 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Critique Mechanism in Large Reasoning Models
Mar 17, 2026Large Reasoning Models (LRMs) exhibit backtracking and self-verification mechanisms that enable them to revise intermediate steps and reach correct solutions, yielding strong performance on complex logical benchmarks. We hypothesize that such behaviors are beneficial only when the model has sufficiently strong "critique" ability to detect its own mistakes. This work systematically investigates how current LRMs recover from errors by inserting arithmetic mistakes in their intermediate reasoning steps. Notably, we discover a peculiar yet important phenomenon: despite the error propagating through the chain-of-thought (CoT), resulting in an incorrect intermediate conclusion, the model still reaches the correct final answer. This recovery implies that the model must possess an internal mechanism to detect errors and trigger self-correction, which we refer to as the hidden critique ability. Building on feature space analysis, we identify a highly interpretable critique vector representing this behavior. Extensive experiments across multiple model scales and families demonstrate that steering latent representations with this vector improves the model's error detection capability and enhances the performance of test-time scaling at no extra training cost. Our findings provide a valuable understanding of LRMs' critique behavior, suggesting a promising direction to control and improve their self-verification mechanism. Our code is available at https://github.com/mail-research/lrm-critique-vectors.
Preserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
Personalized Large Vision-Language Models
Dec 23, 2024



The personalization model has gained significant attention in image generation yet remains underexplored for large vision-language models (LVLMs). Beyond generic ones, with personalization, LVLMs handle interactive dialogues using referential concepts (e.g., ``Mike and Susan are talking.'') instead of the generic form (e.g., ``a boy and a girl are talking.''), making the conversation more customizable and referentially friendly. In addition, PLVM is equipped to continuously add new concepts during a dialogue without incurring additional costs, which significantly enhances the practicality. PLVM proposes Aligner, a pre-trained visual encoder to align referential concepts with the queried images. During the dialogues, it extracts features of reference images with these corresponding concepts and recognizes them in the queried image, enabling personalization. We note that the computational cost and parameter count of the Aligner are negligible within the entire framework. With comprehensive qualitative and quantitative analyses, we reveal the effectiveness and superiority of PLVM.
Unveiling Concept Attribution in Diffusion Models
Dec 03, 2024



Diffusion models have shown remarkable abilities in generating realistic and high-quality images from text prompts. However, a trained model remains black-box; little do we know about the role of its components in exhibiting a concept such as objects or styles. Recent works employ causal tracing to localize layers storing knowledge in generative models without showing how those layers contribute to the target concept. In this work, we approach the model interpretability problem from a more general perspective and pose a question: \textit{``How do model components work jointly to demonstrate knowledge?''}. We adapt component attribution to decompose diffusion models, unveiling how a component contributes to a concept. Our framework allows effective model editing, in particular, we can erase a concept from diffusion models by removing positive components while remaining knowledge of other concepts. Surprisingly, we also show there exist components that contribute negatively to a concept, which has not been discovered in the knowledge localization approach. Experimental results confirm the role of positive and negative components pinpointed by our framework, depicting a complete view of interpreting generative models. Our code is available at \url{https://github.com/mail-research/CAD-attribution4diffusion}
DiMSUM: Diffusion Mamba -- A Scalable and Unified Spatial-Frequency Method for Image Generation
Nov 06, 2024



