 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Routing in Sparse Mixture of Experts with Graph of Tokens
May 01, 2025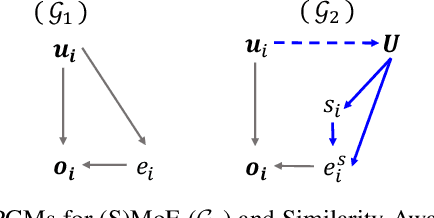
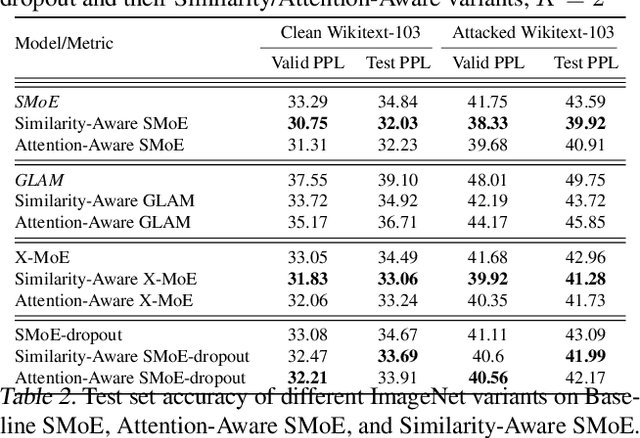
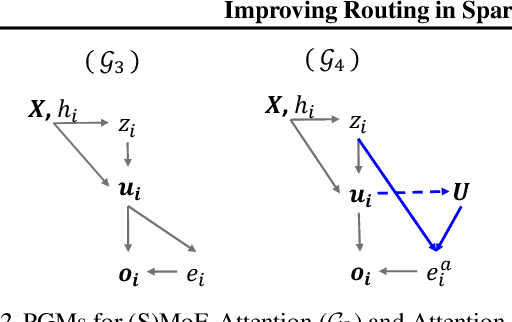
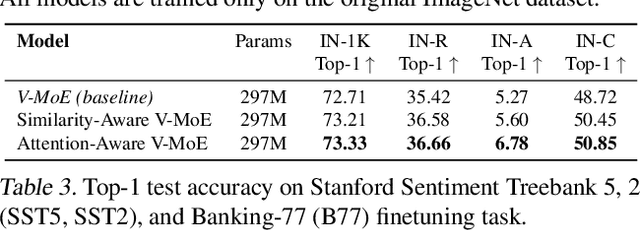
Sparse Mixture of Experts (SMoE) has emerged as a key to achieving unprecedented scalability in deep learning. By activating only a small subset of parameters per sample, SMoE achieves an exponential increase in parameter counts while maintaining a constant computational overhead. However, SMoE models are susceptible to routing fluctuations--changes in the routing of a given input to its target expert--at the late stage of model training, leading to model non-robustness. In this work, we unveil the limitation of SMoE through the perspective of the probabilistic graphical model (PGM). Through this PGM framework, we highlight the independence in the expert-selection of tokens, which exposes the model to routing fluctuation and non-robustness. Alleviating this independence, we propose the novel Similarity-Aware (S)MoE, which considers interactions between tokens during expert selection. We then derive a new PGM underlying an (S)MoE-Attention block, going beyond just a single (S)MoE layer. Leveraging the token similarities captured by the attention matrix, we propose the innovative Attention-Aware (S)MoE, which employs the attention matrix to guide the routing of tokens to appropriate experts in (S)MoE. We theoretically prove that Similarity/Attention-Aware routing help reduce the entropy of expert selection, resulting in more stable token routing mechanisms. We empirically validate our models on various tasks and domains, showing significant improvements in reducing routing fluctuations, enhancing accuracy, and increasing model robustness over the baseline MoE-Transformer with token routing via softmax gating.
