate the training data or model updates to degrade overall model performance. Recognizing this threat, researchers have focused on developing defense mechanisms to counteract poisoning attacks in FL systems. However, existing robust FL methods predominantly focus on computer vision tasks, leaving a gap in addressing the unique challenges of FL with time series data. In this paper, we present FLORAL, a defense mechanism designed to mitigate poisoning attacks in federated learning for time-series tasks, even in scenarios with heterogeneous client data and a large number of adversarial participants. Unlike traditional model-centric defenses, FLORAL leverages logical reasoning to evaluate client trustworthiness by aligning their predictions with global time-series patterns, rather than relying solely on the similarity of client updates. Our approach extracts logical reasoning properties from clients, then hierarchically infers global properties, and uses these to verify client updates. Through formal logic verification, we assess the robustness of each client contribution, identifying deviations indicative of adversarial behavior. Experimental results on two datasets demonstrate the superior performance of our approach compared to existing baseline methods, highlighting its potential to enhance the robustness of FL to time series applications. Notably, FLORAL reduced the prediction error by 93.27\% in the best-case scenario compared to the second-best baseline. Our code is available at \url{https://anonymous.4open.science/r/FLORAL-Robust-FTS}.
FISC: Federated Domain Generalization via Interpolative Style Transfer and Contrastive Learning
Oct 30, 2024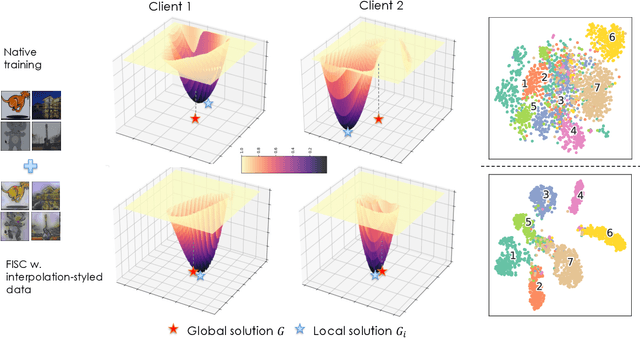
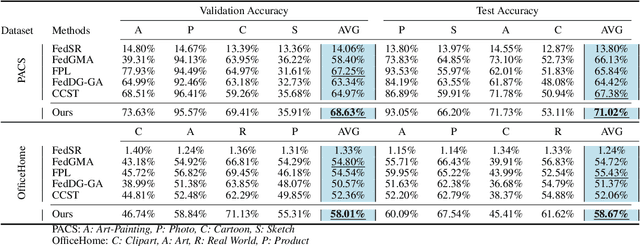
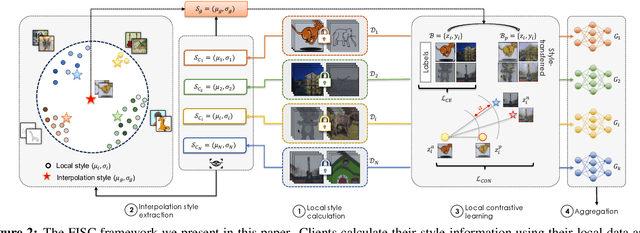
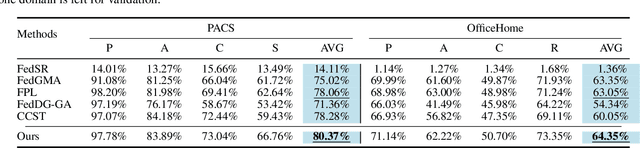
Federated Learning (FL) shows promise in preserving privacy and enabling collaborative learning. However, most current solutions focus on private data collected from a single domain. A significant challenge arises when client data comes from diverse domains (i.e., domain shift), leading to poor performance on unseen domains. Existing Federated Domain Generalization approaches address this problem but assume each client holds data for an entire domain, limiting their practicality in real-world scenarios with domain-based heterogeneity and client sampling. To overcome this, we introduce FISC, a novel FL domain generalization paradigm that handles more complex domain distributions across clients. FISC enables learning across domains by extracting an interpolative style from local styles and employing contrastive learning. This strategy gives clients multi-domain representations and unbiased convergent targets. Empirical results on multiple datasets, including PACS, Office-Home, and IWildCam, show FISC outperforms state-of-the-art (SOTA) methods. Our method achieves accuracy improvements ranging from 3.64% to 57.22% on unseen domains. Our code is available at https://anonymous.4open.science/r/FISC-AAAI-16107.
Non-Cooperative Backdoor Attacks in Federated Learning: A New Threat Landscape
Jul 05, 2024



Despite the promise of Federated Learning (FL) for privacy-preserving model training on distributed data, it remains susceptible to backdoor attacks. These attacks manipulate models by embedding triggers (specific input patterns) in the training data, forcing misclassification as predefined classes during deployment. Traditional single-trigger attacks and recent work on cooperative multiple-trigger attacks, where clients collaborate, highlight limitations in attack realism due to coordination requirements. We investigate a more alarming scenario: non-cooperative multiple-trigger attacks. Here, independent adversaries introduce distinct triggers targeting unique classes. These parallel attacks exploit FL's decentralized nature, making detection difficult. Our experiments demonstrate the alarming vulnerability of FL to such attacks, where individual backdoors can be successfully learned without impacting the main task. This research emphasizes the critical need for robust defenses against diverse backdoor attacks in the evolving FL landscape. While our focus is on empirical analysis, we believe it can guide backdoor research toward more realistic settings, highlighting the crucial role of FL in building robust defenses against diverse backdoor threats. The code is available at \url{https://anonymous.4open.science/r/nba-980F/}.