We introduce a novel state-space architecture for diffusion models, effectively harnessing spatial and frequency information to enhance the inductive bias towards local features in input images for image generation tasks. While state-space networks, including Mamba, a revolutionary advancement in recurrent neural networks, typically scan input sequences from left to right, they face difficulties in designing effective scanning strategies, especially in the processing of image data. Our method demonstrates that integrating wavelet transformation into Mamba enhances the local structure awareness of visual inputs and better captures long-range relations of frequencies by disentangling them into wavelet subbands, representing both low- and high-frequency components. These wavelet-based outputs are then processed and seamlessly fused with the original Mamba outputs through a cross-attention fusion layer, combining both spatial and frequency information to optimize the order awareness of state-space models which is essential for the details and overall quality of image generation. Besides, we introduce a globally-shared transformer to supercharge the performance of Mamba, harnessing its exceptional power to capture global relationships. Through extensive experiments on standard benchmarks, our method demonstrates superior results compared to DiT and DIFFUSSM, achieving faster training convergence and delivering high-quality outputs. The codes and pretrained models are released at https://github.com/VinAIResearch/DiMSUM.git.
Sketchy Moment Matching: Toward Fast and Provable Data Selection for Finetuning
Jul 08, 2024We revisit data selection in a modern context of finetuning from a fundamental perspective. Extending the classical wisdom of variance minimization in low dimensions to high-dimensional finetuning, our generalization analysis unveils the importance of additionally reducing bias induced by low-rank approximation. Inspired by the variance-bias tradeoff in high dimensions from the theory, we introduce Sketchy Moment Matching (SkMM), a scalable data selection scheme with two stages. (i) First, the bias is controlled using gradient sketching that explores the finetuning parameter space for an informative low-dimensional subspace $\mathcal{S}$; (ii) then the variance is reduced over $\mathcal{S}$ via moment matching between the original and selected datasets. Theoretically, we show that gradient sketching is fast and provably accurate: selecting $n$ samples by reducing variance over $\mathcal{S}$ preserves the fast-rate generalization $O(\dim(\mathcal{S})/n)$, independent of the parameter dimension. Empirically, we concretize the variance-bias balance via synthetic experiments and demonstrate the effectiveness of SkMM for finetuning in real vision tasks.
Enhancing Domain Adaptation through Prompt Gradient Alignment
Jun 13, 2024Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other prompt-based baselines by a large margin on different UDA benchmarks
Controllable Prompt Tuning For Balancing Group Distributional Robustness
Mar 05, 2024Models trained on data composed of different groups or domains can suffer from severe performance degradation under distribution shifts. While recent methods have largely focused on optimizing the worst-group objective, this often comes at the expense of good performance on other groups. To address this problem, we introduce an optimization scheme to achieve good performance across groups and find a good solution for all without severely sacrificing performance on any of them. However, directly applying such optimization involves updating the parameters of the entire network, making it both computationally expensive and challenging. Thus, we introduce Controllable Prompt Tuning (CPT), which couples our approach with prompt-tuning techniques. On spurious correlation benchmarks, our procedures achieve state-of-the-art results across both transformer and non-transformer architectures, as well as unimodal and multimodal data, while requiring only 0.4% tunable parameters.
Robust Contrastive Learning With Theory Guarantee
Nov 16, 2023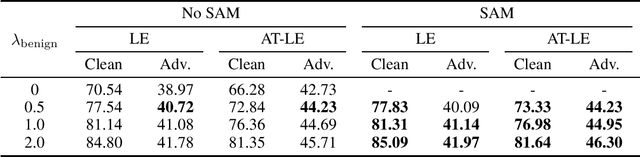

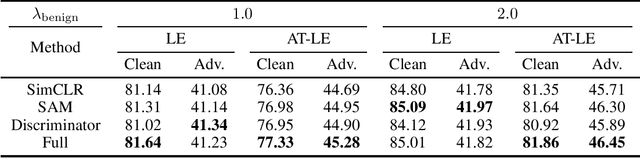
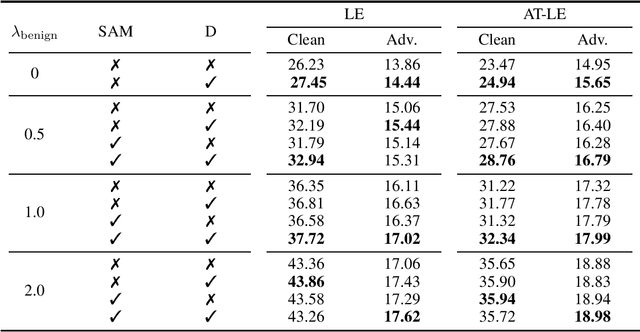
Contrastive learning (CL) is a self-supervised training paradigm that allows us to extract meaningful features without any label information. A typical CL framework is divided into two phases, where it first tries to learn the features from unlabelled data, and then uses those features to train a linear classifier with the labeled data. While a fair amount of existing theoretical works have analyzed how the unsupervised loss in the first phase can support the supervised loss in the second phase, none has examined the connection between the unsupervised loss and the robust supervised loss, which can shed light on how to construct an effective unsupervised loss for the first phase of CL. To fill this gap, our work develops rigorous theories to dissect and identify which components in the unsupervised loss can help improve the robust supervised loss and conduct proper experiments to verify our findings.
Full High-Dimensional Intelligible Learning In 2-D Lossless Visualization Space
May 29, 2023This study explores a new methodology for machine learning classification tasks in 2-dimensional visualization space (2-D ML) using Visual knowledge Discovery in lossless General Line Coordinates. It is shown that this is a full machine learning approach that does not require processing n-dimensional data in an abstract n-dimensional space. It enables discovering n-D patterns in 2-D space without loss of n-D information using graph representations of n-D data in 2-D. Specifically, this study shows that it can be done with static and dynamic In-line Based Coordinates in different modifications, which are a category of General Line Coordinates. Based on these inline coordinates, classification and regression methods were developed. The viability of the strategy was shown by two case studies based on benchmark datasets (Wisconsin Breast Cancer and Page Block Classification datasets). The characteristics of page block classification data led to the development of an algorithm for imbalanced high-resolution data with multiple classes, which exploits the decision trees as a model design facilitator producing a model, which is more general than a decision tree. This work accelerates the ongoing consolidation of an emerging field of full 2-D machine learning and its methodology. Within this methodology the end users can discover models and justify them as self-service. Providing interpretable ML models is another benefit of this approach.