PBP: Post-training Backdoor Purification for Malware Classifiers
Dec 05, 2024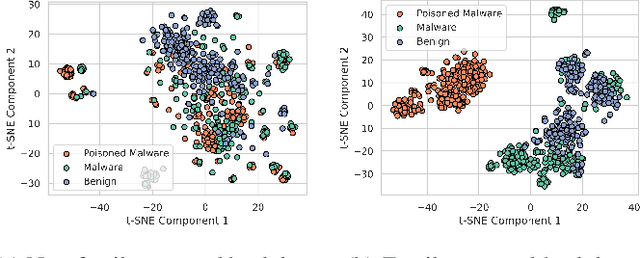
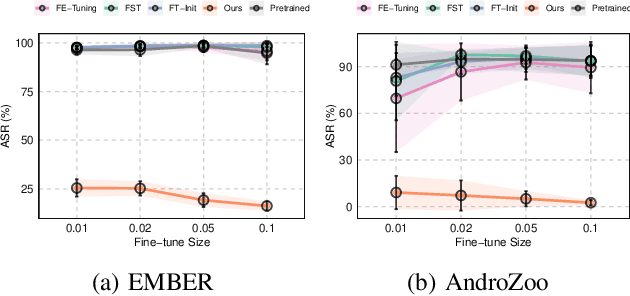
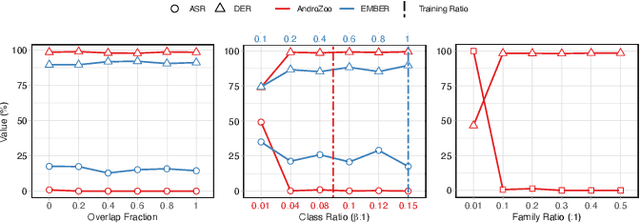
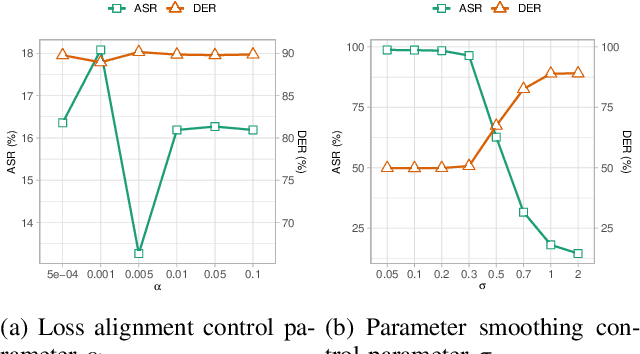
In recent years, the rise of machine learning (ML) in cybersecurity has brought new challenges, including the increasing threat of backdoor poisoning attacks on ML malware classifiers. For instance, adversaries could inject malicious samples into public malware repositories, contaminating the training data and potentially misclassifying malware by the ML model. Current countermeasures predominantly focus on detecting poisoned samples by leveraging disagreements within the outputs of a diverse set of ensemble models on training data points. However, these methods are not suitable for scenarios where Machine Learning-as-a-Service (MLaaS) is used or when users aim to remove backdoors from a model after it has been trained. Addressing this scenario, we introduce PBP, a post-training defense for malware classifiers that mitigates various types of backdoor embeddings without assuming any specific backdoor embedding mechanism. Our method exploits the influence of backdoor attacks on the activation distribution of neural networks, independent of the trigger-embedding method. In the presence of a backdoor attack, the activation distribution of each layer is distorted into a mixture of distributions. By regulating the statistics of the batch normalization layers, we can guide a backdoored model to perform similarly to a clean one. Our method demonstrates substantial advantages over several state-of-the-art methods, as evidenced by experiments on two datasets, two types of backdoor methods, and various attack configurations. Notably, our approach requires only a small portion of the training data -- only 1\% -- to purify the backdoor and reduce the attack success rate from 100\% to almost 0\%, a 100-fold improvement over the baseline methods. Our code is available at \url{https://github.com/judydnguyen/pbp-backdoor-purification-official}.
Robust Contrastive Learning With Theory Guarantee
Nov 16, 2023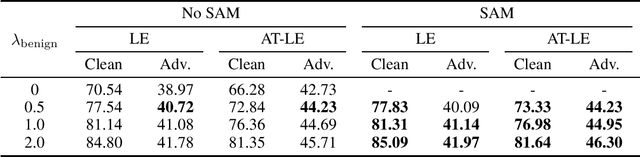

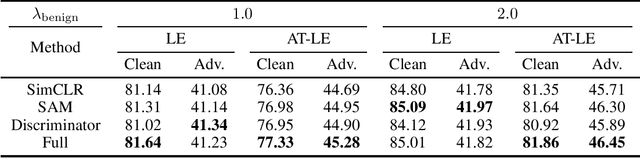
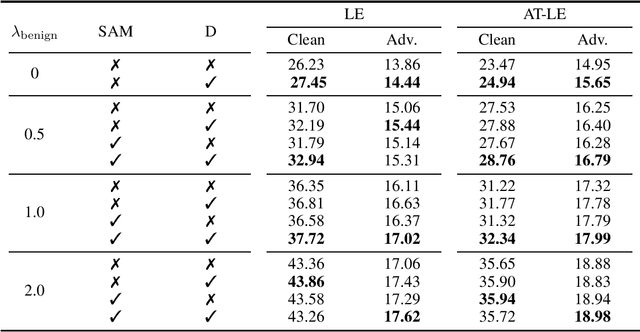
Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.
Sharpness & Shift-Aware Self-Supervised Learning
May 17, 2023

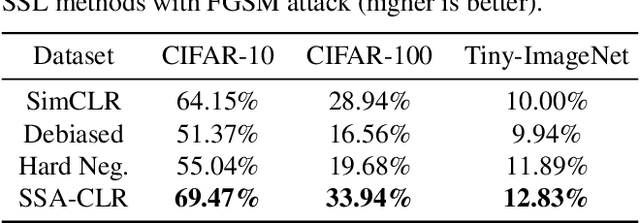
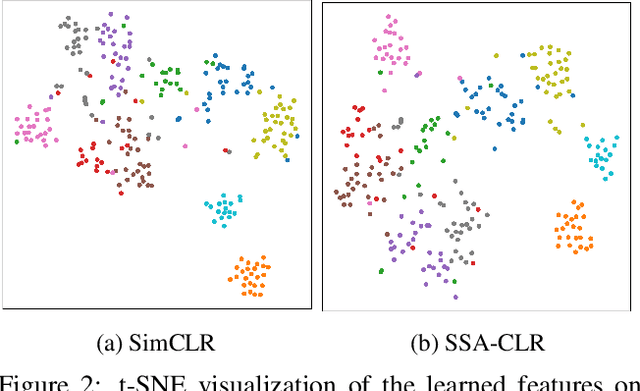
Self-supervised learning aims to extract meaningful features from unlabeled data for further downstream tasks. In this paper, we consider classification as a downstream task in phase 2 and develop rigorous theories to realize the factors that implicitly influence the general loss of this classification task. Our theories signify that sharpness-aware feature extractors benefit the classification task in phase 2 and the existing data shift between the ideal (i.e., the ideal one used in theory development) and practical (i.e., the practical one used in implementation) distributions to generate positive pairs also remarkably affects this classification task. Further harvesting these theoretical findings, we propose to minimize the sharpness of the feature extractor and a new Fourier-based data augmentation technique to relieve the data shift in the distributions generating positive pairs, reaching Sharpness & Shift-Aware Contrastive Learning (SSA-CLR). We conduct extensive experiments to verify our theoretical findings and demonstrate that sharpness & shift-aware contrastive learning can remarkably boost the performance as well as obtaining more robust extracted features compared with the baselines.
