 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReINTEL Challenge 2020: A Comparative Study of Hybrid Deep Neural Network for Reliable Intelligence Identification on Vietnamese SNSs
Sep 27, 2021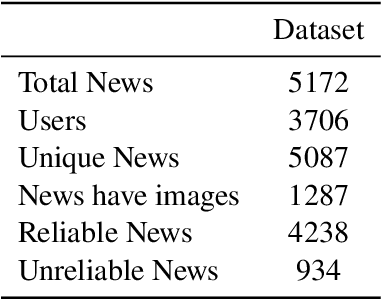
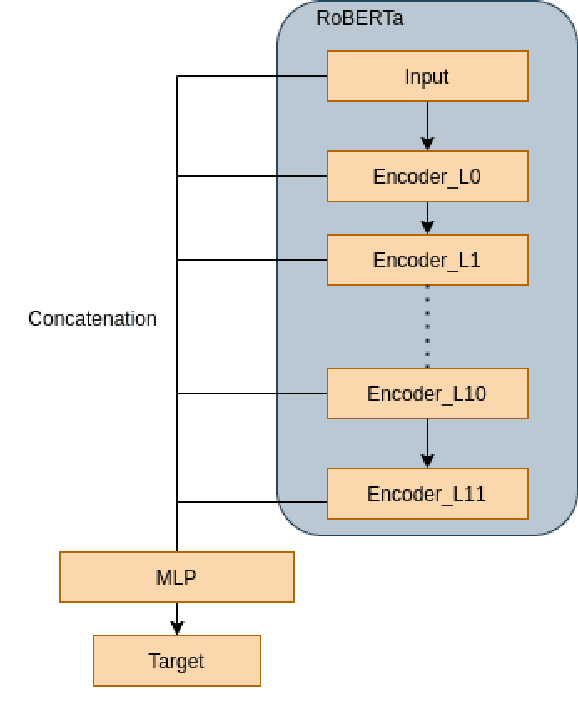
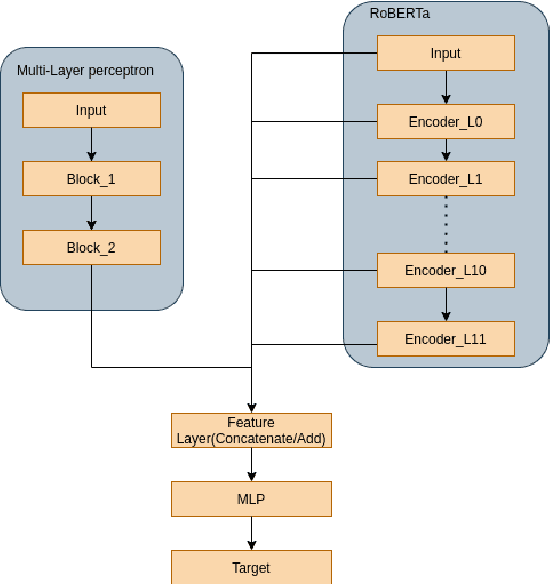
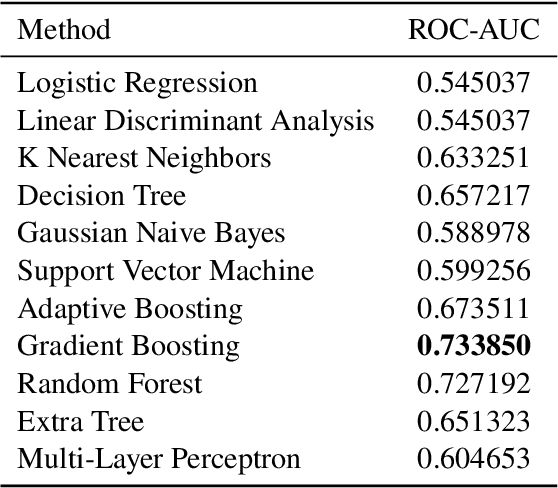
The overwhelming abundance of data has created a misinformation crisis. Unverified sensationalism that is designed to grab the readers' short attention span, when crafted with malice, has caused irreparable damage to our society's structure. As a result, determining the reliability of an article has become a crucial task. After various ablation studies, we propose a multi-input model that can effectively leverage both tabular metadata and post content for the task. Applying state-of-the-art finetuning techniques for the pretrained component and training strategies for our complete model, we have achieved a 0.9462 ROC-score on the VLSP private test set.
From Universal Language Model to Downstream Task: Improving RoBERTa-Based Vietnamese Hate Speech Detection
Feb 24, 2021Natural language processing is a fast-growing field of artificial intelligence. Since the Transformer was introduced by Google in 2017, a large number of language models such as BERT, GPT, and ELMo have been inspired by this architecture. These models were trained on huge datasets and achieved state-of-the-art results on natural language understanding. However, fine-tuning a pre-trained language model on much smaller datasets for downstream tasks requires a carefully-designed pipeline to mitigate problems of the datasets such as lack of training data and imbalanced data. In this paper, we propose a pipeline to adapt the general-purpose RoBERTa language model to a specific text classification task: Vietnamese Hate Speech Detection. We first tune the PhoBERT on our dataset by re-training the model on the Masked Language Model task; then, we employ its encoder for text classification. In order to preserve pre-trained weights while learning new feature representations, we further utilize different training techniques: layer freezing, block-wise learning rate, and label smoothing. Our experiments proved that our proposed pipeline boosts the performance significantly, achieving a new state-of-the-art on Vietnamese Hate Speech Detection campaign with 0.7221 F1 score.
