 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline pseudo labeling for polyp segmentation with momentum networks
Sep 29, 2022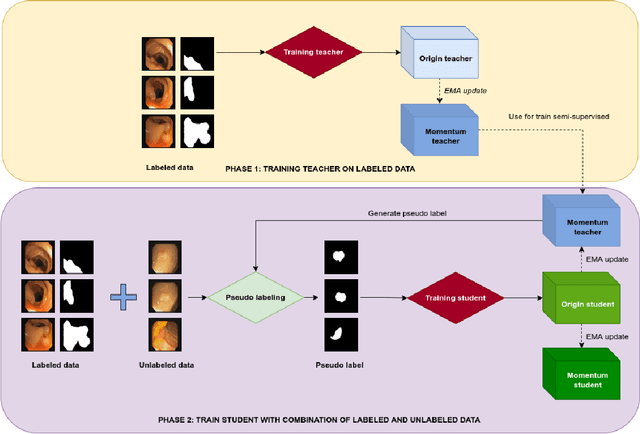


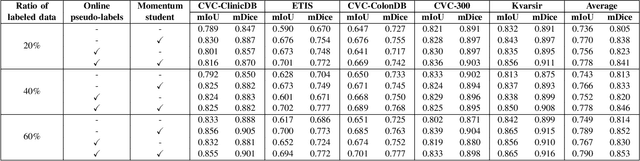
Semantic segmentation is an essential task in developing medical image diagnosis systems. However, building an annotated medical dataset is expensive. Thus, semi-supervised methods are significant in this circumstance. In semi-supervised learning, the quality of labels plays a crucial role in model performance. In this work, we present a new pseudo labeling strategy that enhances the quality of pseudo labels used for training student networks. We follow the multi-stage semi-supervised training approach, which trains a teacher model on a labeled dataset and then uses the trained teacher to render pseudo labels for student training. By doing so, the pseudo labels will be updated and more precise as training progress. The key difference between previous and our methods is that we update the teacher model during the student training process. So the quality of pseudo labels is improved during the student training process. We also propose a simple but effective strategy to enhance the quality of pseudo labels using a momentum model -- a slow copy version of the original model during training. By applying the momentum model combined with re-rendering pseudo labels during student training, we achieved an average of 84.1% Dice Score on five datasets (i.e., Kvarsir, CVC-ClinicDB, ETIS-LaribPolypDB, CVC-ColonDB, and CVC-300) with only 20% of the dataset used as labeled data. Our results surpass common practice by 3% and even approach fully-supervised results on some datasets. Our source code and pre-trained models are available at https://github.com/sun-asterisk-research/online learning ssl
Efficient Low-Latency Dynamic Licensing for Deep Neural Network Deployment on Edge Devices
Feb 24, 2021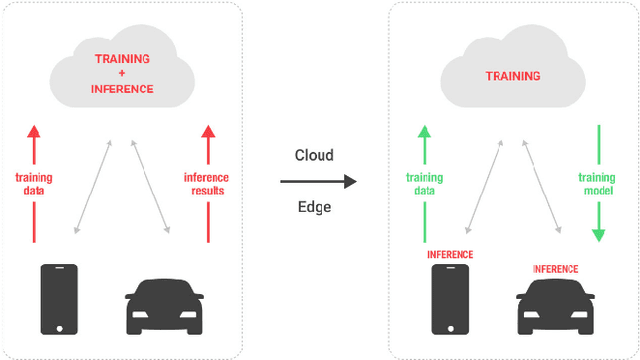
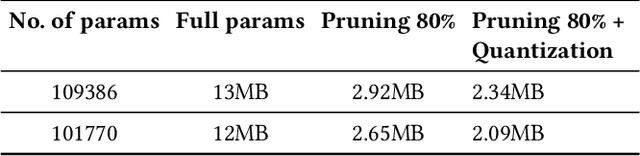
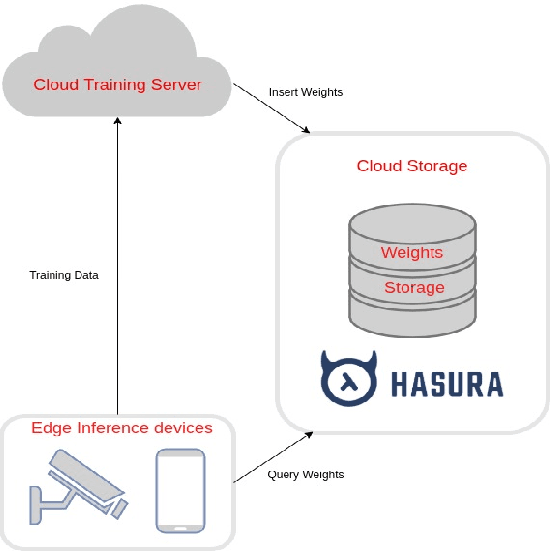