Multiple Perturbation Attack: Attack Pixelwise Under Different $\ell_p$-norms For Better Adversarial Performance
Dec 07, 2022



Adversarial machine learning has been both a major concern and a hot topic recently, especially with the ubiquitous use of deep neural networks in the current landscape. Adversarial attacks and defenses are usually likened to a cat-and-mouse game in which defenders and attackers evolve over the time. On one hand, the goal is to develop strong and robust deep networks that are resistant to malicious actors. On the other hand, in order to achieve that, we need to devise even stronger adversarial attacks to challenge these defense models. Most of existing attacks employs a single $\ell_p$ distance (commonly, $p\in\{1,2,\infty\}$) to define the concept of closeness and performs steepest gradient ascent w.r.t. this $p$-norm to update all pixels in an adversarial example in the same way. These $\ell_p$ attacks each has its own pros and cons; and there is no single attack that can successfully break through defense models that are robust against multiple $\ell_p$ norms simultaneously. Motivated by these observations, we come up with a natural approach: combining various $\ell_p$ gradient projections on a pixel level to achieve a joint adversarial perturbation. Specifically, we learn how to perturb each pixel to maximize the attack performance, while maintaining the overall visual imperceptibility of adversarial examples. Finally, through various experiments with standardized benchmarks, we show that our method outperforms most current strong attacks across state-of-the-art defense mechanisms, while retaining its ability to remain clean visually.
Improving Multi-task Learning via Seeking Task-based Flat Regions
Nov 24, 2022



Multi-Task Learning (MTL) is a widely-used and powerful learning paradigm for training deep neural networks that allows learning more than one objective by a single backbone. Compared to training tasks separately, MTL significantly reduces computational costs, improves data efficiency, and potentially enhances model performance by leveraging knowledge across tasks. Hence, it has been adopted in a variety of applications, ranging from computer vision to natural language processing and speech recognition. Among them, there is an emerging line of work in MTL that focuses on manipulating the task gradient to derive an ultimate gradient descent direction to benefit all tasks. Despite achieving impressive results on many benchmarks, directly applying these approaches without using appropriate regularization techniques might lead to suboptimal solutions on real-world problems. In particular, standard training that minimizes the empirical loss on the training data can easily suffer from overfitting to low-resource tasks or be spoiled by noisy-labeled ones, which can cause negative transfer