 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting the Latent Space of Generative Adversarial Networks using Supervised Learning
Feb 24, 2021
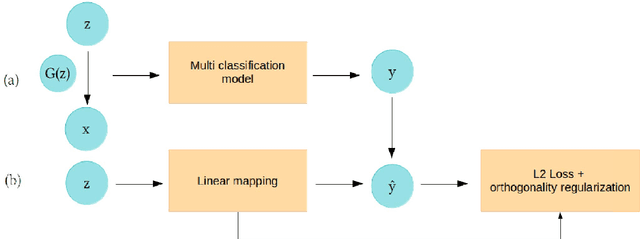


With great progress in the development of Generative Adversarial Networks (GANs), in recent years, the quest for insights in understanding and manipulating the latent space of GAN has gained more and more attention due to its wide range of applications. While most of the researches on this task have focused on unsupervised learning method, which induces difficulties in training and limitation in results, our work approaches another direction, encoding human's prior knowledge to discover more about the hidden space of GAN. With this supervised manner, we produce promising results, demonstrated by accurate manipulation of generated images. Even though our model is more suitable for task-specific problems, we hope that its ease in implementation, preciseness, robustness, and the allowance of richer set of properties (compared to other approaches) for image manipulation can enhance the result of many current applications.
* Published in 2020 International Conference on Advanced Computing and Applications (ACOMP)
Deep Neural Networks based Invisible Steganography for Audio-into-Image Algorithm
Feb 18, 2021
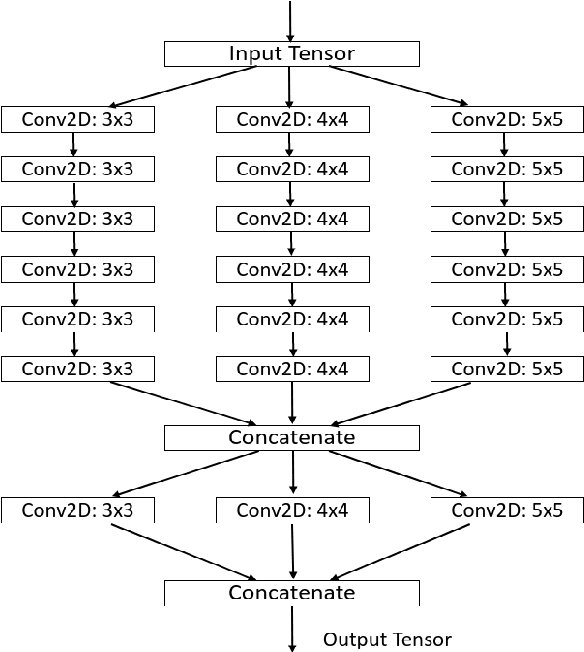

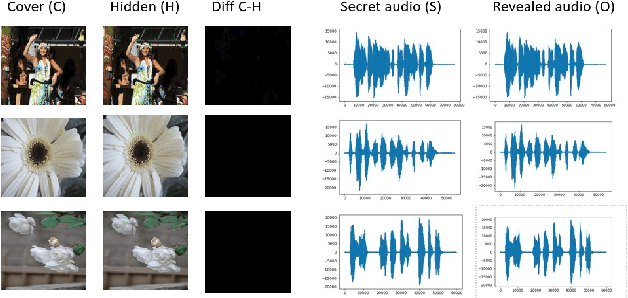
In the last few years, steganography has attracted increasing attention from a large number of researchers since its applications are expanding further than just the field of information security. The most traditional method is based on digital signal processing, such as least significant bit encoding. Recently, there have been some new approaches employing deep learning to address the problem of steganography. However, most of the existing approaches are designed for image-in-image steganography. In this paper, the use of deep learning techniques to hide secret audio into the digital images is proposed. We employ a joint deep neural network architecture consisting of two sub-models: the first network hides the secret audio into an image, and the second one is responsible for decoding the image to obtain the original audio. Extensive experiments are conducted with a set of 24K images and the VIVOS Corpus audio dataset. Through experimental results, it can be seen that our method is more effective than traditional approaches. The integrity of both image and audio is well preserved, while the maximum length of the hidden audio is significantly improved.
* Published in 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE)