 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Contrastive Learning With Theory Guarantee
Paper and Code
Nov 16, 2023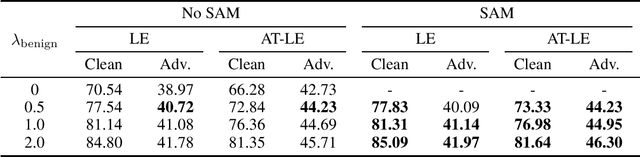

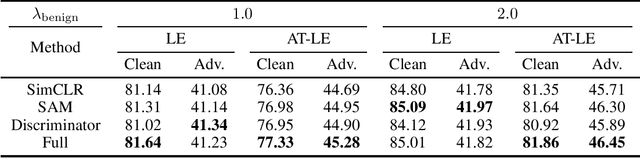
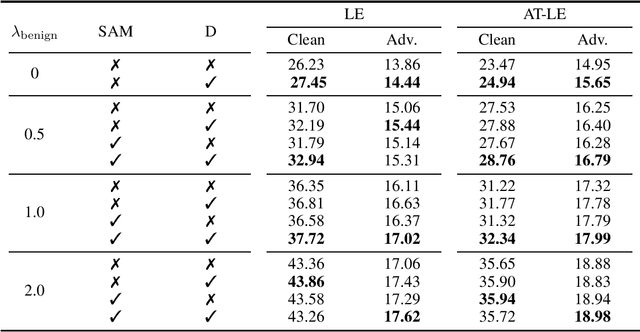
Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.