between tasks and overall performance drop. To alleviate such problems, we propose to leverage a recently introduced training method, named Sharpness-aware Minimization, which can enhance model generalization ability on single-task learning. Accordingly, we present a novel MTL training methodology, encouraging the model to find task-based flat minima for coherently improving its generalization capability on all tasks. Finally, we conduct comprehensive experiments on a variety of applications to demonstrate the merit of our proposed approach to existing gradient-based MTL methods, as suggested by our developed theory.
ReINTEL Challenge 2020: A Comparative Study of Hybrid Deep Neural Network for Reliable Intelligence Identification on Vietnamese SNSs
Sep 27, 2021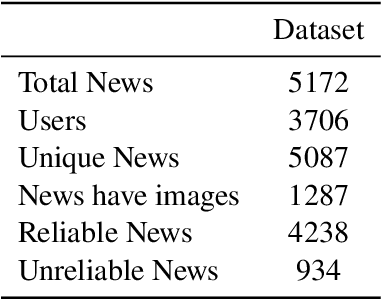
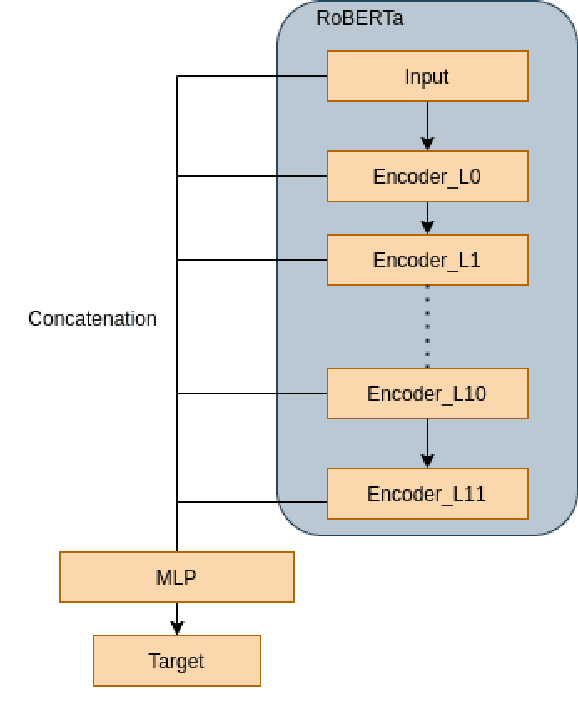
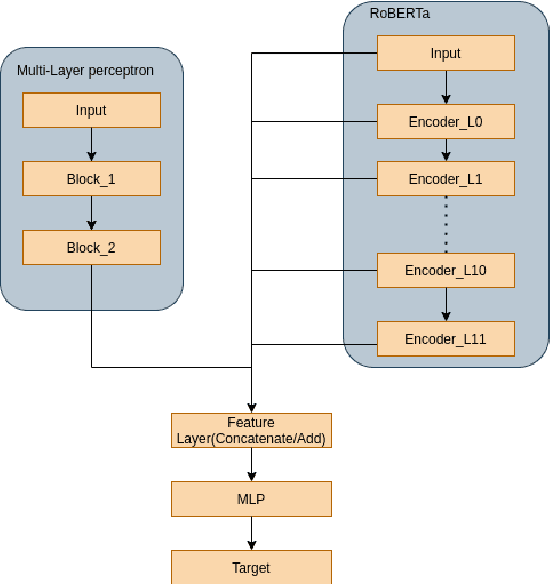
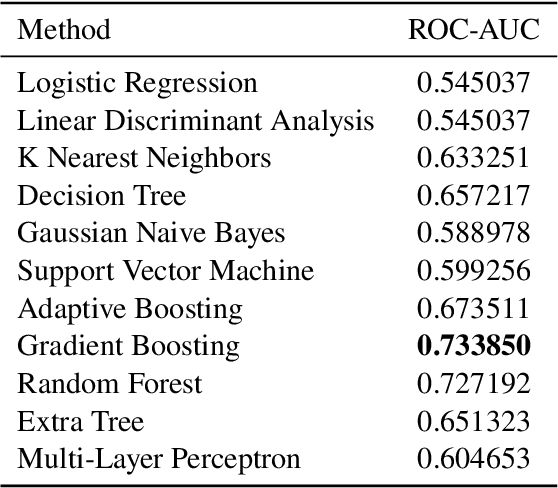
The overwhelming abundance of data has created a misinformation crisis. Unverified sensationalism that is designed to grab the readers' short attention span, when crafted with malice, has caused irreparable damage to our society's structure. As a result, determining the reliability of an article has become a crucial task. After various ablation studies, we propose a multi-input model that can effectively leverage both tabular metadata and post content for the task. Applying state-of-the-art finetuning techniques for the pretrained component and training strategies for our complete model, we have achieved a 0.9462 ROC-score on the VLSP private test set.
Efficient Low-Latency Dynamic Licensing for Deep Neural Network Deployment on Edge Devices
Feb 24, 2021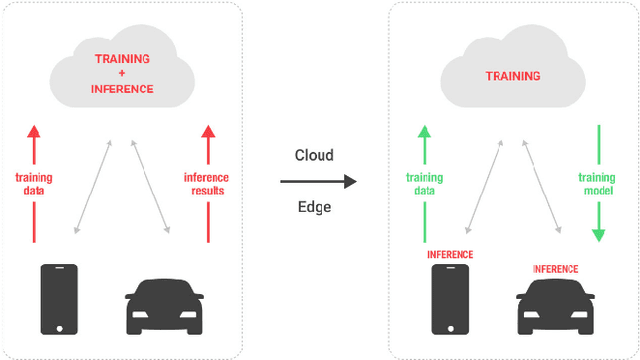
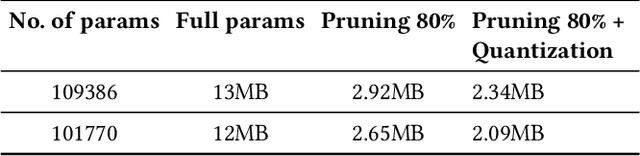
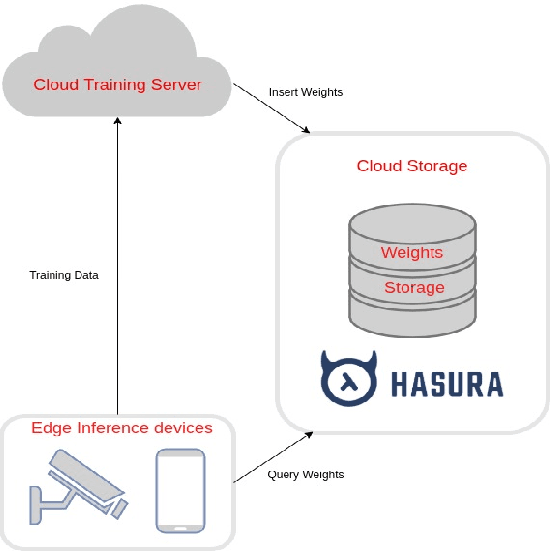

Along with the rapid development in the field of artificial intelligence, especially deep learning, deep neural network applications are becoming more and more popular in reality. To be able to withstand the heavy load from mainstream users, deployment techniques are essential in bringing neural network models from research to production. Among the two popular computing topologies for deploying neural network models in production are cloud-computing and edge-computing. Recent advances in communication technologies, along with the great increase in the number of mobile devices, has made edge-computing gradually become an inevitable trend. In this paper, we propose an architecture to solve deploying and processing deep neural networks on edge-devices by leveraging their synergy with the cloud and the access-control mechanisms of the database. Adopting this architecture allows low-latency DNN model updates on devices. At the same time, with only one model deployed, we can easily make different versions of it by setting access permissions on the model weights. This method allows for dynamic model licensing, which benefits commercial applications.
* Published in 2020 The 3rd International Conference on Computational Intelligence and Intelligent Systems
From Universal Language Model to Downstream Task: Improving RoBERTa-Based Vietnamese Hate Speech Detection
Feb 24, 2021Natural language processing is a fast-growing field of artificial intelligence. Since the Transformer was introduced by Google in 2017, a large number of language models such as BERT, GPT, and ELMo have been inspired by this architecture. These models were trained on huge datasets and achieved state-of-the-art results on natural language understanding. However, fine-tuning a pre-trained language model on much smaller datasets for downstream tasks requires a carefully-designed pipeline to mitigate problems of the datasets such as lack of training data and imbalanced data. In this paper, we propose a pipeline to adapt the general-purpose RoBERTa language model to a specific text classification task: Vietnamese Hate Speech Detection. We first tune the PhoBERT on our dataset by re-training the model on the Masked Language Model task; then, we employ its encoder for text classification. In order to preserve pre-trained weights while learning new feature representations, we further utilize different training techniques: layer freezing, block-wise learning rate, and label smoothing. Our experiments proved that our proposed pipeline boosts the performance significantly, achieving a new state-of-the-art on Vietnamese Hate Speech Detection campaign with 0.7221 F1 score.
* Published in 2020 12th International Conference on Knowledge and Systems Engineering (KSE)
Interpreting the Latent Space of Generative Adversarial Networks using Supervised Learning
Feb 24, 2021
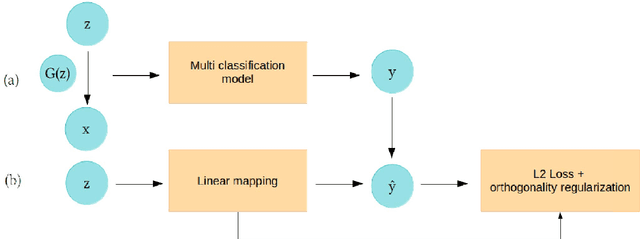


With great progress in the development of Generative Adversarial Networks (GANs), in recent years, the quest for insights in understanding and manipulating the latent space of GAN has gained more and more attention due to its wide range of applications. While most of the researches on this task have focused on unsupervised learning method, which induces difficulties in training and limitation in results, our work approaches another direction, encoding human's prior knowledge to discover more about the hidden space of GAN. With this supervised manner, we produce promising results, demonstrated by accurate manipulation of generated images. Even though our model is more suitable for task-specific problems, we hope that its ease in implementation, preciseness, robustness, and the allowance of richer set of properties (compared to other approaches) for image manipulation can enhance the result of many current applications.
* Published in 2020 International Conference on Advanced Computing and Applications (ACOMP)