* Published in 2020 12th International Conference on Knowledge and Systems Engineering (KSE)
Efficient Palm-Line Segmentation with U-Net Context Fusion Module
Feb 24, 2021
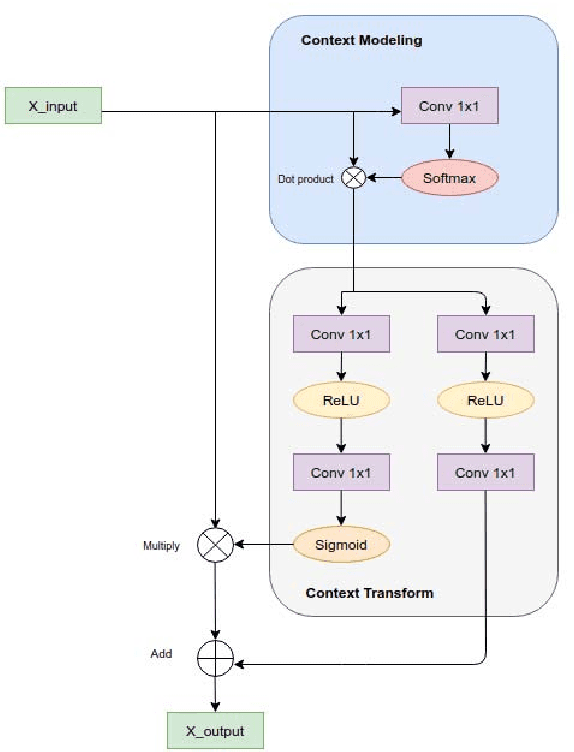
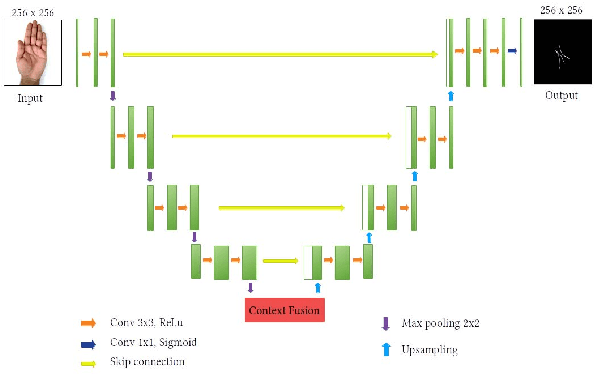

Many cultures around the world believe that palm reading can be used to predict the future life of a person. Palmistry uses features of the hand such as palm lines, hand shape, or fingertip position. However, the research on palm-line detection is still scarce, many of them applied traditional image processing techniques. In most real-world scenarios, images usually are not in well-conditioned, causing these methods to severely under-perform. In this paper, we propose an algorithm to extract principle palm lines from an image of a person's hand. Our method applies deep learning networks (DNNs) to improve performance. Another challenge of this problem is the lack of training data. To deal with this issue, we handcrafted a dataset from scratch. From this dataset, we compare the performance of readily available methods with ours. Furthermore, based on the UNet segmentation neural network architecture and the knowledge of attention mechanism, we propose a highly efficient architecture to detect palm-lines. We proposed the Context Fusion Module to capture the most important context feature, which aims to improve segmentation accuracy. The experimental results show that it outperforms the other methods with the highest F1 Score about 99.42% and mIoU is 0.584 for the same dataset.
* Published in 2020 International Conference on Advanced Computing and Applications (ACOMP)
Deep Learning Approach for Singer Voice Classification of Vietnamese Popular Music
Feb 24, 2021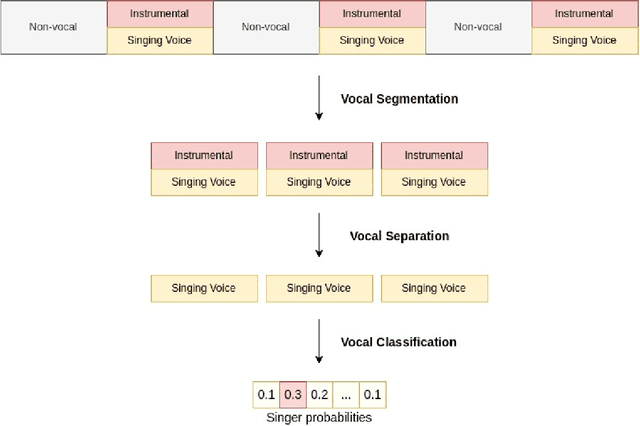
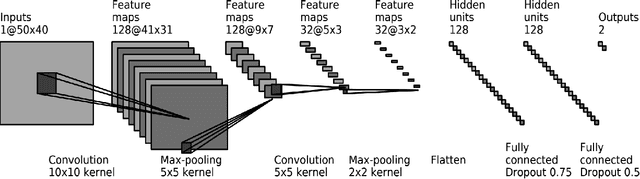

Singer voice classification is a meaningful task in the digital era. With a huge number of songs today, identifying a singer is very helpful for music information retrieval, music properties indexing, and so on. In this paper, we propose a new method to identify the singer's name based on analysis of Vietnamese popular music. We employ the use of vocal segment detection and singing voice separation as the pre-processing steps. The purpose of these steps is to extract the singer's voice from the mixture sound. In order to build a singer classifier, we propose a neural network architecture working with Mel Frequency Cepstral Coefficient as extracted input features from said vocal. To verify the accuracy of our methods, we evaluate on a dataset of 300 Vietnamese songs from 18 famous singers. We achieve an accuracy of 92.84% with 5-fold stratified cross-validation, the best result compared to other methods on the same data set.
* Published in SoICT 2019: Proceedings of the Tenth International Symposium on Information and Communication Technology