Along with the rapid development in the field of artificial intelligence, especially deep learning, deep neural network applications are becoming more and more popular in reality. To be able to withstand the heavy load from mainstream users, deployment techniques are essential in bringing neural network models from research to production. Among the two popular computing topologies for deploying neural network models in production are cloud-computing and edge-computing. Recent advances in communication technologies, along with the great increase in the number of mobile devices, has made edge-computing gradually become an inevitable trend. In this paper, we propose an architecture to solve deploying and processing deep neural networks on edge-devices by leveraging their synergy with the cloud and the access-control mechanisms of the database. Adopting this architecture allows low-latency DNN model updates on devices. At the same time, with only one model deployed, we can easily make different versions of it by setting access permissions on the model weights. This method allows for dynamic model licensing, which benefits commercial applications.
* Published in 2020 The 3rd International Conference on Computational Intelligence and Intelligent Systems
Interpreting the Latent Space of Generative Adversarial Networks using Supervised Learning
Feb 24, 2021
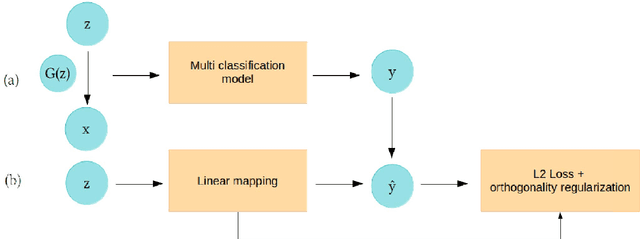


With great progress in the development of Generative Adversarial Networks (GANs), in recent years, the quest for insights in understanding and manipulating the latent space of GAN has gained more and more attention due to its wide range of applications. While most of the researches on this task have focused on unsupervised learning method, which induces difficulties in training and limitation in results, our work approaches another direction, encoding human's prior knowledge to discover more about the hidden space of GAN. With this supervised manner, we produce promising results, demonstrated by accurate manipulation of generated images. Even though our model is more suitable for task-specific problems, we hope that its ease in implementation, preciseness, robustness, and the allowance of richer set of properties (compared to other approaches) for image manipulation can enhance the result of many current applications.
