 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoder-Decoder Diffusion Language Models for Efficient Training and Inference
Oct 26, 2025Discrete diffusion models enable parallel token sampling for faster inference than autoregressive approaches. However, prior diffusion models use a decoder-only architecture, which requires sampling algorithms that invoke the full network at every denoising step and incur high computational cost. Our key insight is that discrete diffusion models perform two types of computation: 1) representing clean tokens and 2) denoising corrupted tokens, which enables us to use separate modules for each task. We propose an encoder-decoder architecture to accelerate discrete diffusion inference, which relies on an encoder to represent clean tokens and a lightweight decoder to iteratively refine a noised sequence. We also show that this architecture enables faster training of block diffusion models, which partition sequences into blocks for better quality and are commonly used in diffusion language model inference. We introduce a framework for Efficient Encoder-Decoder Diffusion (E2D2), consisting of an architecture with specialized training and sampling algorithms, and we show that E2D2 achieves superior trade-offs between generation quality and inference throughput on summarization, translation, and mathematical reasoning tasks. We provide the code, model weights, and blog post on the project page: https://m-arriola.com/e2d2
Self-Corrected Flow Distillation for Consistent One-Step and Few-Step Text-to-Image Generation
Dec 22, 2024



Flow matching has emerged as a promising framework for training generative models, demonstrating impressive empirical performance while offering relative ease of training compared to diffusion-based models. However, this method still requires numerous function evaluations in the sampling process. To address these limitations, we introduce a self-corrected flow distillation method that effectively integrates consistency models and adversarial training within the flow-matching framework. This work is a pioneer in achieving consistent generation quality in both few-step and one-step sampling. Our extensive experiments validate the effectiveness of our method, yielding superior results both quantitatively and qualitatively on CelebA-HQ and zero-shot benchmarks on the COCO dataset. Our implementation is released at https://github.com/VinAIResearch/SCFlow
Simple Guidance Mechanisms for Discrete Diffusion Models
Dec 13, 2024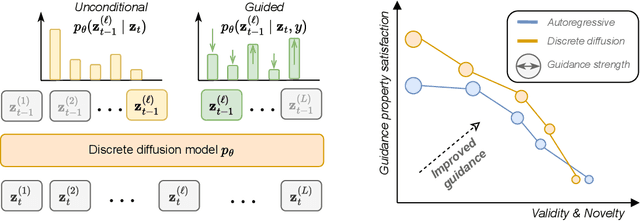
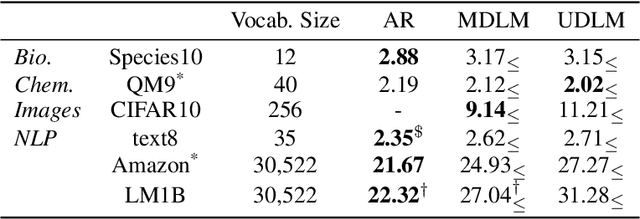
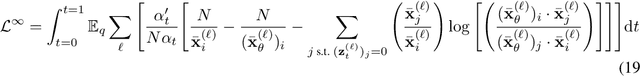
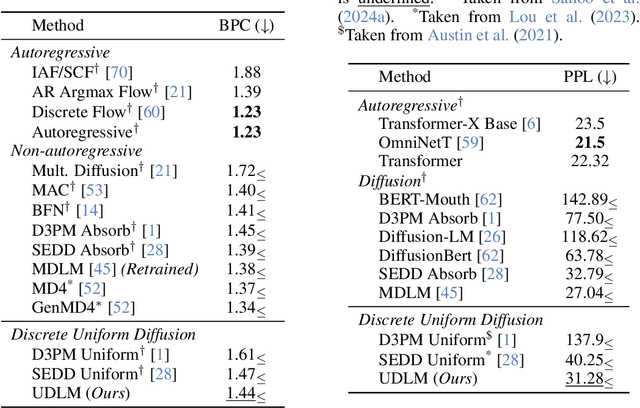
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
DiMSUM: Diffusion Mamba -- A Scalable and Unified Spatial-Frequency Method for Image Generation
Nov 06, 2024



We introduce a novel state-space architecture for diffusion models, effectively harnessing spatial and frequency information to enhance the inductive bias towards local features in input images for image generation tasks. While state-space networks, including Mamba, a revolutionary advancement in recurrent neural networks, typically scan input sequences from left to right, they face difficulties in designing effective scanning strategies, especially in the processing of image data. Our method demonstrates that integrating wavelet transformation into Mamba enhances the local structure awareness of visual inputs and better captures long-range relations of frequencies by disentangling them into wavelet subbands, representing both low- and high-frequency components. These wavelet-based outputs are then processed and seamlessly fused with the original Mamba outputs through a cross-attention fusion layer, combining both spatial and frequency information to optimize the order awareness of state-space models which is essential for the details and overall quality of image generation. Besides, we introduce a globally-shared transformer to supercharge the performance of Mamba, harnessing its exceptional power to capture global relationships. Through extensive experiments on standard benchmarks, our method demonstrates superior results compared to DiT and DIFFUSSM, achieving faster training convergence and delivering high-quality outputs. The codes and pretrained models are released at https://github.com/VinAIResearch/DiMSUM.git.
Flow Matching in Latent Space
Jul 17, 2023Flow matching is a recent framework to train generative models that exhibits impressive empirical performance while being relatively easier to train compared with diffusion-based models. Despite its advantageous properties, prior methods still face the challenges of expensive computing and a large number of function evaluations of off-the-shelf solvers in the pixel space. Furthermore, although latent-based generative methods have shown great success in recent years, this particular model type remains underexplored in this area. In this work, we propose to apply flow matching in the latent spaces of pretrained autoencoders, which offers improved computational efficiency and scalability for high-resolution image synthesis. This enables flow-matching training on constrained computational resources while maintaining their quality and flexibility. Additionally, our work stands as a pioneering contribution in the integration of various conditions into flow matching for conditional generation tasks, including label-conditioned image generation, image inpainting, and semantic-to-image generation. Through extensive experiments, our approach demonstrates its effectiveness in both quantitative and qualitative results on various datasets, such as CelebA-HQ, FFHQ, LSUN Church & Bedroom, and ImageNet. We also provide a theoretical control of the Wasserstein-2 distance between the reconstructed latent flow distribution and true data distribution, showing it is upper-bounded by the latent flow matching objective. Our code will be available at https://github.com/VinAIResearch/LFM.git.
Anti-DreamBooth: Protecting users from personalized text-to-image synthesis
Mar 27, 2023Text-to-image diffusion models are nothing but a revolution, allowing anyone, even without design skills, to create realistic images from simple text inputs. With powerful personalization tools like DreamBooth, they can generate images of a specific person just by learning from his/her few reference images. However, when misused, such a powerful and convenient tool can produce fake news or disturbing content targeting any individual victim, posing a severe negative social impact. In this paper, we explore a defense system called Anti-DreamBooth against such malicious use of DreamBooth. The system aims to add subtle noise perturbation to each user's image before publishing in order to disrupt the generation quality of any DreamBooth model trained on these perturbed images. We investigate a wide range of algorithms for perturbation optimization and extensively evaluate them on two facial datasets over various text-to-image model versions. Despite the complicated formulation of DreamBooth and Diffusion-based text-to-image models, our methods effectively defend users from the malicious use of those models. Their effectiveness withstands even adverse conditions, such as model or prompt/term mismatching between training and testing. Our code will be available at \href{https://github.com/VinAIResearch/Anti-DreamBooth.git}{https://github.com/VinAIResearch/Anti-DreamBooth.git}.
Wavelet Diffusion Models are fast and scalable Image Generators
Nov 29, 2022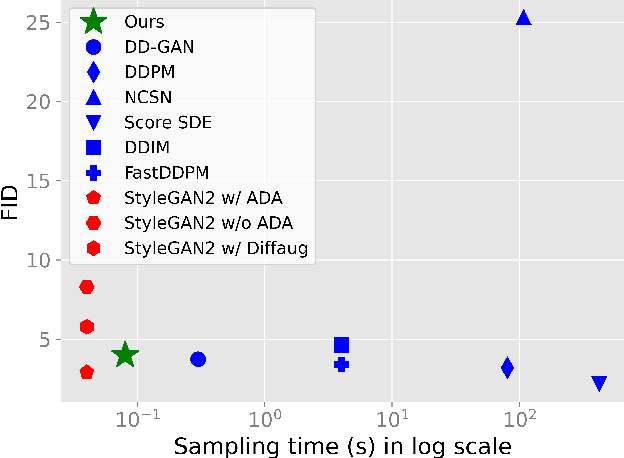
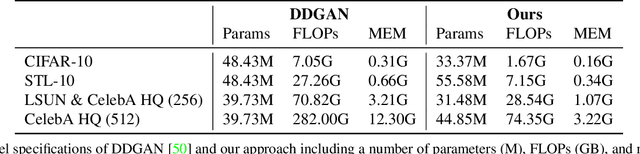
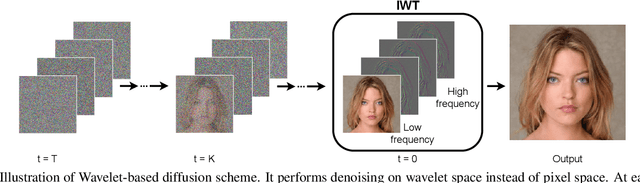
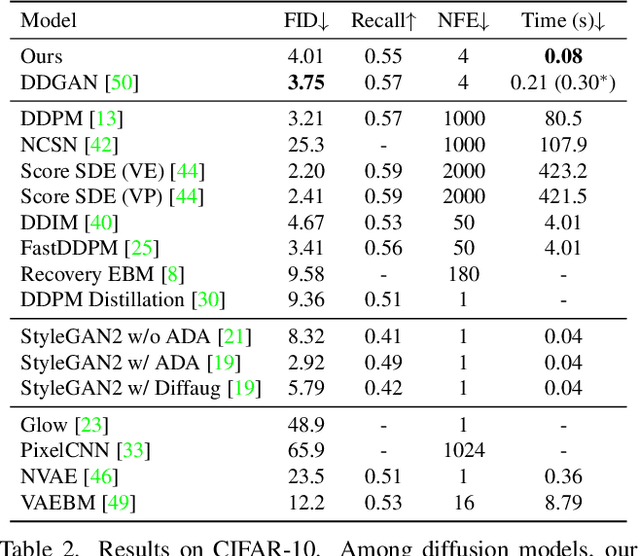
Diffusion models are rising as a powerful solution for high-fidelity image generation, which exceeds GANs in quality in many circumstances. However, their slow training and inference speed is a huge bottleneck, blocking them from being used in real-time applications. A recent DiffusionGAN method significantly decreases the models' running time by reducing the number of sampling steps from thousands to several, but their speeds still largely lag behind the GAN counterparts. This paper aims to reduce the speed gap by proposing a novel wavelet-based diffusion structure. We extract low-and-high frequency components from both image and feature levels via wavelet decomposition and adaptively handle these components for faster processing while maintaining good generation quality. Furthermore, we propose to use a reconstruction term, which effectively boosts the model training convergence. Experimental results on CelebA-HQ, CIFAR-10, LSUN-Church, and STL-10 datasets prove our solution is a stepping-stone to offering real-time and high-fidelity diffusion models. Our code and pre-trained checkpoints will be available at \url{https://github.com/VinAIResearch/WaveDiff.git}.