* Published in 2020 International Conference on Advanced Computing and Applications (ACOMP)
Efficient Palm-Line Segmentation with U-Net Context Fusion Module
Feb 24, 2021
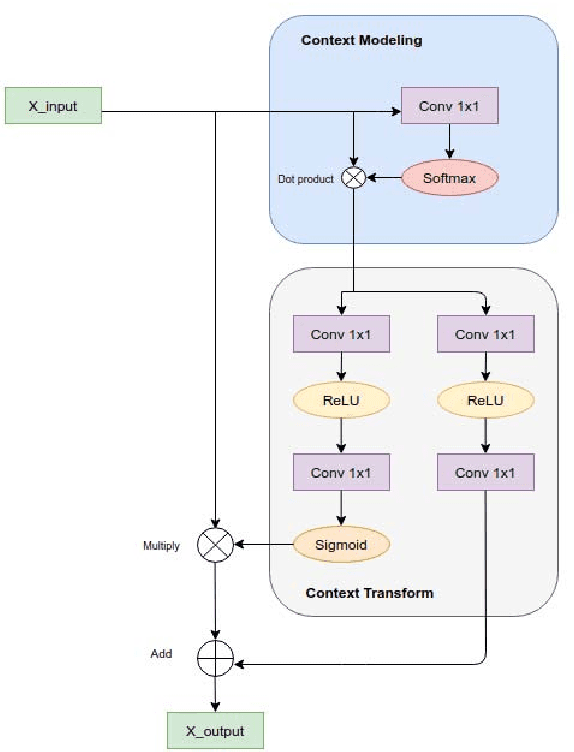
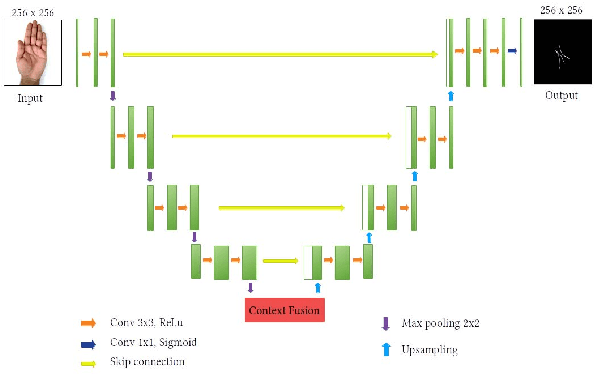

Many cultures around the world believe that palm reading can be used to predict the future life of a person. Palmistry uses features of the hand such as palm lines, hand shape, or fingertip position. However, the research on palm-line detection is still scarce, many of them applied traditional image processing techniques. In most real-world scenarios, images usually are not in well-conditioned, causing these methods to severely under-perform. In this paper, we propose an algorithm to extract principle palm lines from an image of a person's hand. Our method applies deep learning networks (DNNs) to improve performance. Another challenge of this problem is the lack of training data. To deal with this issue, we handcrafted a dataset from scratch. From this dataset, we compare the performance of readily available methods with ours. Furthermore, based on the UNet segmentation neural network architecture and the knowledge of attention mechanism, we propose a highly efficient architecture to detect palm-lines. We proposed the Context Fusion Module to capture the most important context feature, which aims to improve segmentation accuracy. The experimental results show that it outperforms the other methods with the highest F1 Score about 99.42% and mIoU is 0.584 for the same dataset.
* Published in 2020 International Conference on Advanced Computing and Applications (ACOMP)
Deep Learning Approach for Singer Voice Classification of Vietnamese Popular Music
Feb 24, 2021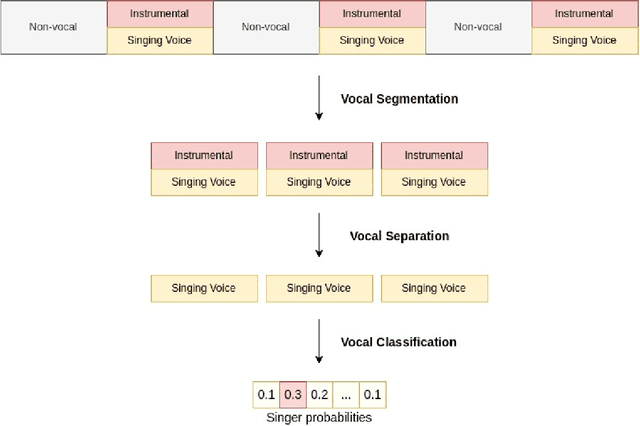
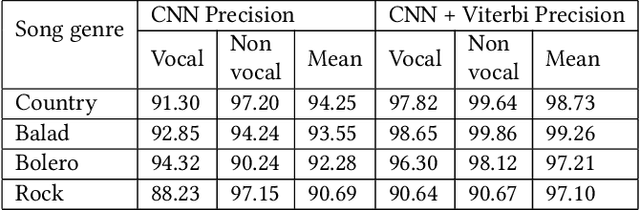
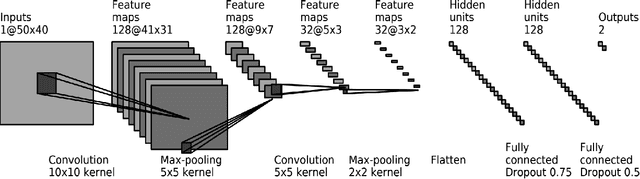

Singer voice classification is a meaningful task in the digital era. With a huge number of songs today, identifying a singer is very helpful for music information retrieval, music properties indexing, and so on. In this paper, we propose a new method to identify the singer's name based on analysis of Vietnamese popular music. We employ the use of vocal segment detection and singing voice separation as the pre-processing steps. The purpose of these steps is to extract the singer's voice from the mixture sound. In order to build a singer classifier, we propose a neural network architecture working with Mel Frequency Cepstral Coefficient as extracted input features from said vocal. To verify the accuracy of our methods, we evaluate on a dataset of 300 Vietnamese songs from 18 famous singers. We achieve an accuracy of 92.84% with 5-fold stratified cross-validation, the best result compared to other methods on the same data set.
* Published in SoICT 2019: Proceedings of the Tenth International Symposium on Information and Communication Technology
Deep Neural Networks based Invisible Steganography for Audio-into-Image Algorithm
Feb 18, 2021
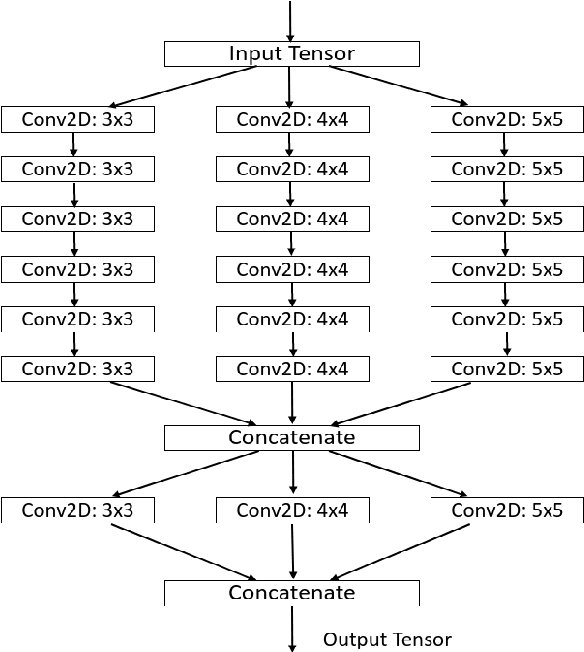

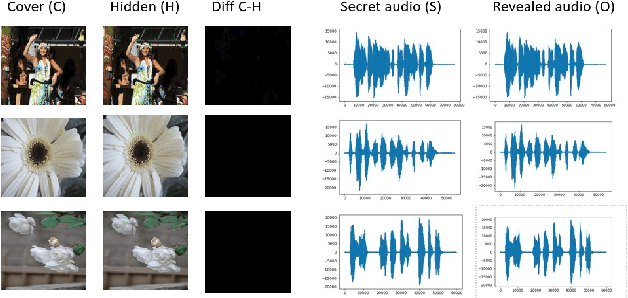
In the last few years, steganography has attracted increasing attention from a large number of researchers since its applications are expanding further than just the field of information security. The most traditional method is based on digital signal processing, such as least significant bit encoding. Recently, there have been some new approaches employing deep learning to address the problem of steganography. However, most of the existing approaches are designed for image-in-image steganography. In this paper, the use of deep learning techniques to hide secret audio into the digital images is proposed. We employ a joint deep neural network architecture consisting of two sub-models: the first network hides the secret audio into an image, and the second one is responsible for decoding the image to obtain the original audio. Extensive experiments are conducted with a set of 24K images and the VIVOS Corpus audio dataset. Through experimental results, it can be seen that our method is more effective than traditional approaches. The integrity of both image and audio is well preserved, while the maximum length of the hidden audio is significantly improved.
* Published in 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE)